繼昨天穿越水管、探索 Hugging Face 魔法工坊 之後,今天我們要進入另一個挑戰場——從TripAdvisor上的旅客真實評論中提煉寶藏!
目標是把冗長的評論轉化為可直接分析的精華資訊,包括:摘要、關鍵字與情緒判斷。就像面對情感哥布林,我們必須學會讀懂文字的力量,才能掌握資料背後的寶藏。
關於AI 魔法工坊裡的文字處理魔法
TF-IDF:純粹只看每個詞出現的頻率和它在所有文件中出現的稀有度。它不管前後文,單純靠統計算重要性。適合用來抓關鍵字或算文件相似度,是最基礎的法術。
RNN:它具有記憶力,會一步步讀文本,注意前後順序,能捕捉上下文。比 TF-IDF 聰明,但記憶力跟金魚一樣等級,容易忘掉前面的內容。常用在文本生成或情感分析。
Transformer:它一次看整篇文章,用「自注意力」抓取長距離的關聯。效率高、能抓全局語意,完勝傳統 RNN。
BERT:基於 Transformer 的預訓練模型,它可以雙向理解詞語在左右語境中的意思,預訓練好之後再用在分類、問答、摘要上。比 Transformer 更懂語意,但運算需求也更高。
冒險任務步驟:資料讀入 → 關鍵字提取 → 摘要 → 情緒分析 → 下載資料
Step 1:資料讀入
使用 files.upload()上傳檔案,把 TripAdvisor 上的旅客評論讀入 Colab。
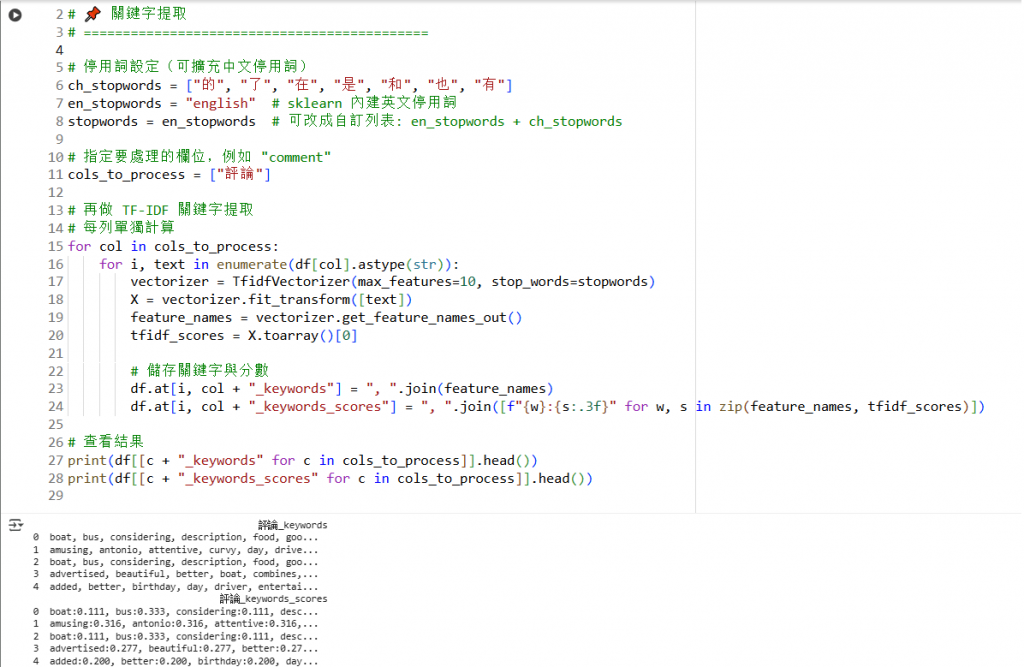
Step 2:關鍵字提取
冒險中難免踩到「烏龜殼」──就是遇到一些麻煩或意外狀況。
剛開始引用extract模型,抓取到的關鍵字幾乎是「and, the, to」這類沒意義的單字...
這才想起要善用TF-IDF停用詞,並利用關鍵字分數找出評論中的核心詞彙,幫助後續分析。
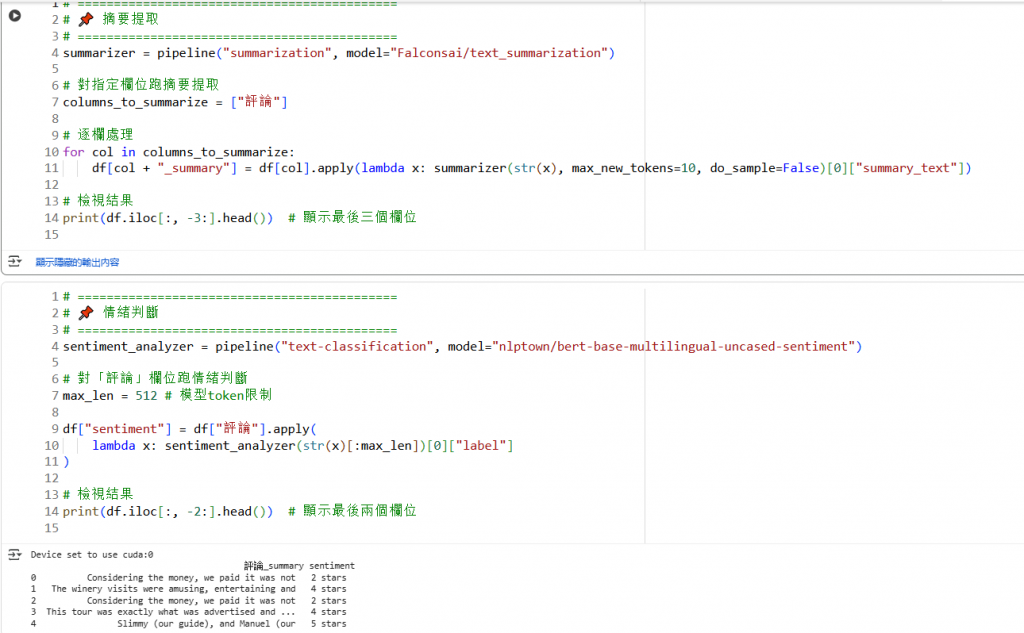
Step 3:摘要
使用Hugging Face 「Falconsai/text_summarization」模型(基於Transformer架構),將冗長評論濃縮成短句,快速掌握核心。
Step 4:情緒分析
使用Hugging Face 「nlptown/bert-base-multilingual-uncased-sentiment」模型(基於BERT架構),快速判斷評論情緒興級,便於後續洞察。
Step 5:下載資料
使用 files.download()將分析結果存回 CSV,作為後續可視化或報告輸入。
成果呈現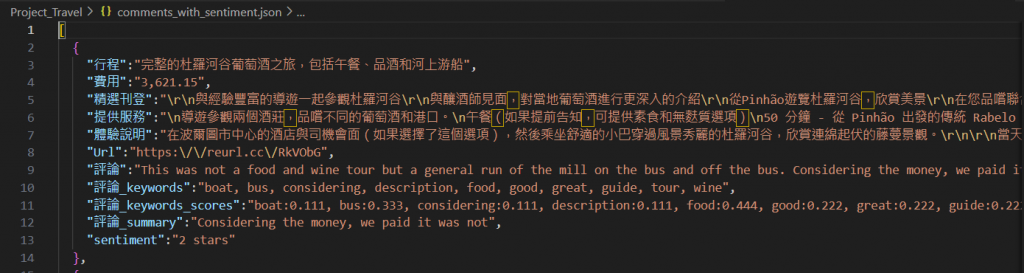
今天解鎖的新技能:
🍄 關鍵字提取技能:用 TF-IDF 尋找最具影響力的詞彙
🍄 長文本摘要魔法:掌握把原始評論濃縮成精華摘要的能力
🍄 情緒判斷力:理解評論情緒,為後續分析提供量化依據
📓 小結:
今天,我們成功將旅客評論從 原礦變成寶石:摘要、關鍵字、情緒標籤全數到位。
這不僅加速了資料分析流程,也為未來進一步挑戰「資料整合與視覺化」打下基礎。

