一、機器學習模型的擬合問題:欠擬合與過擬合
-
欠擬合 (Underfitting)
欠擬合是指模型過於簡單,無法捕捉資料中的基本規律。這通常發生在使用線性模型等簡單模型,或訓練時間不足時。欠擬合的模型訓練誤差和測試誤差都很大,無法有效描述資料分布,導致模型表現不佳。
-
過擬合 (Overfitting)
過擬合是指模型過於複雜,不僅學習了資料的規律,還記住了訓練集中的雜訊。這會導致模型在訓練集上表現極佳,但在未知的測試集上表現很差。過擬合的常見原因包括:模型參數過多、使用了過於複雜的模型或特徵數量過多。在實務中,過擬合的問題遠比欠擬合更常見,且通常需要花費更多精力來解決。
-
合適的擬合
合適的擬合介於欠擬合與過擬合之間,模型能有效捕捉資料的規律,並在訓練集和測試集上都有良好的表現。
二、模型的評估指標
在評估機器學習模型時,選擇正確的指標至關重要。
1. 迴歸模型的評估
迴歸模型常用於預測連續值,其評估指標相對簡單:
-
均方誤差 (MSE, Mean Squared Error): 衡量預測值與真實值之間偏差的平方和的平均,是迴歸模型中最常用的指標。
-
平均絕對誤差 (MAE, Mean Absolute Error): 衡量預測值與真實值之間絕對誤差的平均。
2. 分類模型的評估
分類模型,尤其是二分類任務(如預測結果為「0」或「1」),需要更精確的評估指標。首先,需要理解四種基本結果:
-
TP (True Positive): 預測為 1,實際為 1。
-
FP (False Positive): 預測為 1,實際為 0 (誤報)。
-
FN (False Negative): 預測為 0,實際為 1 (漏報)。
-
TN (True Negative): 預測為 0,實際為 0。
基於這四個基本結果,可以計算出以下重要指標:
-
準確率 (Accuracy): 這是最直觀的指標,衡量模型預測正確的比例。
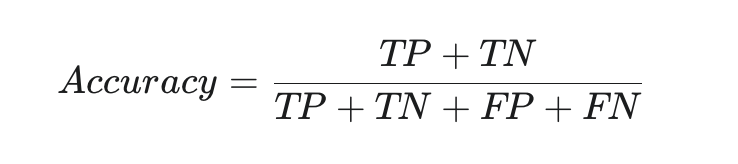
-
精確率 (Precision): 衡量在所有模型預測為正的結果中,有多少是真正的。精確率越高,代表模型的誤報率越低。
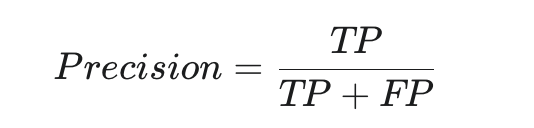
-
召回率 (Recall): 衡量在所有實際為正的樣本中,有多少被模型成功預測為正。召回率越高,代表模型的漏報率越低。
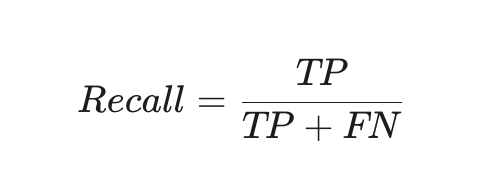
-
F1-Score: 綜合考量精確率與召回率的指標,特別適用於精確率與召回率同等重要的場景。它是兩者的調和平均數。

根據不同的應用場景,精確率與召回率的側重點會有所不同。例如,在罪犯追蹤中,我們希望判斷出的「罪犯」都是真的,因此會追求高精確率;而在地震預測中,我們寧可誤報,也希望不錯過任何一次真的地震,因此會追求高召回率。
三、防止過擬合的策略
由於過擬合是機器學習中更常見且更嚴重的問題,有許多方法可以有效處理:
-
增加訓練資料: 更多資料能幫助模型更好地學習資料的真實分布,減少對單個樣本雜訊的依賴。若無法取得新資料,可使用資料增強 (Data Augmentation) 技術來生成虛擬資料。
-
使用正規化 (Regularization): 透過在損失函數中加入懲罰項,來限制模型參數的大小,從而降低模型的複雜度。常見方法包括 L1 和 L2 正規化。
-
提前終止 (Early Stopping): 在模型訓練過程中,監測模型在驗證集上的表現,當表現不再顯著提升時就停止訓練,避免過度擬合訓練集。
-
減少特徵數量: 特徵越多,模型越容易變得複雜。可以透過人工手動篩選或使用特徵選擇演算法來減少不必要的特徵。
-
整合演算法 (Ensemble Methods): 將多個簡單模型的預測結果進行平均或加權,能夠有效降低單個模型過擬合的影響,提高整體模型的穩定性。
四、機器學習與人類表現的比較
- 機器學習模型在某些任務上的表現已經超越人類水準,例如圖像辨識。
- 然而,機器學習的表現提升最終會達到一個「瓶頸」,即貝葉斯最優誤差 (Bayes Error)。這是理論上的最佳表現,無法被任何演算法超越。
- 將機器學習模型的誤差與人類誤差進行對比,可以幫助我們判斷目前的主要問題是偏差 (Bias) 還是方差 (Variance),從而選擇正確的優化策略。
- 如果模型訓練誤差與人類誤差相近,但與開發集誤差(Dev Error)差距較大,則主要問題是方差,應專注於解決過擬合。
- 如果模型訓練誤差與人類誤差之間有較大差距,則主要問題是偏差,應專注於提高模型複雜度或訓練時間。


 iThome鐵人賽
iThome鐵人賽