考慮以下的需求:你有一個中文寫的純文字檔,裡頭是一篇中文的文章。基於某種理由,需要將文章裡的『如果』取代英文的 if 。很多人可能覺得,這還不簡單,字串取代就可以了。
然而,一旦當那篇中文的文章裡有一句亂來的句子:
牛奶不如果汁好喝。
前述 Naive 字串取代就會出錯。
要怎麼開發程式,才能避免程式受到上述這種亂來的句子的影響呢?
;; 如果下雨,我就不去了。
S(句子)
├── CP(條件從句)
│ ├── C(連詞):如果
│ └── S(句子)
│ └── VP(動詞短語)
│ └── V(動詞):下雨
└── S(主句)
├── NP(名詞短語):我
├── Adv(副詞):就
├── Neg(否定詞):不
├── VP(動詞短語)
│ └── V(動詞):去
└── Part(語氣助詞):了
程式語言也一樣可以做語法樹解析。而實際上,現代的編輯器的進階功能:語法高亮度、自動格式化、以及跳轉定義。這些能力背後的基石,也都是程式語言的語法樹解析。
在 day24 我們提到了要使用 Tree-sitter 來解析程式碼,這就衍生了兩個主要的挑戰:
第一個生成語法樹問題,其實是最難的,因為我們必須提供 Tree-sitter 一個 grammar.js ,裡頭要寫好 Fennel 語言的文法規則 (Grammar Rules) 。然而,幸運的是,Tree-sitter 官網上,許多冷門程式語言的文法規則早就存在了!
於是,可以得到下圖,下圖的左側就是 Tree-sitter 的輸出。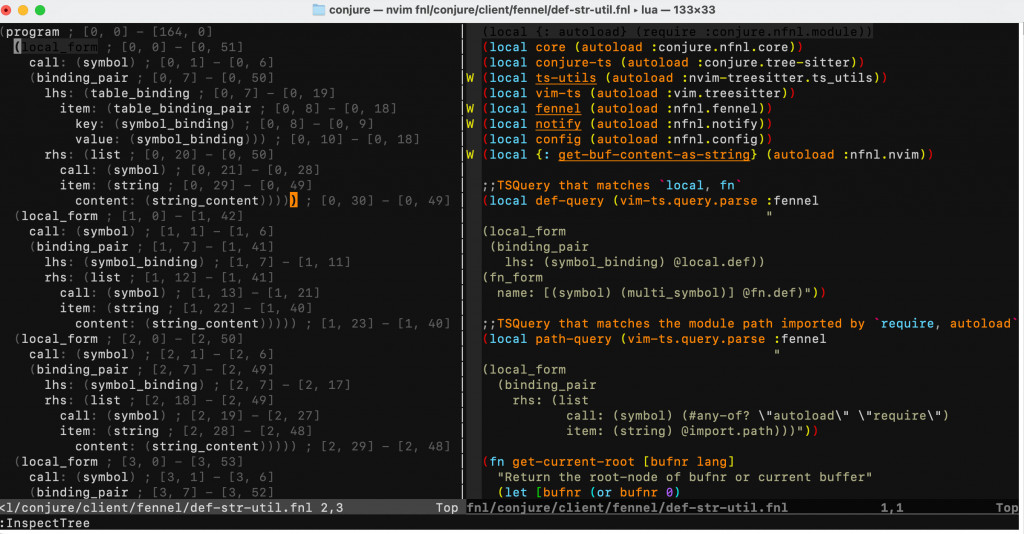
查詢的問題,則可以善用 Neovim 的兩個 Ex 指令:
在 EditQuery 的視窗裡,輸入 Tree-sitter 查詢之後,比對成功的原始碼與語法樹區段就會自動反白,幫助你用肉眼確認,是否你的意圖與查詢的結果一致。Tree-sitter 的查詢語法,我到今天為止也沒有學會,我直接叫 LLM 幫我生成而已。
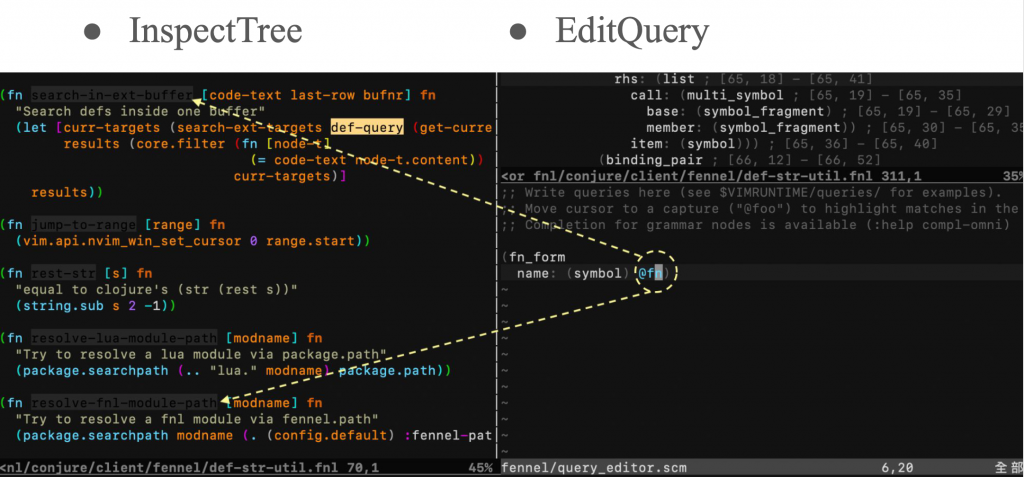
自然語言和程式碼本身就是帶有隱性結構的資料,透過基於語法解析產生的語法樹,我們就能像應用資料庫一樣,以精準的方式來理解、查詢、操作其資料。


 iThome鐵人賽
iThome鐵人賽