嗨嗨大家~ 不知道大家昨天有沒有自己玩了一下文字雲,應該挺有趣的吧☺️
其實最主要希望大家快熟悉一下在做自然語言處理的時候前面的流程,那大家還記得在資料處理完後的下一步我們就會來訓練模型,在還沒說到深度學習模型前,我們要先介紹最基礎、最基本的傳統機器學習模型!
今天會介紹的是Support Vector Machine (SVM) 並帶大家稍稍實作一下~
其實就是一個很常用來做分類的模型,像是可以用在做二元分類(例如「正面評論 / 負面評論」、「垃圾信 / 非垃圾信」)也可以作多分類任務,但相對比較複雜,所以我們今天就介紹二元分類就好~
那他的運作原理最主要是會在一堆資料點中,畫出一條「最能分開兩類」的線,
且讓這條線距離兩邊最近的點盡量遠越好。
這邊給個圖讓大家比較好理解,假設你的資料長得像下圖那樣,有不同顏色、形狀的點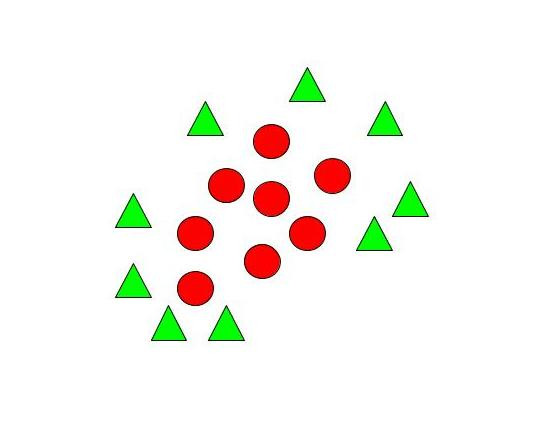
這時候用SVM 來分這些資料的話,他可能會這樣做切分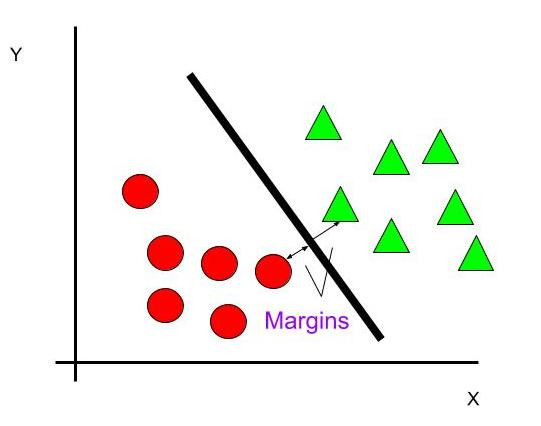
我們今天不會深入探討它裡面到底是怎麼運作的,大家只要記得他是用來做分類任務就好啦!
那我們前面做的資料預處理其實就是希望資料可以乾淨一點,讓模型在訓練的時候可以不要被不必要的資訊干擾,讓模型可以在資料中找到規律,讓訓練更順利一些~
那我們就直接來看一下如何訓練自己的SVM 分類模型吧!
首先第一步就是安裝必要的套件,我們這次使用的是sklearn 套件來幫忙
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn import svm
再來把你的資料讀進來,今天我們會用這份學生的資訊來做練習:練習資料
大家也可以自己拿手邊的資料做練習喔!
df = pd.read_csv('/Users/xxuan/Downloads/student.csv', sep = ',')
我們今天就做一個最簡單的,根據學生就讀的高中類型、年齡、每週閱讀時間這些特徵來預測這位學生是男是女!(好沒邏輯xd)
好噠~那在讀完檔之後我首先可以看一下資料
df.head()
你會發現在看到High_School_Type裡面的資料型態其實不是數值,我們的電腦其實不太聰明,我們會需要把資料轉換成數字這樣電腦才看得懂
所以再來這一步我們就先把不是數字的資料用 LabelEncoder()做轉換!
le = LabelEncoder()
df.High_School_Type = le.fit_transform(df['High_School_Type'])
df.head()
然後我們會需要告訴模型,High_School_Type,Weekly_Study_Hours和Student_Age當作是特徵,而Sex 是我們的目標答案
features = df[['High_School_Type', 'Weekly_Study_Hours', 'Student_Age']]
target = le.fit_transform(df['Sex'])
再來就是要切分測試集的特徵、測試集的答案&訓練集的特徵、訓練集的答案,並且將切分資料筆數切成8筆2,八成訓練二成用來做測試
feat_train, feat_test, target_train, target_test = train_test_split(features, target, test_size=0.2, random_state=0)
下一步我們要要設定一下要選用的模型
svm_model = svm.SVC(C=1, gamma='auto', kernel='rbf') # 設置模型
svm_model.fit(feat_train, target_train) #將訓練集的特徵、訓練集的答案都丟進模型
然後我們來讓他預測看看測試及的資料!
predicted = svm_model.predict(feat_test)
predicted_labels = le.inverse_transform(predicted) # 將數字轉回文字
print(predicted_labels)
可以看看輸出結果
['Male' 'Male' 'Female' 'Male' 'Male' 'Male' 'Male' 'Male' 'Female' 'Male'
'Male' 'Male' 'Male' 'Female' 'Male' 'Male' 'Male' 'Male' 'Male' 'Female'
'Male' 'Male' 'Female' 'Male' 'Male' 'Male' 'Male' 'Male' 'Male']
這裡輸出的每個 Male 或 Female 就是模型對測試集每一筆資料的性別預測!
好啦~~那這樣就完成SVM 的模型訓練拉!
還有很多模型可以用來做分類任務,我們之後也會再介紹其他的模型像是Decision Tree 等!
那至於要怎麼看模型表現好不好我們之後幾篇文章會在就介紹!今天就到這裡嚕


 iThome鐵人賽
iThome鐵人賽