在上一篇文章中,我們成功建立了一個 n8n 流程,能夠精準地從 Threads 貼文網址中抓取主貼文與作者的專屬回覆,並將其整理成乾淨的結構化 JSON 資料
我們已經有了最核心的「原料」,但若要讓這些備份資料更具價值、更易於管理與搜尋,我們還需要為它增添一些「佐料」
這篇文章,我們將說明如何串接 Google 強大的 Gemini AI 模型,讓 AI 自動為我們完成兩項關鍵任務:
生成精準標題:省去手動想標題的煩惱
萃取關鍵標籤 (Tags):讓資料分類與搜尋變得輕而易舉
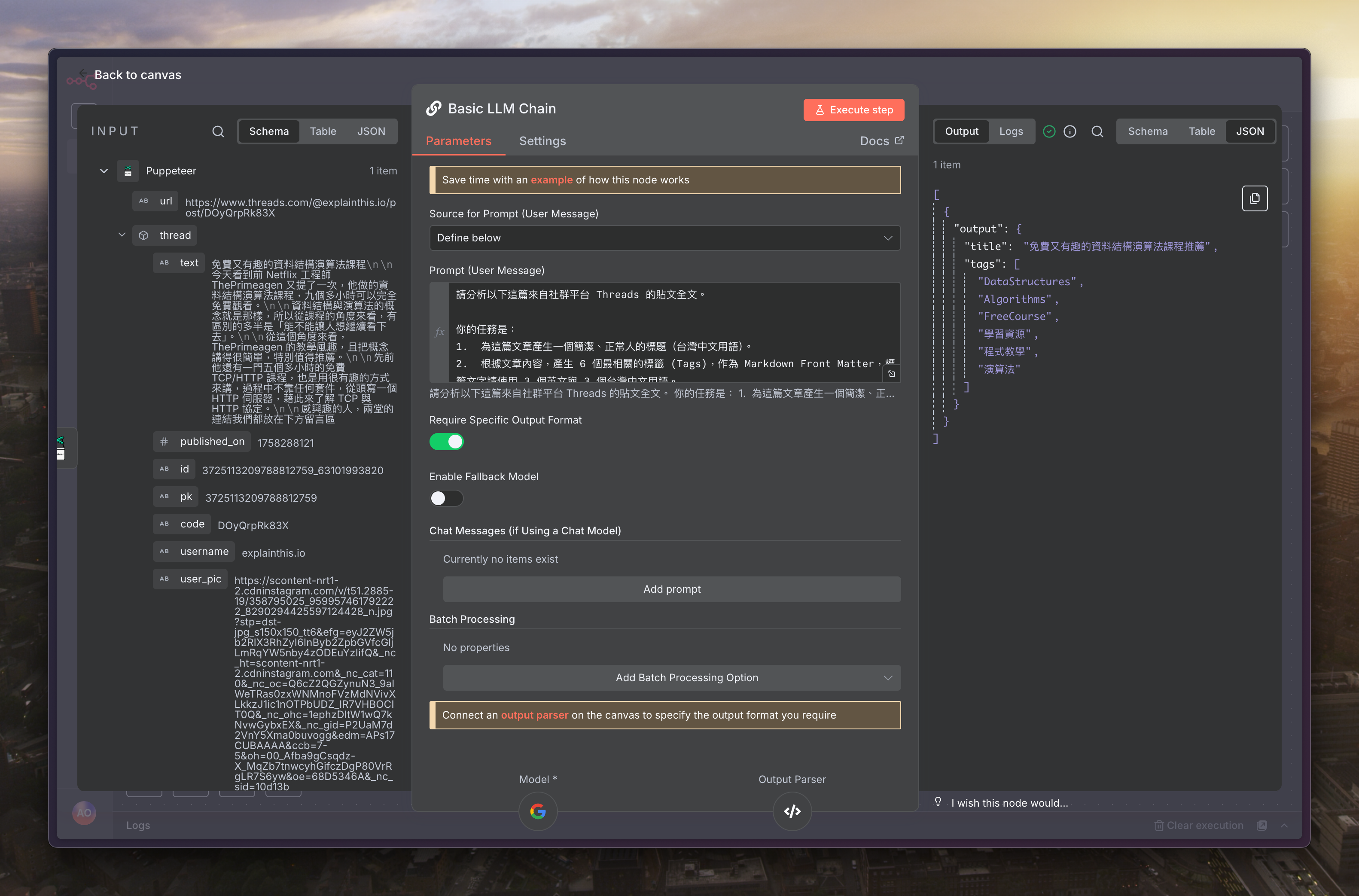
延續上一篇的下個節點,選擇「Basic LLM Chain」
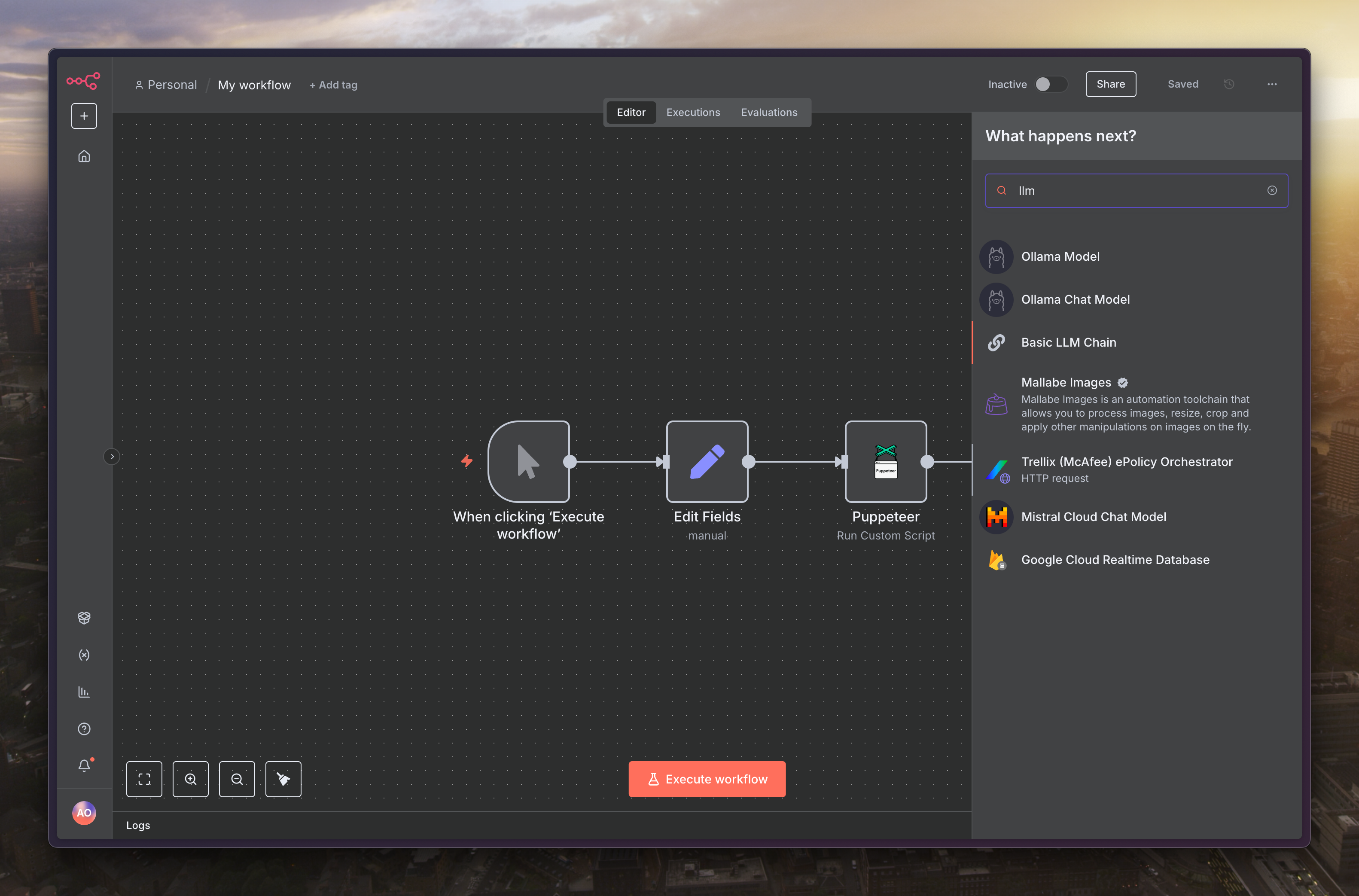
接著選擇「Define below」來撰寫提示
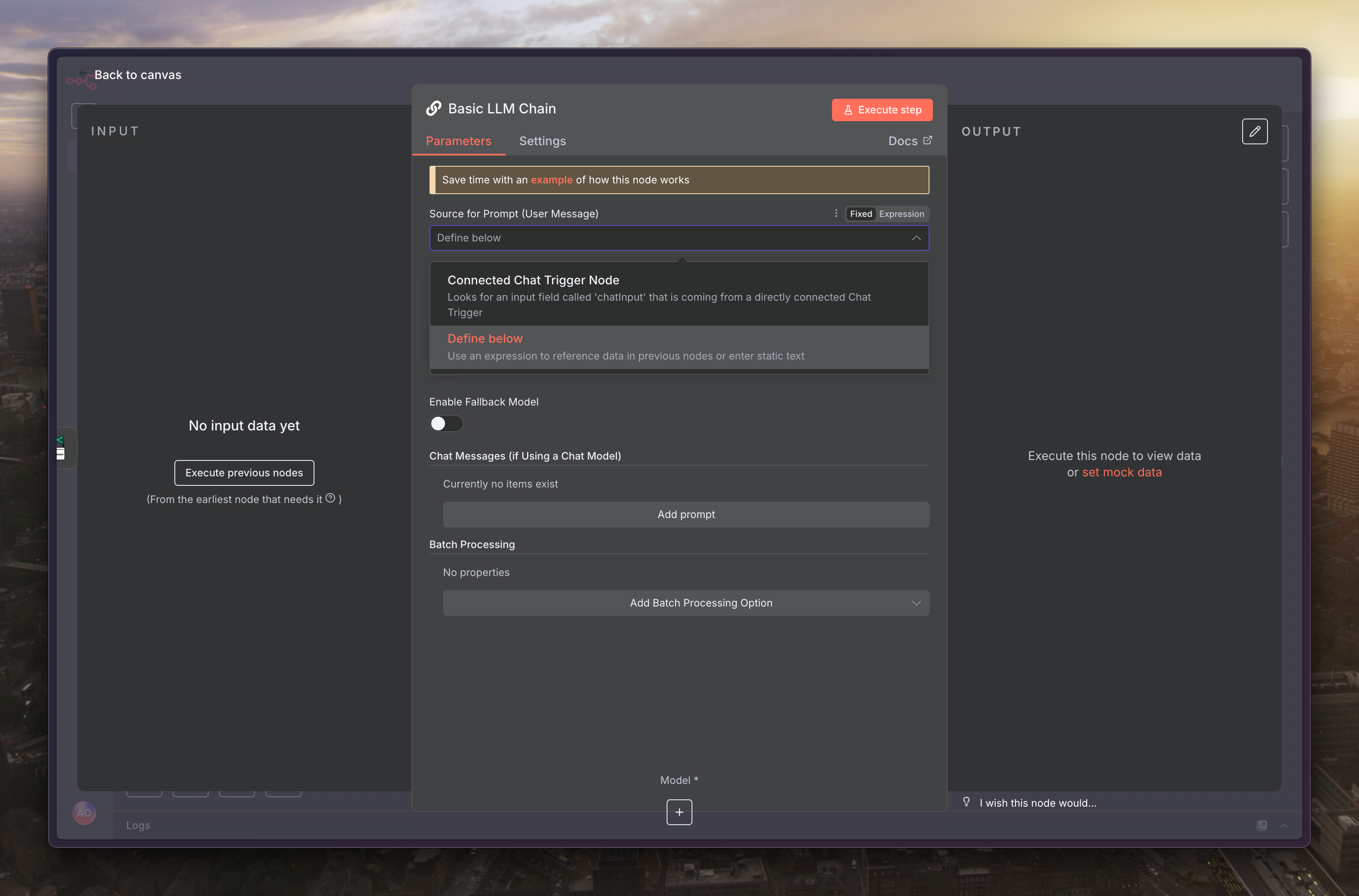
提示詞如下
請分析以下這篇來自社群平台 Threads 的貼文全文。
你的任務是:
1. 為這篇文章產生一個簡潔、正常人的標題(台灣中文用語)。
2. 根據文章內容,產生 6 個最相關的標籤 (Tags),作為 Markdown Front Matter,標籤文字請使用 3 個英文與 3 個台灣中文用語。
請**務必**將你的回答格式化為 1 個 JSON 物件,其中包含 "title" 和 "tags" (一個字串陣列) 兩個鍵值。不要在 JSON 物件前後增加任何多餘的文字或程式碼註解。
範例輸出格式:
{
"title": "這裡是你產出的標題",
"tags": ["標籤 1", "標籤 2", "標籤 3", "標籤 4", "標籤 5", "標籤 6"]
}
---
貼文全文如下:
{{ $json.thread.text }}
接著把「Require Specific Output Format」打開
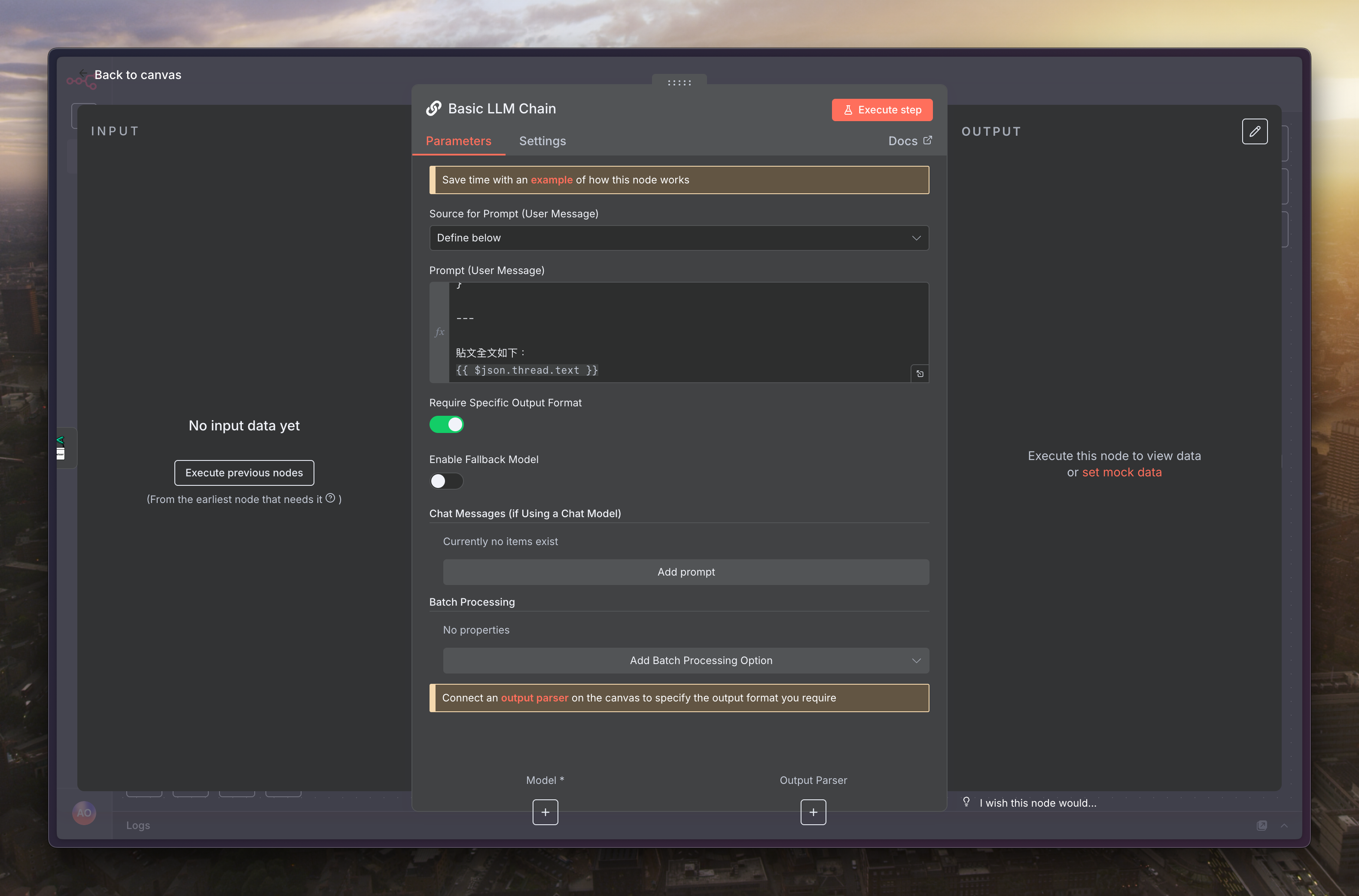
接著幫這個 LLM 設定模型,我是用 Gemini
接著在「Output Parsers」的地方選擇「Structured Output Parser」
JSON Example 填寫如下
{
"title": "這裡是你產出的標題",
"tags": ["標籤 1", "標籤 2", "標籤 3", "標籤 4", "標籤 5", "標籤 6"]
}
接著點選畫布下方的「Execute step」來試跑看看
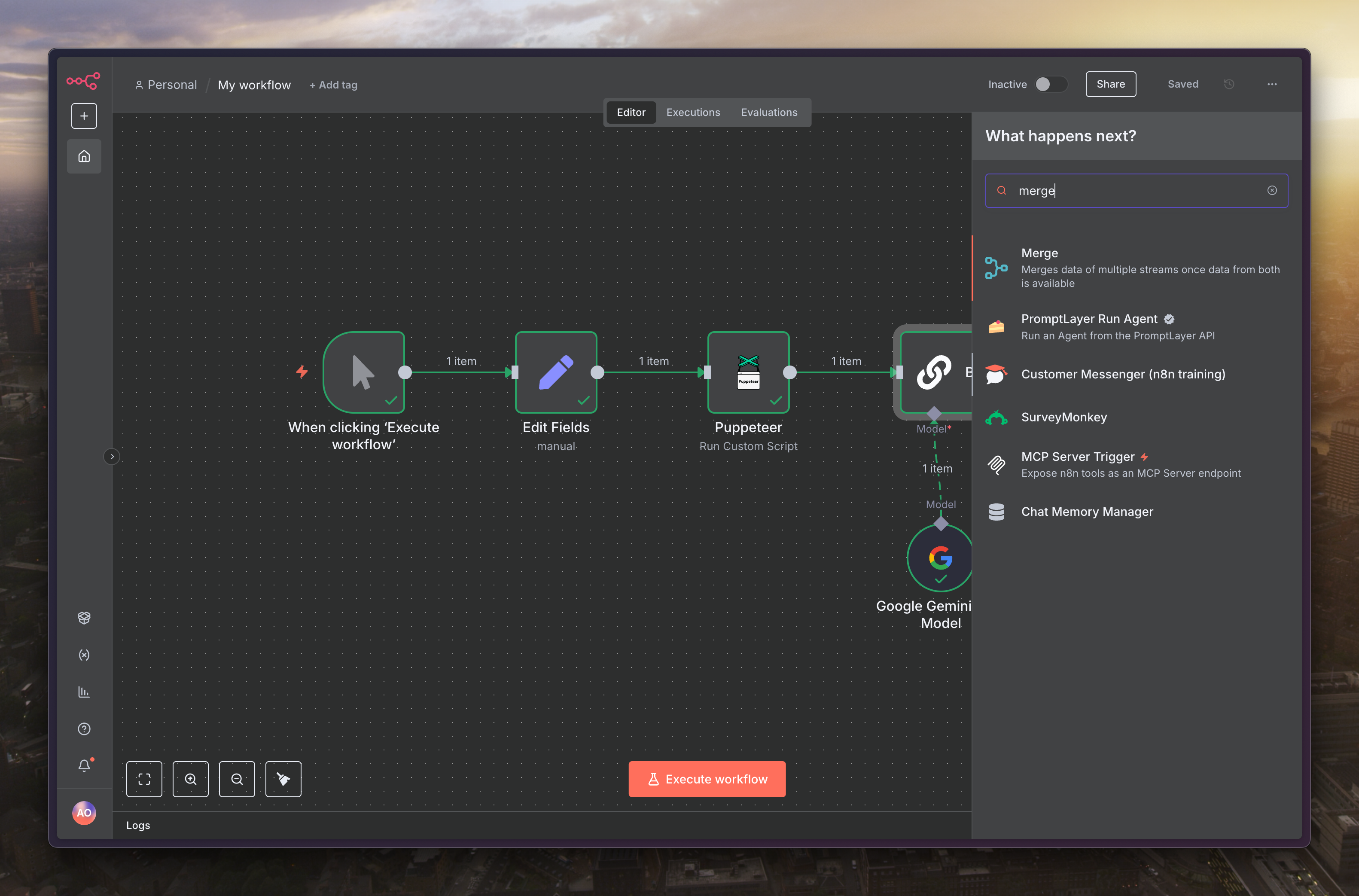
下個節點選擇「Merge」
內容選擇「Combine」、「Position」
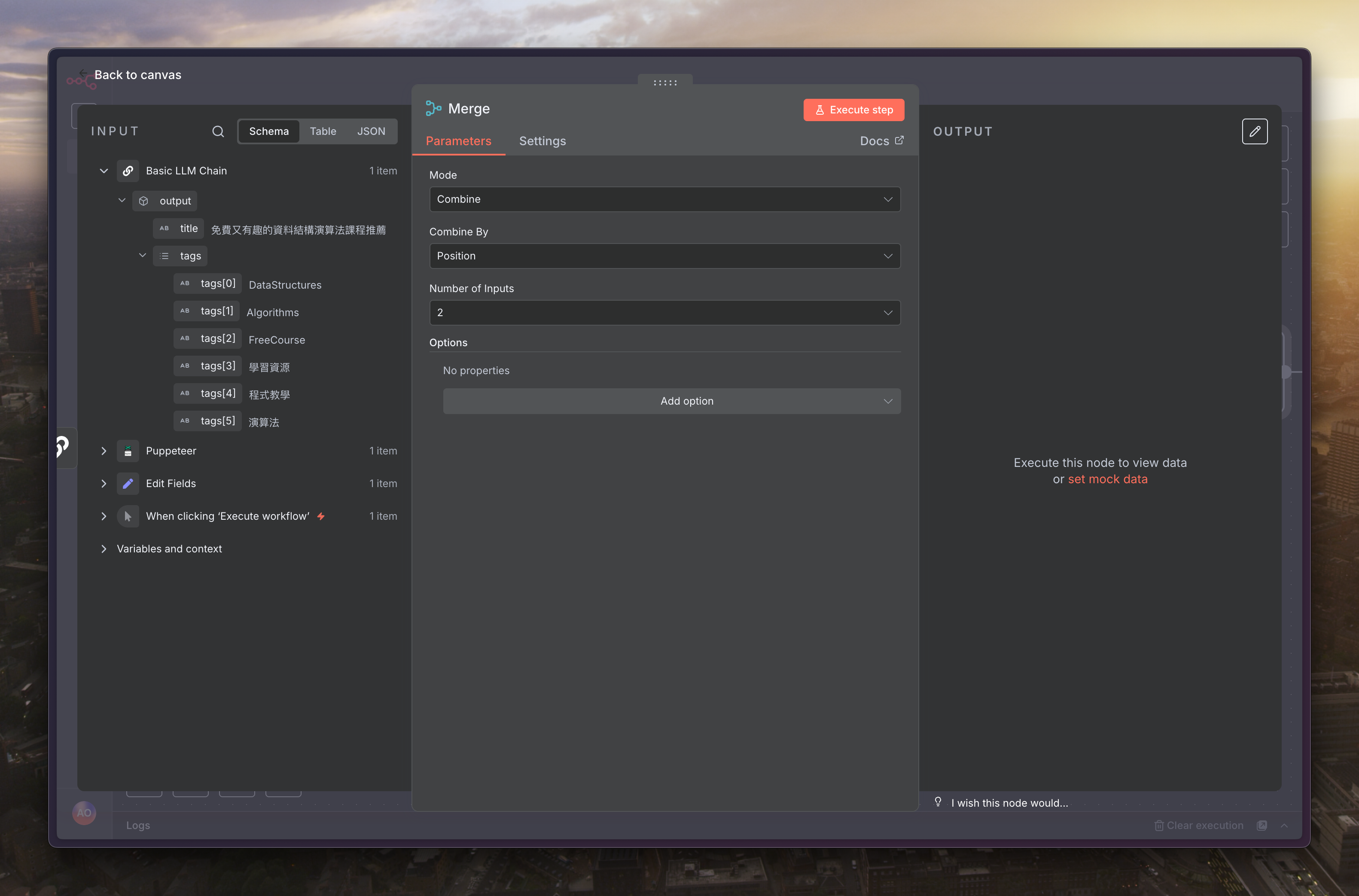
而 Merge 的另一個 input 選擇「Puppeteer」,這樣就可以把原始資料跟 AI 產生的內容合併起來
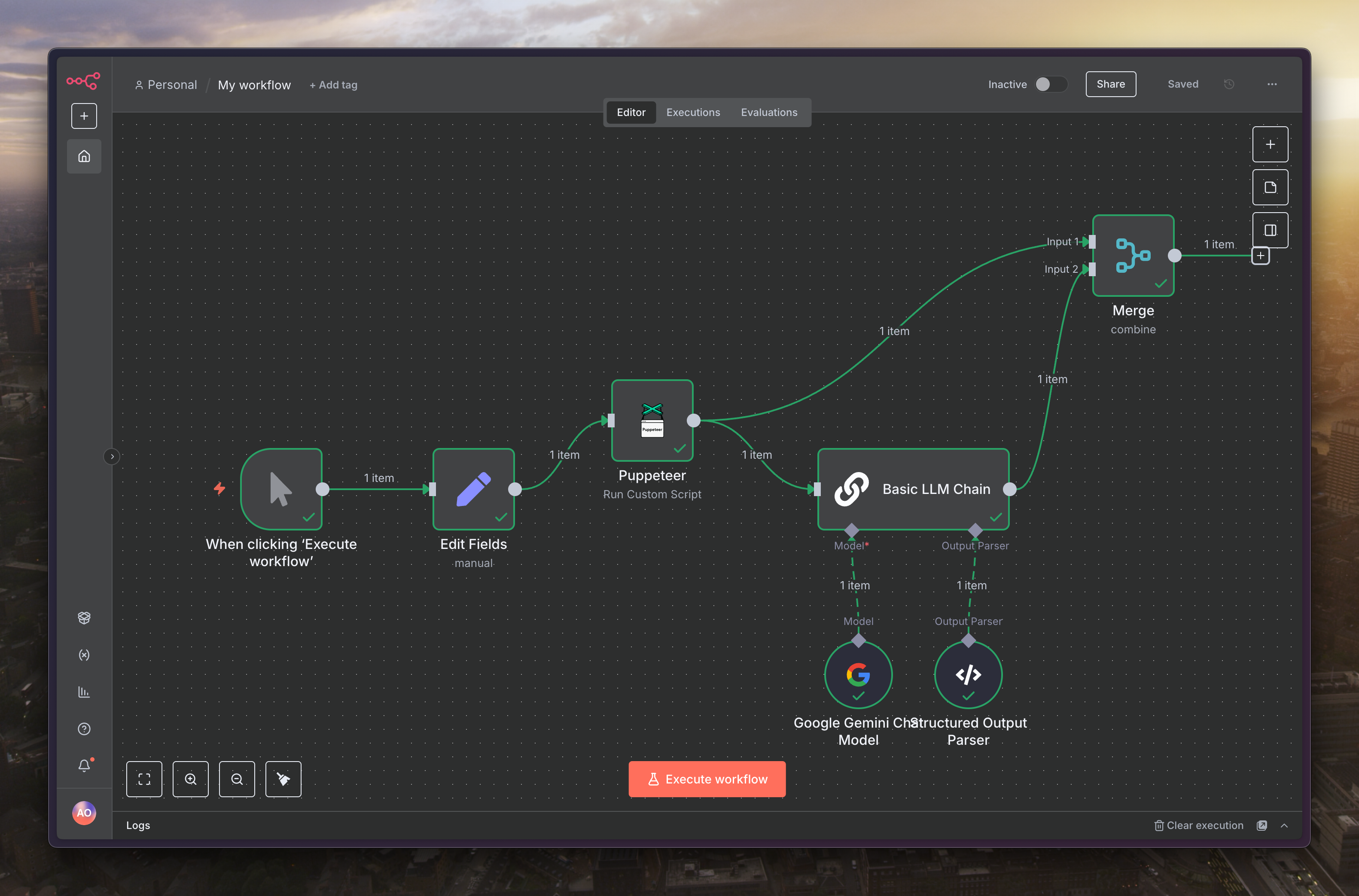
恭喜!現在我們的自動化流程已經升級,不僅能抓取貼文,更能透過 AI 自動產生標題與標籤
在下一篇文章中,我們將會說明如何將這些處理好的資料,轉換為 Markdown 檔案,並自動儲存到你的雲端硬碟


 iThome鐵人賽
iThome鐵人賽