在本篇文章中,我們將延續之前的設定,完成最關鍵的一步:將貼文資料轉換為實體的 Markdown、圖片和影片檔案
延續上一篇,下個節點同樣選擇「Puppeteer」的「Run Custom Script」
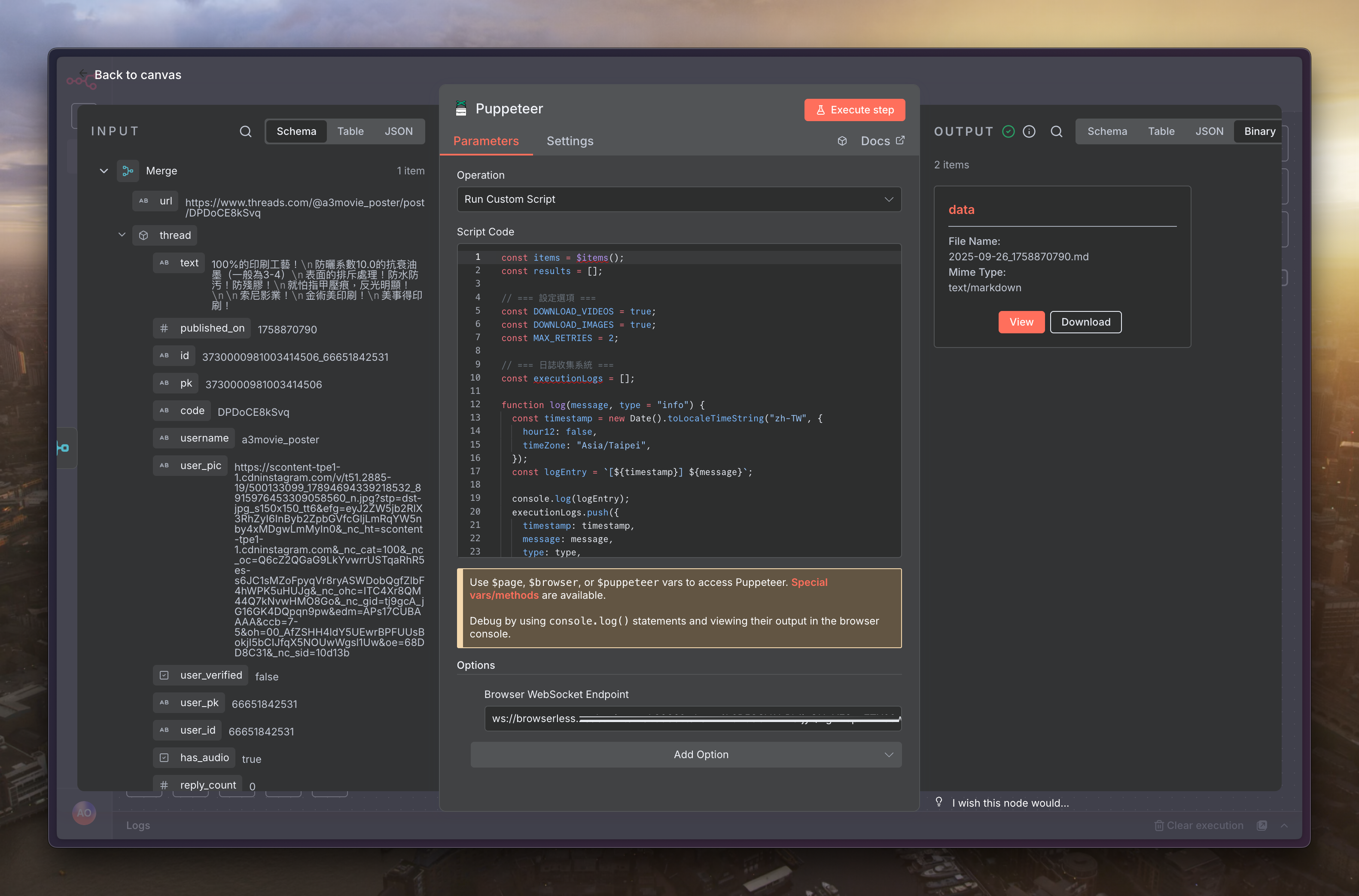
程式碼填寫如下
const items = $items();
const results = [];
// === 設定選項 ===
const DOWNLOAD_VIDEOS = true;
const DOWNLOAD_IMAGES = true;
const MAX_RETRIES = 2;
// === 日誌收集系統 ===
const executionLogs = [];
function log(message, type = "info") {
const timestamp = new Date().toLocaleTimeString("zh-TW", {
hour12: false,
timeZone: "Asia/Taipei",
});
const logEntry = `[${timestamp}] ${message}`;
console.log(logEntry);
executionLogs.push({
timestamp: timestamp,
message: message,
type: type,
fullMessage: logEntry,
});
}
// 等待函數
async function waitFor(ms) {
return new Promise((resolve) => setTimeout(resolve, ms));
}
// 檢查頁面是否仍然有效
async function isPageValid() {
try {
if ($page.isClosed()) return false;
await $page.evaluate(() => document.title);
return true;
} catch (error) {
return false;
}
}
// 安全的頁面評估
async function safeEvaluate(func, ...args) {
try {
if (!(await isPageValid())) throw new Error("Page context is detached");
return await $page.evaluate(func, ...args);
} catch (error) {
log(`❌ Page evaluation failed: ${error.message}`, "error");
throw error;
}
}
// 將 Threads URL 轉換為 Threadster URL
function convertToThreadsterUrl(threadsUrl) {
try {
// 簡單地將 threads.com 替換為 threadster.net
const threadsterUrl = threadsUrl.replace(
/threads\.com/g,
"threadster.net"
);
log(`🔗 Converted URL: ${threadsUrl} -> ${threadsterUrl}`);
return threadsterUrl;
} catch (error) {
log(`❌ Error converting URL: ${error.message}`, "error");
return threadsUrl; // 回傳原始 URL 作為備援
}
}
async function pollForDownloadLinks(maxAttempts = 15, intervalMs = 3000) {
for (let attempt = 1; attempt <= maxAttempts; attempt++) {
try {
log(
`🔍 Checking for download links (attempt ${attempt}/${maxAttempts})...`
);
if (!(await isPageValid()))
throw new Error("Page context detached during polling");
const pageStatus = await safeEvaluate(() => {
const status = {
url: window.location.href,
hasErrorMsg: false,
errorMsgText: "",
hasDownloadButtons: false,
hasLoadingIndicator: false,
downloadButtonsCount: 0,
};
// 檢查錯誤訊息
const errorElements = document.querySelectorAll(
'.error__msg, .error, .alert-danger, [class*="error"]'
);
if (errorElements.length > 0) {
for (let elem of errorElements) {
if (elem.style.display !== "none" && elem.offsetHeight > 0) {
status.hasErrorMsg = true;
status.errorMsgText += elem.textContent.trim() + " ";
}
}
}
// 檢查下載按鈕
status.downloadButtonsCount = document.querySelectorAll(
'a.download__item__info__actions__button, .download-btn, [href*="download"]'
).length;
status.hasDownloadButtons = status.downloadButtonsCount > 0;
// 檢查載入指示器
status.hasLoadingIndicator = Array.from(
document.querySelectorAll('.loading, .spinner, [class*="loading"]')
).some((el) => el.style.display !== "none");
return status;
});
log(
`📊 Page status - URL: ${pageStatus.url.slice(0, 50)}... | Buttons: ${
pageStatus.downloadButtonsCount
} | Loading: ${pageStatus.hasLoadingIndicator}`
);
if (pageStatus.hasErrorMsg && pageStatus.errorMsgText) {
log(`❌ Threadster error: ${pageStatus.errorMsgText}`, "error");
return [];
}
if (pageStatus.hasDownloadButtons) {
const downloadLinks = await safeEvaluate(() => {
const links = [];
for (const button of document.querySelectorAll(
"a.download__item__info__actions__button"
)) {
const href = button.href;
if (!href || !href.startsWith("http")) continue;
let type = "unknown";
const row = button.closest("tr");
const typeText = (
row?.querySelector("td:nth-child(2)")?.textContent || ""
).toLowerCase();
const urlPath = new URL(href).pathname.toLowerCase();
if (typeText.includes("video") || urlPath.includes("/video")) {
type = "video";
} else if (
typeText.includes("photo") ||
typeText.includes("image") ||
urlPath.includes("/image")
) {
type = "image";
}
const resolution =
row?.querySelector("td:first-child")?.textContent.trim() ||
"Unknown";
links.push({
url: href,
text: `${type} (${resolution})`,
type: type,
resolution: resolution,
});
}
return links;
});
const validLinks = downloadLinks.filter(
(link) => link.type !== "unknown"
);
if (validLinks.length > 0) {
log(
`✅ Successfully extracted ${validLinks.length} valid download links.`
);
return validLinks;
}
}
if (pageStatus.hasLoadingIndicator) {
log(`⏳ Still processing, waiting...`);
}
await waitFor(intervalMs);
} catch (error) {
log(`❌ Error during polling: ${error.message}`, "error");
if (error.message.includes("detached")) return [];
if (attempt === maxAttempts) return [];
await waitFor(intervalMs);
}
}
return [];
}
async function getDownloadLinksFromThreadster(threadsUrl, retryCount = 0) {
try {
log(
`🔗 Getting download links for: ${threadsUrl} (attempt ${
retryCount + 1
})`
);
// 設定瀏覽器環境
await $page.setViewport({ width: 1366, height: 768 });
await $page.setUserAgent(
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
);
// 轉換 URL 並直接導航
const threadsterUrl = convertToThreadsterUrl(threadsUrl);
log(`🌐 Navigating directly to: ${threadsterUrl}`);
await $page.goto(threadsterUrl, {
waitUntil: "networkidle0",
timeout: 30000,
});
// 稍等一下讓頁面完全載入
await waitFor(3000);
const currentUrl = await $page.url();
log(`📄 Current page URL: ${currentUrl}`);
// 檢查頁面基本狀態
const pageInfo = await safeEvaluate(() => {
return {
title: document.title,
hasError:
document.body.textContent.toLowerCase().includes("error") ||
document.body.textContent.toLowerCase().includes("not found") ||
document.body.textContent.toLowerCase().includes("404"),
bodyText: document.body.textContent.slice(0, 200),
};
});
log(`📊 Page info - Title: ${pageInfo.title}`);
log(`📊 Has error: ${pageInfo.hasError}`);
if (pageInfo.hasError) {
log(`❌ Error page detected`, "error");
return [];
}
// 檢查下載連結
return await pollForDownloadLinks(10, 4000);
} catch (error) {
log(`❌ Error with threadster.net: ${error.message}`, "error");
if (error.message.includes("detached") && retryCount < MAX_RETRIES) {
log(`🔄 Retrying...`);
await waitFor(5000);
return await getDownloadLinksFromThreadster(threadsUrl, retryCount + 1);
}
return [];
}
}
// 取得檔案副檔名的輔助函式
function getFileExtension(url, defaultExt) {
try {
const pathname = new URL(url).pathname;
const lastPart = pathname.substring(pathname.lastIndexOf("/") + 1);
const ext = lastPart.substring(lastPart.lastIndexOf(".") + 1);
if (ext && lastPart.includes(".")) {
return ext.toLowerCase();
}
} catch (e) {}
if (url.includes("video")) return "mp4";
if (url.includes("image")) return "jpg";
return defaultExt;
}
// 主要處理邏輯
for (const [index, item] of items.entries()) {
try {
const data = item.json;
const threadData = data.thread;
const sourceUrl = data.url;
const hasImages = (threadData.images || []).length > 0;
const hasVideos = (threadData.videos || []).length > 0;
const timestamp = threadData.published_on;
const formattedDate = new Date(timestamp * 1000)
.toISOString()
.split("T")[0];
const filePrefix = `${formattedDate}_${timestamp}`;
log(
`\n🔄 Processing Item ${index + 1}/${items.length}: Thread ${timestamp}`
);
log(
`📊 Content: Images: ${
hasImages ? (threadData.images || []).length : 0
}, Videos: ${hasVideos ? "Yes" : "No"}`
);
// **收集媒體檔案資訊**
const mediaFiles = {
images: [],
videos: [],
};
// **第一步:處理圖片 - 使用獨立 HTTP 請求下載**
if (hasImages && DOWNLOAD_IMAGES) {
const images = threadData.images || [];
for (const [i, imageUrl] of images.entries()) {
try {
log(`🖼️ Downloading image ${i + 1}/${images.length}: ${imageUrl}`);
// 使用新的 page 下載圖片,避免干擾主頁面
const newPage = await $page.browser().newPage();
try {
await newPage.setUserAgent(
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
);
const response = await newPage.goto(imageUrl, {
waitUntil: "networkidle0",
timeout: 30000,
});
if (!response || !response.ok()) {
log(
`❌ Failed to download image: ${response?.status()} ${response?.statusText()}`,
"error"
);
continue;
}
const imageBuffer = await response.buffer();
// **檢查 buffer 是否有效**
if (!imageBuffer || imageBuffer.length === 0) {
log(`❌ Downloaded image buffer is empty`, "error");
continue;
}
const ext = getFileExtension(imageUrl, "jpg");
const fileName = `${filePrefix}_image_${i + 1}.${ext}`;
const relativePath = `images/${fileName}`;
// 記錄媒體檔案資訊,用於 Markdown 引用
mediaFiles.images.push({
fileName: fileName,
relativePath: relativePath,
originalUrl: imageUrl,
index: i + 1,
});
results.push({
json: {
fileType: "image",
fileName: fileName,
uploadPath: relativePath,
originalUrl: imageUrl,
},
binary: {
data: {
data: imageBuffer,
fileName: fileName,
mimeType: `image/${ext}`,
},
},
});
log(
`✅ Generated binary item for image: ${fileName} (${imageBuffer.length} bytes)`
);
} finally {
await newPage.close(); // 確保關閉新頁面
}
} catch (imageError) {
log(
`❌ Error downloading image ${i + 1}: ${imageError.message}`,
"error"
);
continue;
}
}
}
// **第二步:處理影片 - 透過 threadster.net 取得下載連結**
if (hasVideos && DOWNLOAD_VIDEOS) {
log(`🎬 Getting video download links from threadster.net...`);
const downloadLinks = await getDownloadLinksFromThreadster(sourceUrl);
const videoLinks = downloadLinks.filter(
(link) => link.type === "video"
);
if (videoLinks.length > 0) {
const bestVideoLink =
videoLinks.find((l) => l.text.toLowerCase().includes("best")) ||
videoLinks[0];
const ext = getFileExtension(bestVideoLink.url, "mp4");
const fileName = `${filePrefix}_video_1.${ext}`;
const relativePath = `videos/${fileName}`;
// 記錄影片檔案資訊,用於 Markdown 引用
mediaFiles.videos.push({
fileName: fileName,
relativePath: relativePath,
downloadUrl: bestVideoLink.url,
resolution: bestVideoLink.resolution,
});
results.push({
json: {
fileType: "video",
fileName: fileName,
downloadUrl: bestVideoLink.url,
uploadPath: relativePath,
},
});
log(`🎬 Generated item for video download: ${fileName}`);
} else {
log(`⚠️ No video download links found`, "warning");
}
}
// **第三步:產生包含媒體引用的 Markdown 內容**
const markdownFileName = `${filePrefix}.md`;
// 建構媒體引用的 Markdown 語法
let mediaMarkdown = "";
// 加入圖片引用
if (mediaFiles.images.length > 0) {
mediaMarkdown += "\n## 📸 圖片\n\n";
for (const image of mediaFiles.images) {
mediaMarkdown += `\n\n`;
}
}
// 加入影片引用
if (mediaFiles.videos.length > 0) {
mediaMarkdown += "\n## 🎬 影片\n\n";
for (const video of mediaFiles.videos) {
// 使用 HTML video 標籤以支援播放
mediaMarkdown += `<video controls>\n <source src="${video.relativePath}" type="video/mp4">\n 您的瀏覽器不支援影片播放。\n</video>\n\n`;
// 也可以用 Markdown 連結語法
mediaMarkdown += `[📹 下載影片: ${video.fileName}](${video.relativePath})\n\n`;
if (video.resolution) {
mediaMarkdown += `*解析度: ${video.resolution}*\n\n`;
}
}
}
// 準備 tags 陣列
const tags = data.output && data.output.tags ? data.output.tags : [];
const tagsYaml =
tags.length > 0 ? tags.map((tag) => ` - "${tag}"`).join("\n") : " []";
const fullMarkdownContent = `---
title: "${data.output.title.replace(/"/g, '\\"')}"
date: ${formattedDate}
source: ${sourceUrl}
author: ${threadData.username}
like_count: ${threadData.like_count || 0}
images: ${mediaFiles.images.length}
videos: ${mediaFiles.videos.length}
tags:
${tagsYaml}
---
${threadData.text}
${mediaMarkdown}
---
*本文由 Threads 自動工具備份產生*
*原始貼文:[${sourceUrl}](${sourceUrl})*
`;
const markdownBuffer = Buffer.from(fullMarkdownContent, "utf8");
results.push({
json: {
fileType: "markdown",
fileName: markdownFileName,
uploadPath: markdownFileName,
mediaFiles: mediaFiles, // 包含媒體檔案資訊供後續使用
},
binary: {
data: {
data: markdownBuffer,
fileName: markdownFileName,
mimeType: "text/markdown",
},
},
});
log(
`📝 Generated binary item for ${markdownFileName} with ${mediaFiles.images.length} images and ${mediaFiles.videos.length} videos`
);
} catch (itemError) {
log(
`❌ Error processing item ${index + 1}: ${itemError.message}`,
"error"
);
console.error(itemError.stack);
continue;
}
}
// 將日誌附加到第一個項目上
if (results.length > 0) {
results[0].json.executionLogs = executionLogs;
}
return results;
這個腳本是整個備份流程的大腦,它會負責以下幾項重要任務:
直接下載圖片:腳本會直接請求原始圖片 URL,並將其轉換為二進制檔案
解析影片連結:由於 Threads 影片的複雜性,我們會透過 threadster.net 這個第三方服務來取得影片的實際下載連結
產生 Markdown 文件:將貼文的文字內容、作者、發布日期、按讚數等數據,以及前面下載好的圖片和影片引用,全部整合到一個結構化的 Markdown (.md) 檔案中
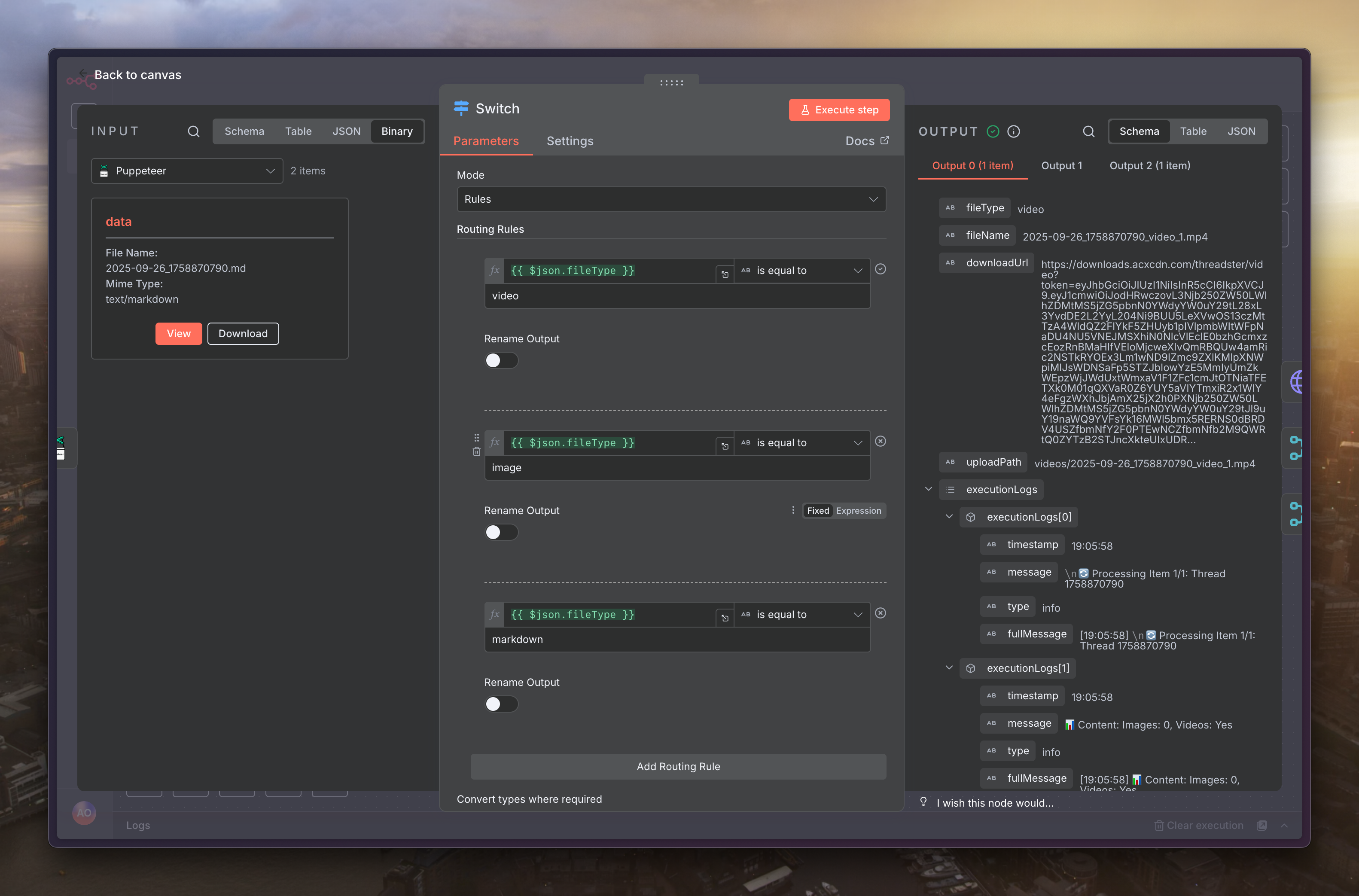
由於上一步產生了不同類型的檔案(圖片、影片、Markdown),我們需要一個「Switch」節點來進行分流,確保每種類型的檔案都走正確的處理路徑
下個節點選擇「Switch」來根據不同檔案格式做分流,變數填上
{
{
$json.fileType;
}
}
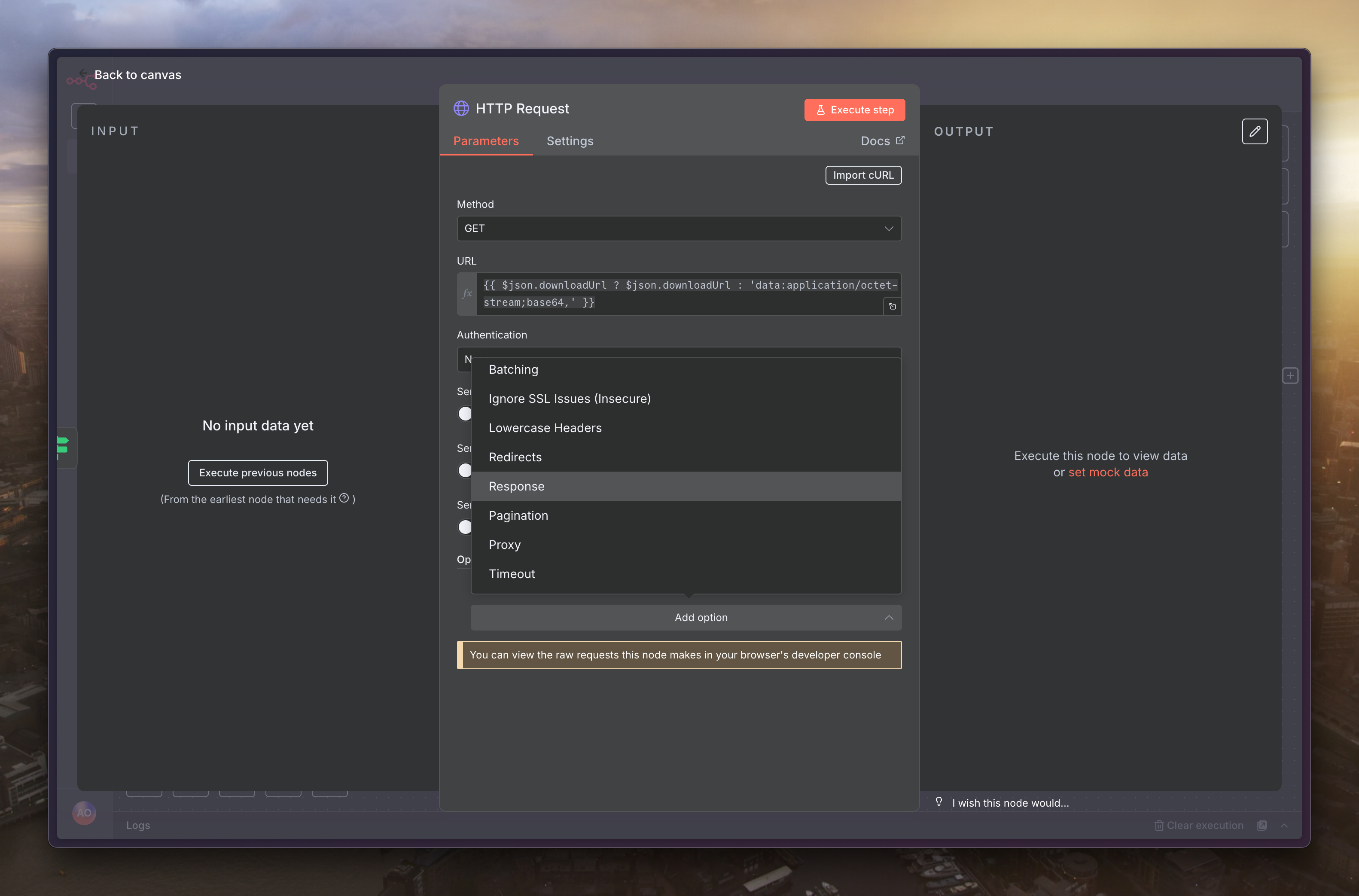
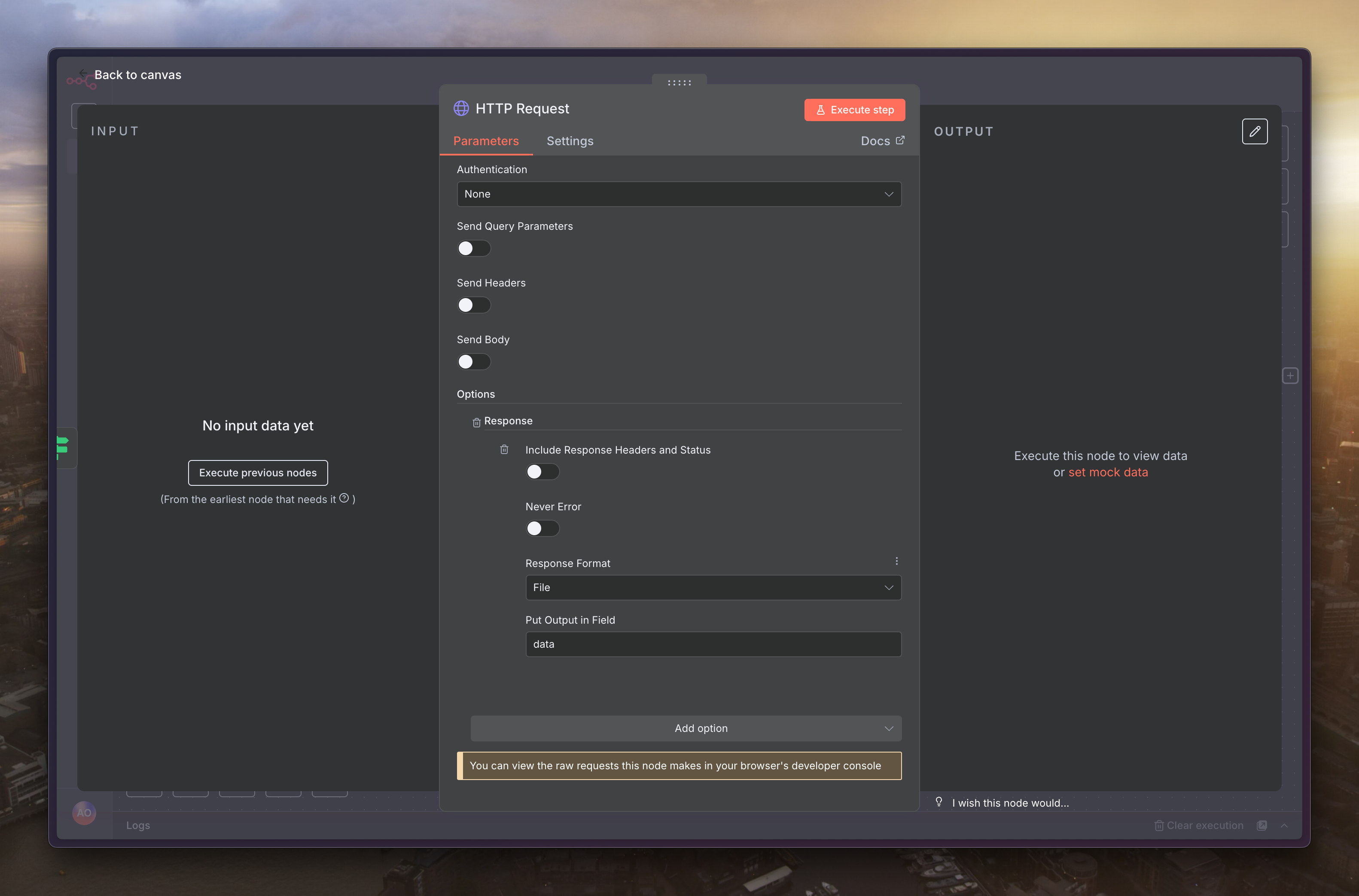
對於影片檔案,我們在上一步只取得了下載連結(URL),還沒有真正下載。現在,我們需要為影片的路徑新增一個「HTTP Request」節點
接著在「0」的路徑選擇「HTTP Request」
方法為「GET」,URL 填寫如下,並新增「Options」的「Response」
{
{
$json.downloadUrl
? $json.downloadUrl
: "data:application/octet-stream;base64,";
}
}
Response Format 設定為「File」,Put Output in Field 寫上「data」
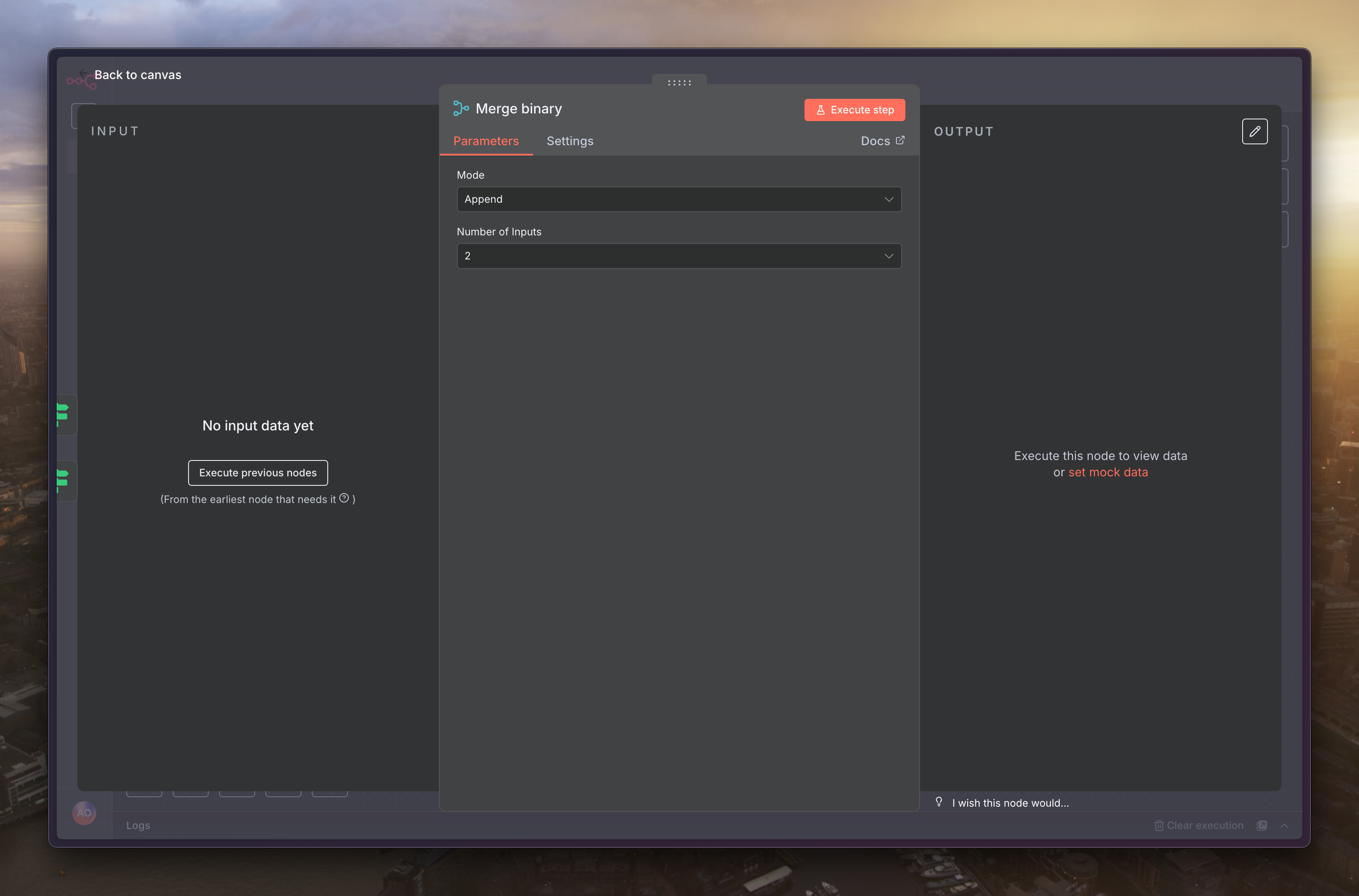
處理完所有檔案後,我們需要將它們重新匯集在一起。新增一個「Merge」節點,並將 Switch 節點分流出去的所有路徑(圖片、處理完的影片、Markdown)全部連接到這個 Merge 節點上,如此一來,無論貼文包含哪種類型的媒體,最終都會在這裡被整合,準備進行最後的儲存步驟
下個選擇「Merge」節點,命名為「Merge binary」
接著把剛剛「Switch」的「1」、「2」路徑都接到「Merge」的「input1」,而現在的流程看起來會像這樣
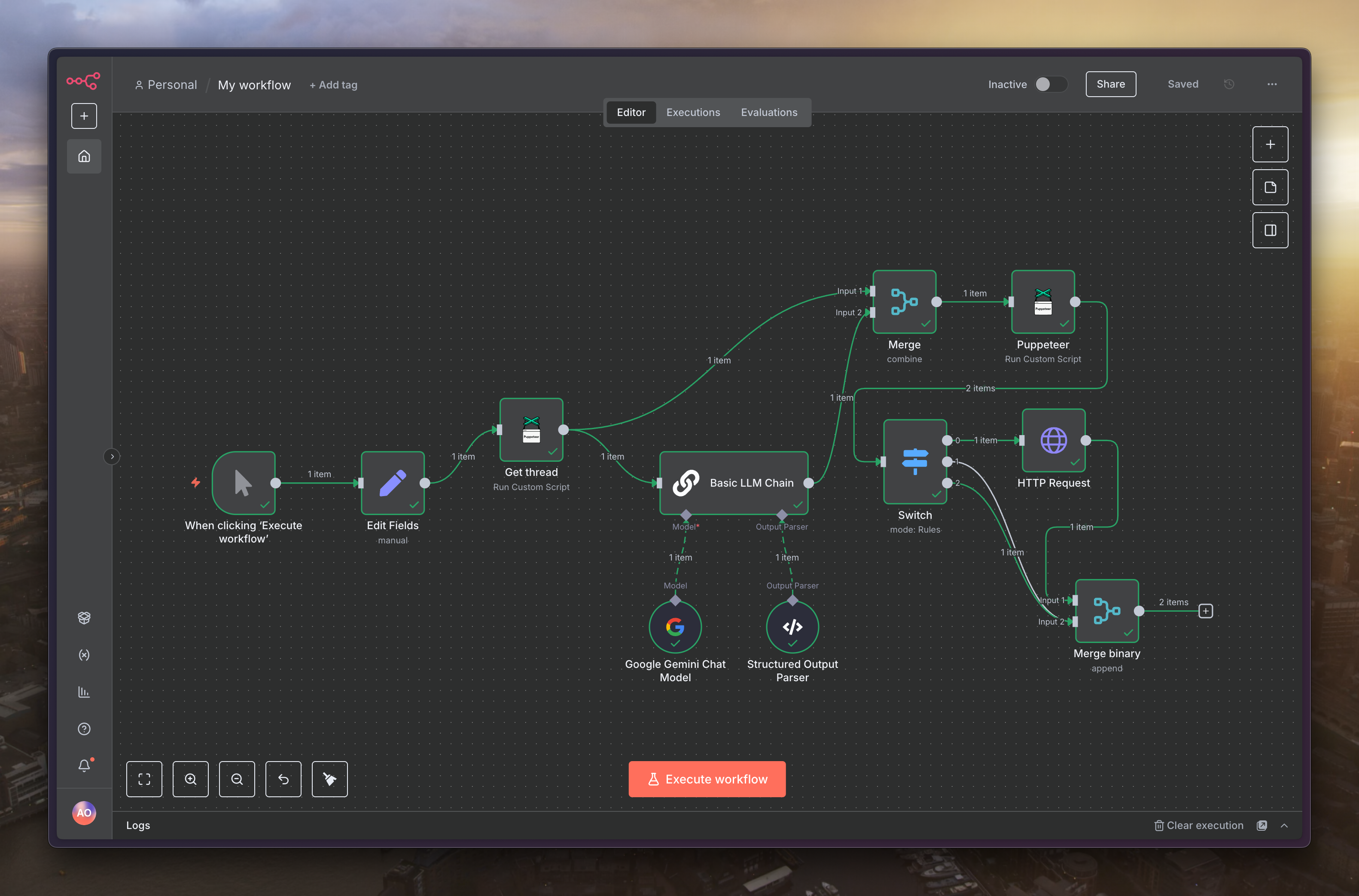
再來就找個有圖片或影片的貼文放到「Edit Fields」裡面,然後點選正下方的「Execute workflow」來試跑看看,可以看到最後的節點會幫我們把檔案產出來
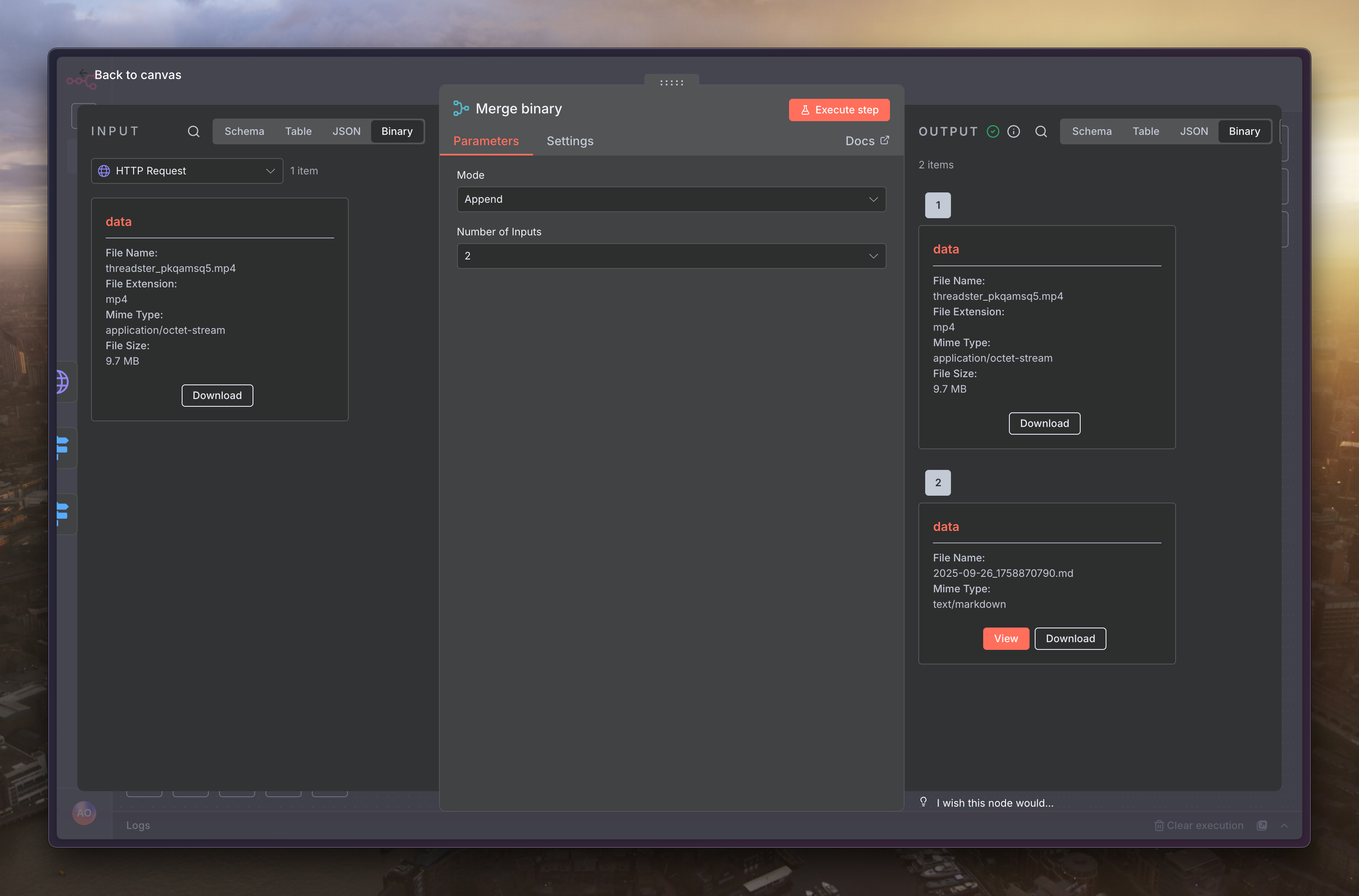
現在只需在 Merge 節點後方,接上你習慣使用的雲端硬碟節點,例如「Google Drive」或「Dropbox」,就能將這些貼文檔案自動同步到你的個人雲端空間了,透過這套自動化流程,你便可以輕鬆、高效地建立起自己的 Threads 內容備份庫惹

