2025 iThome 鐵人賽
分享至
今天分享 MCP webhook 被短時大量請求(Spike)後,系統上會出現的影響與觀察到的指標。
以下為常見、可直接量化的異常指標與現象,方便快速判讀狀態是否已惡化。
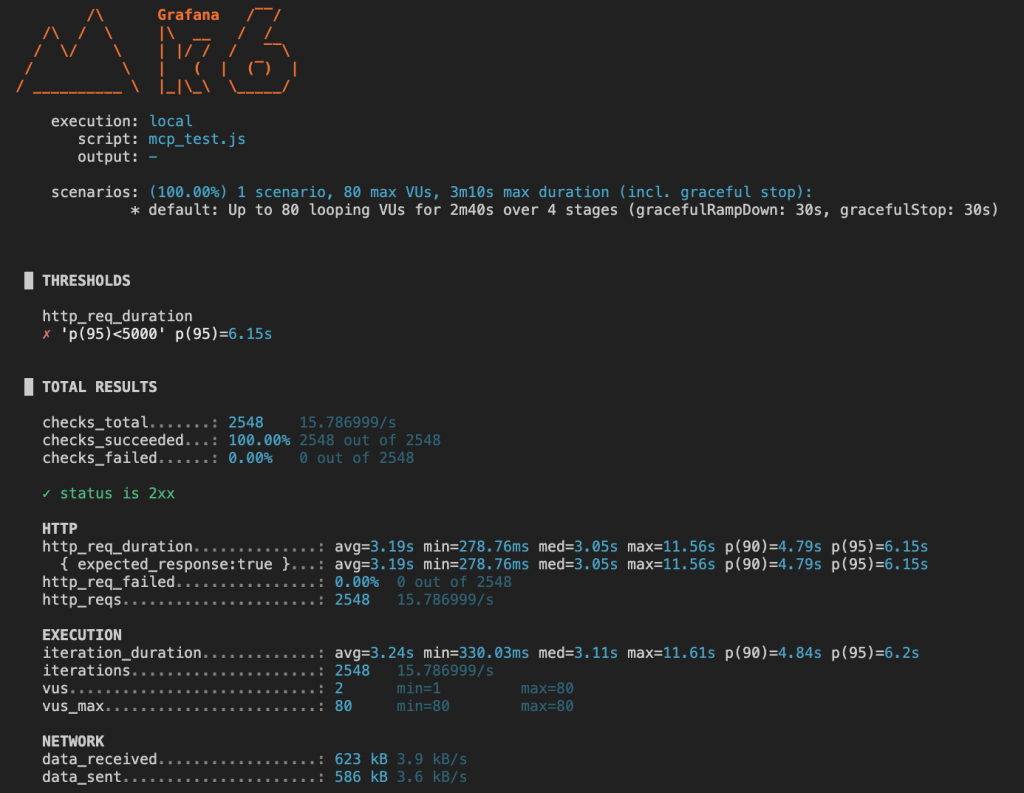
在這次模擬攻擊中,我使用 k6 對 MCP Webhook 發送突發流量(Spike),最高同時 80 個虛擬使用者 (VUs),持續約三分鐘。以下為實測輸出畫面:從結果可以看到:
這與我們前面提到的「延遲上升、佇列變長」現象完全吻合。即使沒有明顯錯誤碼,使用者體驗也會因延遲過長而受到嚴重影響。
IT邦幫忙


 iThome鐵人賽
iThome鐵人賽