安安!前幾週我們介紹完如何訓練模型以及知道了大致流程會怎麼做,
但訓練完就結束了嗎?當然不是啦~
順練的模型再fancy、加入的特徵再好我們也必須要驗收評估模型才知道她到底好不好,是不是抓的這些特徵真的有用,所以在訓練完模型後我們緊接著就要做模型評估!可以說是一個非常重要的一環~ 所以今天就會來跟大家介紹一下一般我們在測評模型時的幾個指標!
那廢話不多說趕緊開始嚕~
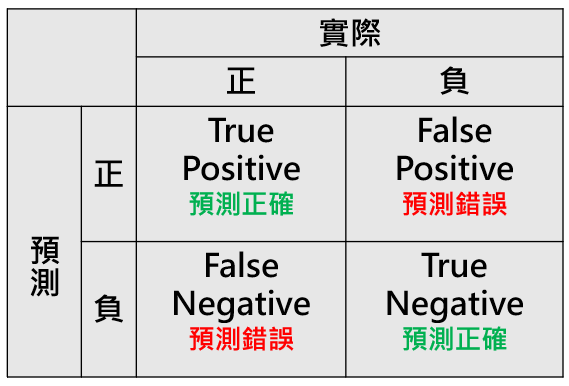
用機器學習做分類任務時,我們需要一些統計指標來幫助了解模型的表現,而其中最常被用來檢視分類結果的就是 混淆矩陣(Confusion Matrix)了。那什麼是混淆矩陣呢?
混淆矩陣是一個可以用來呈現模型的預測結果與實際結果的對照情況,總共會有四個數值,分別是
True Postive(TP):模型預測正確且為正類
True Nagative(TN):模型預測正確且為負類
False Postive(FP):模型預測錯誤,預測為正但實際為負
False Nagative (FN):模型預測錯誤,預測為負但實際為正
如果是一個二元分類的情況會是一個2*2 的表格,行列代表的是「真實答案」而縱列代表的是「模型預測的結果」
現在這樣講可能有一些些抽象,我們用一個簡單的例子來說明
假設我今天訓練的模型是用來「預測一封信是不是垃圾信」,橫列代表「真實標籤」,縱列代表「模型的預測結果」,表格的四個格子分別是:
| 真實答案:垃圾信 | 真實答案:非垃圾信 | |
|---|---|---|
| 模型預測結果:垃圾信 | True Positive 模型正確預測為垃圾信 | False Postive 真實是非垃圾信但模型預測成垃圾信 |
| 模型預測結果:非垃圾信 | False Negative 真實答案是垃圾信但模型預測為非垃圾信 | True Negative 模型正確預測為非垃圾信 |
那運用這四個數值呢,我們就可以藉此算出四大評估模型的指標,那就是accuracy 、recall、percision、F1-Score,來比較模型跟正確答案的比例為何。
那第一個指標是正確率(accuracy)
那他主要就是看所有分類結果中模型分類正確的比例佔多少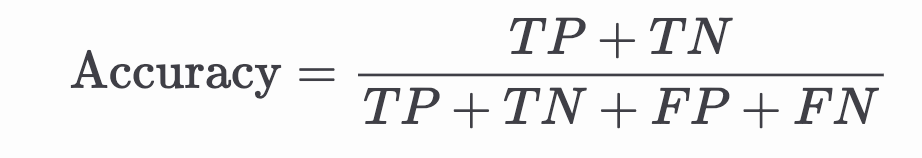
這個指標看起來沒什麼太大問題,但大家可以想想看,如果今天資料總共有100筆,其中99筆都是垃圾郵件
這時模型在做分類任務時,全部都猜是屬於垃圾郵件這個類別,那模型的準確度算出來就會特別高,但他其實並不是一個真正表現的好,只是剛好資料不平均,答案又剛好被他矇到而已。所以光是只有這個指標是不夠的!
召回率關注的是在所有真實答案為正類的樣本中,多少被模型正確找出來。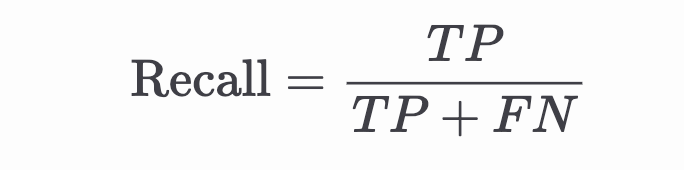
召回率越高,代表「漏網之魚」越少,但有時可能犧牲精確度(例如把很多正常信件也抓成垃圾信)。
精確率則關注另一個面向,主要是模型判斷為正類的樣本中,有多少是真的正類(也可以想像成模型的判斷到底精不精準)
精確率越高,代表「誤抓」的比例越低,但有時可能會降低召回率(例如過於保守,只抓最確定的垃圾信)
可以看出recall 跟 precision 看的面向不同,因此透過這些指標可以看到模型在不同面向的表現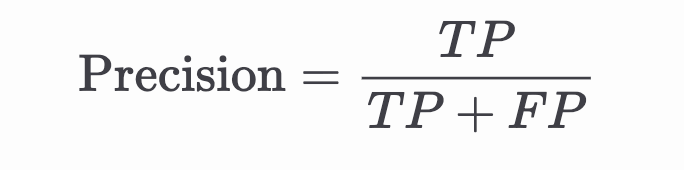
F1-score 是 Precision 與 Recall 的調和平均數,也就是一個可以同時考量兩著的指標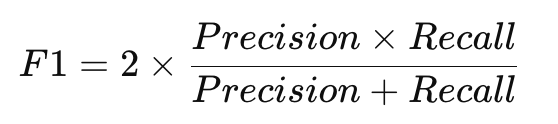
以上四種就是我們最常用來評估分類模型表現的指標:
準確率(Accuracy)、精確率(Precision)、召回率(Recall)、以及 F1-score。
它們各自關注的面向不同:
準確率看整體正確比例
精確率強調預測為正確時的「純度」
召回率重視真正正例有沒有都被找出來
F1-score 則綜合兩者的平衡
在實際專案中,我們通常會根據我們的任務內容搭配觀察這些指標,而不是只看單一數字
例如如果你的任務是抓假訊息,你的目標是希望模型對任何可能是假新聞的文章都不要漏抓,這時你可能就會側重在看召回率,因為越高的召回率代表模型越不容易漏掉真正的假新聞。那如果你的目的是垃圾信過濾,希望被判斷為垃圾信的郵件幾乎都真的有問題,就會更看重精確率,避免正常信件被誤刪。
而當任務同時需要兼顧「不漏抓」與「不誤判」,就可以觀察F1-score 來平衡兩者。
好啦,那這大概就是評估模型的幾個重要指標的介紹,學到這裡,你大致已經了解整個模型訓練的流程了!
大家給自己一個掌聲👏 我們明天繼續努力嚕!

