嗨嗨大家~
昨天我們介紹了SVM 模型,主要運作原理是可以透過一條線將資料分類,我們也有說到,還有很多模型是可以來做分類任務的,所以今天我們就要繼續我們的模型之旅,來看看另一個蠻經典的模型行,那就是:決策樹(Decision Tree)!
那決策樹的原理主要是會根據資料的特徵來做一系列的條件判斷,最後把資料分類或做預測。
什麼意思呢?假設我們要用一棵決策樹來判斷「今天要不要帶傘」,他就會根據資料做出下面一系列的問題判斷,例如:
是否會下雨?
/ \
是 否
/ \
是否有大風? 不帶
/ \
是 否
帶傘 不帶
再經過一系列的判斷之後得出最後結果,而這一系列的判斷過程就形成了一個樹狀結構,因此被稱決策樹拉!
簡單來說他的運作過程會是
可以看出跟昨天的SVM 有蠻大差異的~ 那關於他是怎麼分群、挑選特徵的細節算法我們在這邊也先不提,大家有興趣可以再去深入研究!我們就直接進入實作吧
一樣我們會使用sklearn 套件來幫忙
先把必要的套件引入進來
from sklearn.preprocessing import LabelEncoder
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn import tree
import pandas as pd
資料的部分我們一樣沿用昨天的那份資料來做練習
df = pd.read_csv('/Users/xxuan/Downloads/student.csv', sep = ',')
df.head()
前面的步驟和昨天介紹的一樣,要轉換文字資料到數值,選出特徵及目標答案並且區分測試集以及訓練集的資料
#轉換換文字資料
le = LabelEncoder()
df.High_School_Type = le.fit_transform(df['High_School_Type'])
#挑選特徵及目標答案
features = df[['High_School_Type', 'Weekly_Study_Hours', 'Student_Age']]
target = le.fit_transform(df['Sex'])
#分出訓練集、測試集
feat_train, feat_test, target_train, target_test = train_test_split(features, target, test_size=0.2, random_state=0)
💡 為什麼要區分訓練集和測試集呢?
大家可以想像自己平常準備考試時,會做一大堆練習題。這些練習題就好比訓練集的資料;而真正的大考試題則相當於測試集的資料。如果我們把同一批題目同時拿來練習又拿來考試,分數一定會很好看,但這並不能代表你真的學會了,只是因為你「背答案」而已!
那訓練模型也是同理啦,訓練集是用來「教」模型,讓它學到資料中的規律,而測試集是用全新的資料來驗證模型的表現,看看它是否真的能推論、答對沒見過的資料(就是有沒有真的搞懂啦),只有透過測試集的資料我們才能知道模型是否真的具有泛化能力而不只是記住訓練時的資料而已!所以在模型訓練中,區分測試集根據練集的資料是非常重要的喔!
喔虧!再來我們就把decision tree 模型叫出來訓練
dtree = DecisionTreeClassifier(criterion = 'entropy')
dtree = dtree.fit(feat_train,target_train)
這樣就訓練完成惹 可以來模型預測的準確度
dtree.score(feat_test,target_test)
輸出結果
0.41379310344827586
哇勒,只有0.4的正確率XD
我們也可以來畫一張圖看看它內部是怎麼做決策的!
from IPython.display import Image
import pydot
from sklearn import tree
# 先把訓練好的決策樹模型輸出成 .dot 檔
tree.export_graphviz(
dtree, # 你的決策樹模型
out_file='/Users/xxuan/Downloads/tree.dot', # 輸出的 dot 檔路徑
feature_names=list(features), # 標註每個分裂的特徵名稱
class_names=['Female','Male'], # 標註分類名稱
filled=True, # 節點背景填色
)
# 用 pydot 讀取 .dot 檔並轉換成圖
(graph,) = pydot.graph_from_dot_file('/Users/xxuan/Downloads/tree.dot')
# 輸出成 PNG 圖片
graph.write_png('/Users/xxuan/Downloads/tree.png')
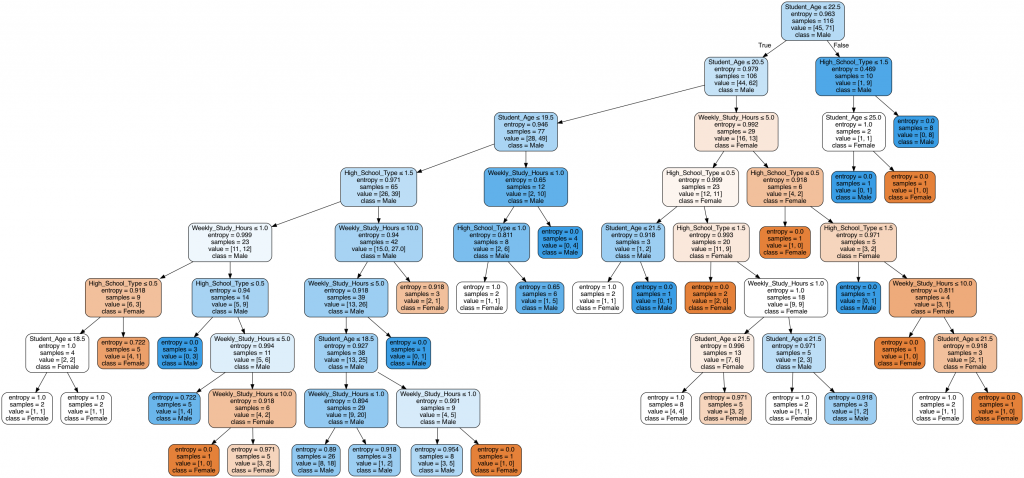
將將~你就可以看到複雜的決策過程惹!
那大家就自己去玩玩嚕~也可試試看比較兩個模型在這個資料表現上面,哪個比較好!!
那我們今天就先這裡嚕!掰噗


 iThome鐵人賽
iThome鐵人賽