模型大致上可以分成兩大類分類型的跟生成型的。通常分類的模型會用到 Encoder 架構,也就是我們前面幾個章節提到的那些內容,其實都是在講 Encoder 的應用。那如果我們想要讓模型具備生成的能力,就需要導入 Decoder 架構來處理。
Decoder 架構又可以分成兩種做法一種是單純使用 Decoder,另一種則是先透過 Encoder 把輸入轉換成比較複雜的特徵,再交給 Decoder 來解讀並產生輸出。
後面的章節會一直圍繞在這個主題上,介紹不同類型的 Encoder 和 Decoder 架構,它們之間有什麼差別、又是怎麼演進的。而今天我們會先來看看一個滿經典的 Encoder-Decoder 架構Seq2Seq。
Seq2Seq(Sequence to Sequence)是一種經典的架構,主要是拿來處理輸入跟輸出都是「序列」的任務,最典型的例子就是機器翻譯。比如說我們給它一句英文,它就會輸出一段對應的中文翻譯,**輸入是一串文字,輸出也是一串文字。**這個模型背後的概念其實不難它基本上是由Encoder(編碼器)和一個 Decoder(解碼器)。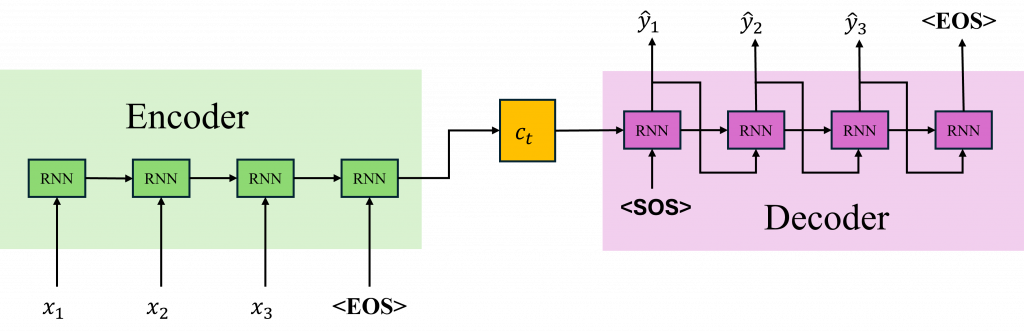
Encoder 的目的是先把輸入的句子「看過一遍」然後把它壓縮成一個高維向量(通常會叫它 context vector 或 hidden state),也可以把它想像成是模型對整個輸入句子的「理解」。接著這個向量會傳給 Decoder,Decoder 再根據這個資訊一步一步地產生輸出。
簡單來說當我們在做英文翻譯任務的時候,模型會先讀取大量的文字,然後根據這些內容產生一個 context vector。如果你還記得我們之前在情緒分析那一章提到的東西,那個時候模型在最後進入線性分類器之前,其實也會產生一個類似的向量。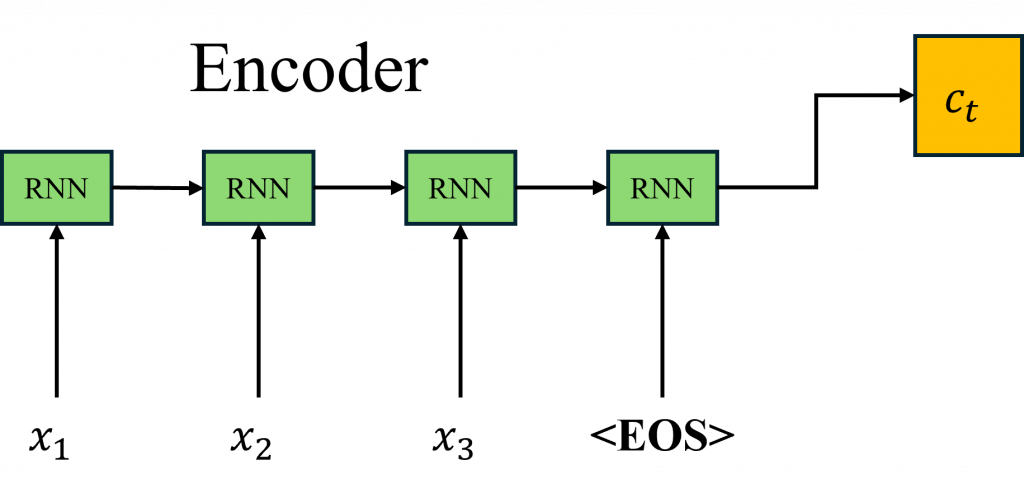
但這兩者其實有一點差別,在情緒分析裡我們的目標是根據 context vector 判斷出這句話是正面還是負面,也就是說,我們是用這個向量來分類。但在 Encoder-Decoder 架構裡,context vector 是要給 Decoder 使用的,它不是用來分類,而是幫助 Decoder 去理解輸入的句子,然後一步步地產生正確的翻譯。
簡單來說情緒分析就像是看完一整部電影後,寫下一句這部電影讓我感到很感動或這部片子真無聊,你不是要講出電影的內容,只是把整體的感受濃縮成一句話而翻譯任務則比較像是你看完這部電影後,要跟一個不懂這部語言的朋友轉述整個劇情。你腦中先把電影的內容理解一遍(這就是 Encoder 做的事),再用你朋友聽得懂的語言,把故事重新講一遍(這就是 Decoder 的工作)。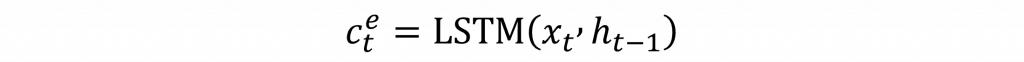
其實這背後的數學邏輯你早就學過了,就是我們在 Day 11 學時間序列模型的時候用到的那些概念。所以你會發現,現在寫這個 Encoder 程式碼,其實也沒什麼特別神祕的地方。說穿了我們只是把原本時間序列模型裡面最後那個線性分類器拿掉而已,剩下的結構幾乎都一樣。而這邊我們是用 PyTorch 的方式來實作,基本上就是沿用你已經熟悉的那套寫法。
import torch
import torch.nn as nn
class LSTMEncoder(nn.Module):
def __init__(self, input_dim, emb_dim, hidden_dim, num_layers=1, bidirectional=False, dropout=0.0):
super(LSTMEncoder, self).__init__()
self.embedding = nn.Embedding(input_dim, emb_dim)
self.lstm = nn.LSTM(emb_dim, hidden_dim, num_layers=num_layers,
bidirectional=bidirectional, dropout=dropout if num_layers > 1 else 0)
self.hidden_dim = hidden_dim
self.bidirectional = bidirectional
def forward(self, src):
# src shape: [seq_len, batch_size]
embedded = self.embedding(src) # [seq_len, batch_size, emb_dim]
outputs, (hidden, cell) = self.lstm(embedded)
# outputs shape: [seq_len, batch_size, hidden_dim * num_directions]
# hidden, cell shape: [num_layers * num_directions, batch_size, hidden_dim]
return outputs, (hidden, cell)
不過這邊有幾個地方要特別注意一下,通常在做 Encoder 處理的時候,我們會加上一些對齊的設計,目的就是幫助模型更清楚地知道一句話的開始和結束。
為了達成這個目的,我們常常會在輸入序列的開頭加上一個 SOS token(也叫 BOS token,Start/Beginning of Sentence),然後在結尾加上一個 EOS token(End of Sentence)。這樣模型在讀取context vector的時候,就能比較有方向感,知道什麼時候是句子的起點,什麼時候是終點。
Decoder 的做法就跟 Encoder 有點不一樣了。你還記得我們在 Day 11 學時間序列的時候,通常是怎麼初始化 hidden state 嗎?那時候我們會在 t=0 的時候給一個全 0 的陣列,或者是用隨機的值來當作起始狀態。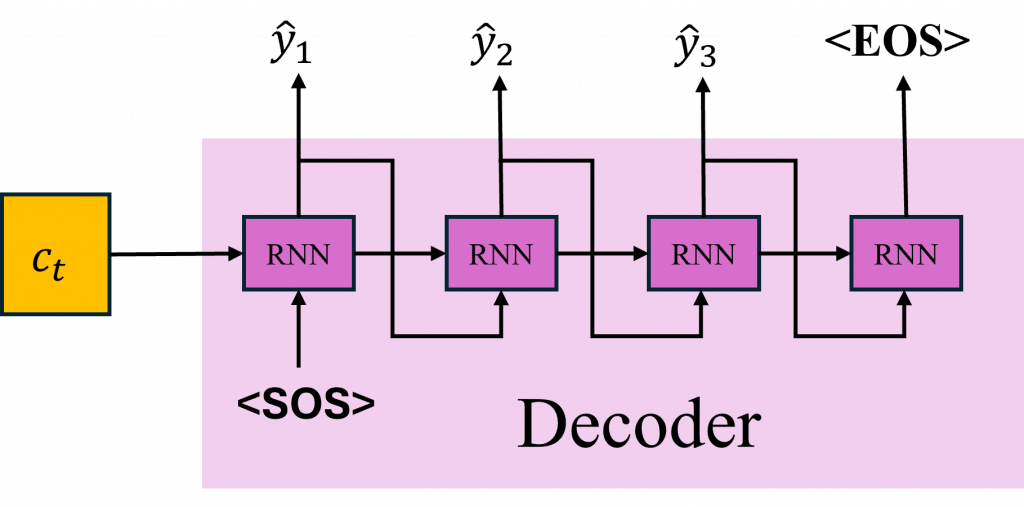
但在 Decoder 裡,t=0 的起點不是隨便給的,而是直接拿 Encoder 最後輸出的 context vector,也就是它對整段輸入文字的理解,來當作 Decoder 的第一個 hidden state,這時候我們會再加上一個 SOS token代表我要開始生成了,來讓 Decoder 開始產出 t=1 的第一個文字,我們可以用以下數學式大表示。
所以這其實也代表,Decoder 在一開始可能會先產出「我」,接著根據它剛剛自己輸出的「我」,再產出下一個字「喜歡」,然後是「你」,最後當它判斷整句話已經完成,就會輸出一個 EOS token,整個句子就結束了。
import torch
import torch.nn as nn
class LSTMDecoder(nn.Module):
def __init__(self, output_dim, emb_dim, hidden_dim, num_layers=1, dropout=0.0):
super(LSTMDecoder, self).__init__()
self.embedding = nn.Embedding(output_dim, emb_dim)
self.lstm = nn.LSTM(emb_dim, hidden_dim, num_layers=num_layers, dropout=dropout if num_layers > 1 else 0)
self.fc_out = nn.Linear(hidden_dim, output_dim)
def forward(self, input_token, hidden, cell):
# input_token: [batch_size] → 只是一個 token 的 ID
input_token = input_token.unsqueeze(0) # → [1, batch_size]
embedded = self.embedding(input_token) # → [1, batch_size, emb_dim]
output, (hidden, cell) = self.lstm(embedded, (hidden, cell))
# output: [1, batch_size, hidden_dim]
prediction = self.fc_out(output.squeeze(0)) # → [batch_size, output_dim]
return prediction, hidden, cell
如果用比較程式化的角度來看,Decoder 的每一步基本上都是這樣運作的它會接收一個來自 Encoder 的 context vector,再加上一個當前的輸入 token,然後根據這些資訊算出一個 機率分布,這個分布就是模型對所有字彙表(embedding 中的詞)的預測。最後透過 softmax 函數,我們就能得到每一個詞在這個時間點被選中的機率,而機率最高的那個詞,就會被 Decoder 當作這一步的輸出。
雖然我們剛剛提到 Decoder 是一個時間點接著一個時間點往下產生字,像是先輸出「我」,再輸出「喜歡」,然後「你」這樣接續下去。但其實在訓練的時候通常不會真的拿模型自己在前一個時間點產生的字來當作下一個時間點的輸入。因為生成任務本身就比分類困難很多你可以想像,分類只是選「對或錯」,但生成是要從上千個詞裡挑一個字,還要文意通順、語法正確。如果模型在早期訓練時,輸出的字就錯了,那後面一整串就會跟著歪掉,完全走偏,這在長序列特別明顯。
所以我們在訓練的時候,通常會用一種技巧叫做 Teacher Forcing。這個方法很簡單,就是在每個時間點,不管模型剛剛自己預測了什麼,我們都強制餵給它正確答案,也就是 ground truth 的那個字,當作它下一步的輸入。這樣做可以幫助模型看清楚理想的路線,不用一開始就承擔自己的錯誤後果,也更快學會正確的語言模式。
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device, sos_token_id):
super(Seq2Seq, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
self.sos_token_id = sos_token_id
def forward(self, src, trg, teacher_forcing_ratio=0.5):
# src: [seq_len_src, batch_size]
# trg: [seq_len_trg, batch_size]
batch_size = trg.shape[1]
trg_len = trg.shape[0]
output_dim = self.decoder.fc_out.out_features
outputs = torch.zeros(trg_len, batch_size, output_dim).to(self.device)
encoder_outputs, (hidden, cell) = self.encoder(src)
# 第一步的輸入是 SOS token
input_token = torch.tensor([self.sos_token_id] * batch_size).to(self.device)
for t in range(trg_len):
output, hidden, cell = self.decoder(input_token, hidden, cell)
outputs[t] = output
teacher_force = torch.rand(1).item() < teacher_forcing_ratio
top1 = output.argmax(1) # 選出機率最高的 token
input_token = trg[t] if teacher_force else top1
return outputs
不過完全依賴 Teacher Forcing 也不是一件好事,雖然這種做法在訓練初期能加快收斂速度,但它也有一個很明顯的缺點模型變得太依賴「正確答案」來幫它導路。這會導致什麼問題?就是當模型真正上場、要自己一路生成句子的時候,它可能一下就迷路了。因為它在訓練時從來沒有犯錯後自我修正的機會,一旦輸出錯了一個字,它根本不知道該怎麼把句子拉回來。
所以比較理想的做法是什麼?就是適度地加入一點模型自己的輸出,當作下一步的輸入,讓它學會在雜訊中也能找到方向。這種策略有時候會用 scheduled sampling 來實作,也就是慢慢降低 Teacher Forcing 的比例,讓模型逐步學習自立自強。簡單說就是你一開始牽著它的手走,但久了你要放手,讓它自己練習怎麼走,即使跌倒,也得學會站起來。
同時這也是一個很重要的步驟,因為在推論(inference)時,它就不能再靠正確答案了這樣一步錯、步步錯,就可能完全偏離主題,開始產出不相關、胡說八道、邏輯不通的文字,這就是所謂的「幻覺」。這也是為什麼現在越來越多的研究都強調,要在訓練中加入一定程度的雜訊或不確定性,讓模型學會面對錯誤情境,才不會一到真實應用就崩潰。
讓一個 context vector 承擔整段輸入句子的所有資訊,其實對 Decoder 來說是滿吃力的。尤其當句子越來越長時,後面的資訊就越容易被壓縮掉甚至遺忘,這也導致模型在產生句尾的時候,常常會出現內容不清楚、語意走偏的狀況。
為了改善這個問題早期的方法會用一種叫 sliding window 的技巧,簡單來說就是把長句子切成一段一段的固定長度,分批進行翻譯。但這樣做其實還是有侷限,因為它沒辦法真正解決「資訊集中在一個向量裡」這個根本問題。
所以後來就出現了一個非常重要的技術Attention所以明天我們就要來進一步看看:要怎麼在 Seq2Seq 裡面加上 Attention,讓它更聰明、更靈活地生成文字。


 iThome鐵人賽
iThome鐵人賽