在完成馴服評論哥布林,把冗長的旅客留言煉化成摘要、關鍵字與情緒標籤的挑戰之後,今天,我們準備將冷冰冰的數據轉化為會說話的圖像,讓我們像望進水晶球一樣,一眼就看出評論背後的故事。
今天選用的資料來自於 Kaggle 上有關尼泊爾當地景點的評論Dataset,原始資料有7000多筆,包含id、location、review。我們要挑戰的任務是:把這些原始評論視覺化,讓趨勢與情緒一眼可見。
先來介紹Python家族裡的響噹噹人物:
jieba
來自中文世界的分詞忍者,名字取自「結巴」。由於中文沒有天然的空格,它負責幫我們把長句拆成有意義的詞彙,為後續的統計與可視化奠定基礎。
Matplotlib
Python 中最古老的畫圖法師,就像是一塊可以自由揮灑的畫布,任何線條、點陣、顏色都能描繪出來。雖然語法稍顯繁瑣,但基礎穩固,是所有後續工具的根基。
Seaborn
後起之秀,專為統計圖表而生。它站在 Matplotlib 的肩膀上,把複雜的設定包裝成簡單指令,像是一位優雅的水系法師,召喚出配色美麗、結構清晰的圖表。
冒險任務步驟:
檢視資料 → 處理缺失值 → 地點分群 →
評論清理與分詞 → 詞頻統計 → 情緒分析 → 視覺化圖表
Step 1:評論清理與分詞
使用 jieba 將評論切分為詞彙。
去除停用詞,留下真正有意義的詞彙。在此例中包含:"nepal", "the", "it", "one", "place", "world","good", "nice", "beautiful", "very", "amazing","visit","site","best","city","view","top","also","see"]
自定義字典,中文不像英文那樣單字間有空格作為判斷,針對中文的情境,可以將特別的專有名詞、地名或口語用語加入斷詞詞庫,例如「夜市」、「阿里山」等,讓 jieba 不會錯切詞。這樣處理後,TF-IDF 計算和詞頻圖才能真正反映評論中有意義的資訊,而不是被拆成碎片或忽略。
Step 2:詞頻統計
使用 scikit-learn 的 TF-IDF,把評論轉換成詞頻矩陣。
找出最有代表性的熱門詞,呈現評論內容焦點。
Step 3:情緒分析
對每則評論跑多語言 BERT 情緒分析,取得星級標籤,並轉換成 positive / neutral / negative。
Step 4:視覺化圖表
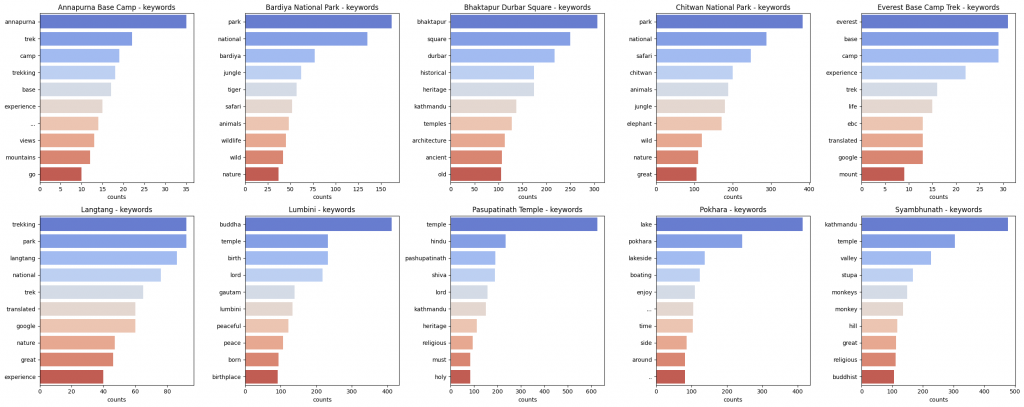
用 Seaborn 繪製:依地點統計的詞頻水平長條圖,顯示熱門關鍵字。
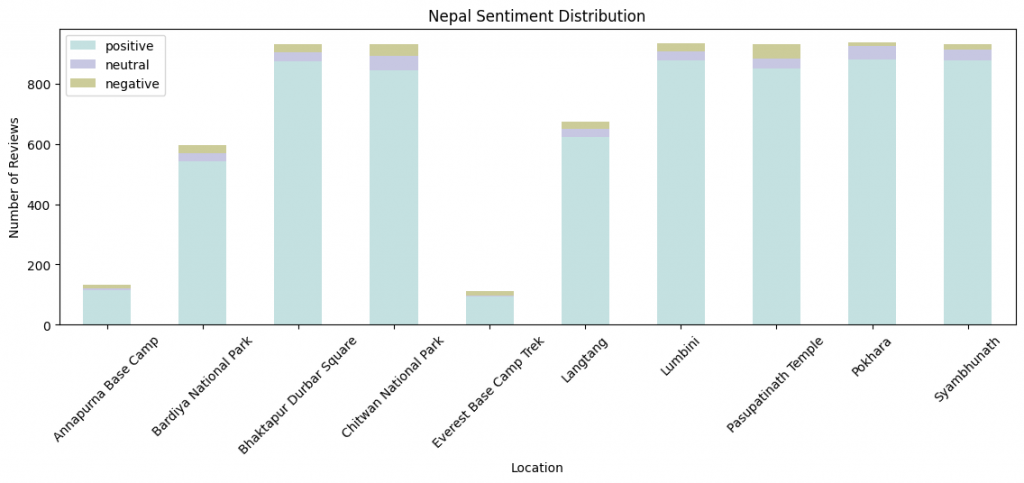
用 Matplotlib繪製:依地點統計的情緒堆疊柱狀圖,各景點的正面、中立、負面評論數量一眼可見。
參考 色碼表,添加視覺效果。
成果呈現
完成後,我們能看到:
哪些詞在評論中最常出現,一眼看出每個景點的特色
各景點的情緒分布比例,一眼看懂哪些景點口碑較好
這些圖像就像一顆「評論水晶球」,讓資料瞬間變得有生命力。
今天解鎖的新技能:
🍄 中文分詞忍術:用 Jieba 切分文字,打造更乾淨的分析基礎
🍄 視覺化法術:用 Matplotlib 與 Seaborn 把數據變成直觀圖表
📓 小結:
今天,我們從評論文字進化到「會說話的視覺化圖像」。
一秒理解密密麻麻數據背後的故事。