嗨嚕~大家午安呀!
這兩天我們講了傳統機器學習中很經典的兩個模型,希望在介紹過程中大家都有對模型以及整個訓練過程加減了解一些,那我們今天一樣要繼續介紹另一個常被提及用來做分類任務的模型,那就是邏輯迴歸(Logistic Regression) 啦!
在介紹邏輯回歸之前,我們先來了解一下機器學習通常會分成的兩種類型:
監督式學習(Supervised Learning)
這種類型的機器學習中,每一筆訓練資料都有標籤
例如:在一堆包含貓和狗的照片中,每張照片都已標記「貓」或「狗」,也就是資料都有「標準答案」。
模型會透過這些有答案的資料學習,找出特徵與標籤之間的規律,之後遇到新的資料就能預測正確的標籤。
非監督式學習(Unsupervised Learning)
與監督式學習最大的不同是:資料沒有標籤,只有大量未標記的資料
模型需要自己找出隱藏的結構,例如自動將風格相似的文章分群,或找出客戶群體的共同特徵。
一般會應用在資料的**自動分群(Clustering)或降維(例如主成分分析 PCA)**等任務。
而我們這幾天介紹的 SVM、Decision Tree,以及今天要講的邏輯回歸(Logistic Regression),
都屬於監督式學習,所以這些模型通常會用在分類任務上。
邏輯回歸是一種線性回歸的變體,它的主要目的是找到一條能夠有效區分兩類資料的界線。
和普通的線性回歸不同的是,線性回歸尋找的是一條「最佳擬合線」,希望所有資料點越靠近這條線越好,因此通常用來做連續數值的預測,而不是分類,可以參考下圖了解一下差別: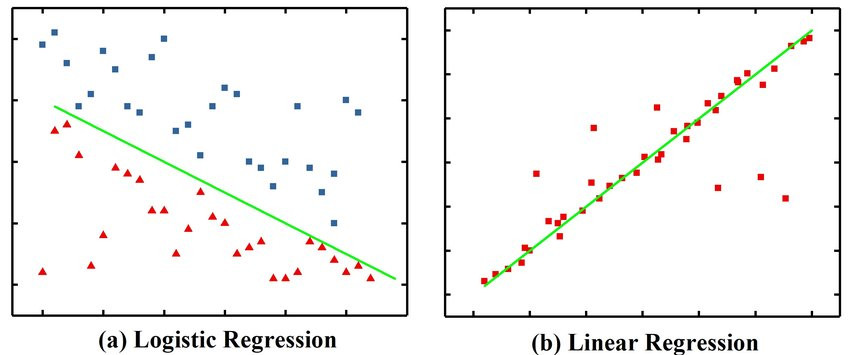
而至於邏輯回歸如何找出這條分界線,我們這裡就不細講了 XD,畢竟裡面涉及不少數學公式。
簡單來說,模型會根據資料的不同特徵給予加權值,先做一次線性運算,再把結果套入 Sigmoid 函數,把輸出的數值壓縮到 0~1 之間。這個 0~1 的機率就能用來判斷資料屬於哪一類。
有了這條分界線之後,當新資料進來時,模型就能根據它的特徵,判斷這筆資料更接近哪個類別!
那我就一樣來實作一下~
一樣用這幾天有用到的學生資料當練習!
# 讀取資料
df = pd.read_csv('/Users/xxuan/Downloads/student.csv')
基本步驟都差不多,大致會先讀資料 -> 轉換資料至數值 -> 切分測試集、訓練集 -> 訓練模型 -> 評估模型只是我們可以根據我們的目的選擇不一樣的模型!
le = LabelEncoder()
df['High_School_Type'] = le.fit_transform(df['High_School_Type'])
target = le.fit_transform(df['Sex'])
# 區分特徵 & 目標
features = df[['High_School_Type', 'Weekly_Study_Hours', 'Student_Age']]
# 切分資料
feat_train, feat_test, target_train, target_test = train_test_split(features, target, test_size=0.2, random_state=0)
# 建立模型
log_reg = LogisticRegression() #這裡使用邏輯回歸模型!
log_reg.fit(feat_train, target_train)
# 檢視準確率
print(log_reg.score(feat_test, target_test))
輸出結果
0.5517241379310345
表現似乎比昨天的決策樹好呢xd
當然,特徵的不同也會影響模型表現,所以大家可以試者挑不同的特徵來訓練模型喔!
喔虧!那最基本常被提到的傳統機器學習模型就大概講到這裡~
明天我們會來介紹到底如何評估自己訓練的模型是好是壞,那就明天見啦~

