到目前為止,我們已經分別完成了 Facebook、Instagram、Threads 的自動化發文工作流。每一條「產線」都能獨立運作,但身為追求效率的懶人,我們不禁要問:
難道不能有一個「總開關」,一次搞定所有事嗎?
今天,就是我們「正式合體」的時刻!我們將迎來本系列第一個集大成的篇章,目標是打造一條整合過的工作流 —— 只要一鍵觸發,就能同時在三個平台發文。
更重要的是,今天你不只會學到「如何做」,更會學到「如何思考」。我們將一起探討工作流設計的哲學,同時解鎖 n8n 中最能體現專業度的功能之一:子工作流 (Subworkflow),讓你的自動化系統既強大又優雅。
讓我們直接開始吧!
要一條工作流直接同步上傳三個社交平台,最快也最直觀的方式,就是直接在 Schedule Trigger 後面拉出三條支流,分別貼上我們過去幾天所打造的 Facebook、Instagram、Threads 的發文工作流。
就像下面這樣: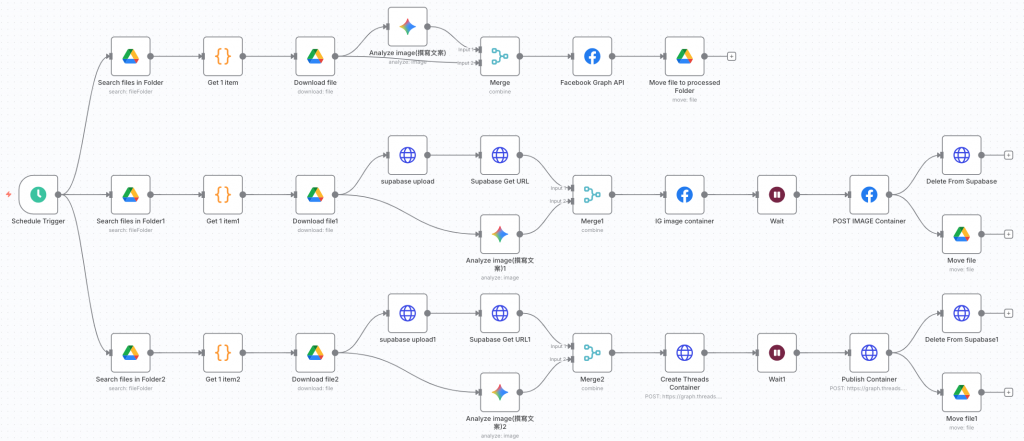
看起來簡單明瞭,但實際上卻有一個小陷阱。
因為 n8n 在分支時會把同一份輸出資料傳給各個分支,但分支的執行流程是依序完成的;若你在每個分支內各自重新抓資料或移動檔案,就會造成不一致或競爭條件。
如果有一個節點後面分出三個支流,n8n 會在該節點執行結束完把 output 資料同時間都傳給分之出來的節點,但是仍然會一條支流執行完才執行下一條。
因此如果你需要在所有平台都完成後再做某件事(例如歸檔),可以在最後用 Merge(等候所有 input 的支流完成)。
換句話說,如果按照上面的暴力法工作流執行,n8n 會:
你發現了嗎?因為在三條支流裡又各自重新取得文案、圖片,就會導致三次發文內容不一致。所以,雖然暴力法可以跑,但顯然不是最優解。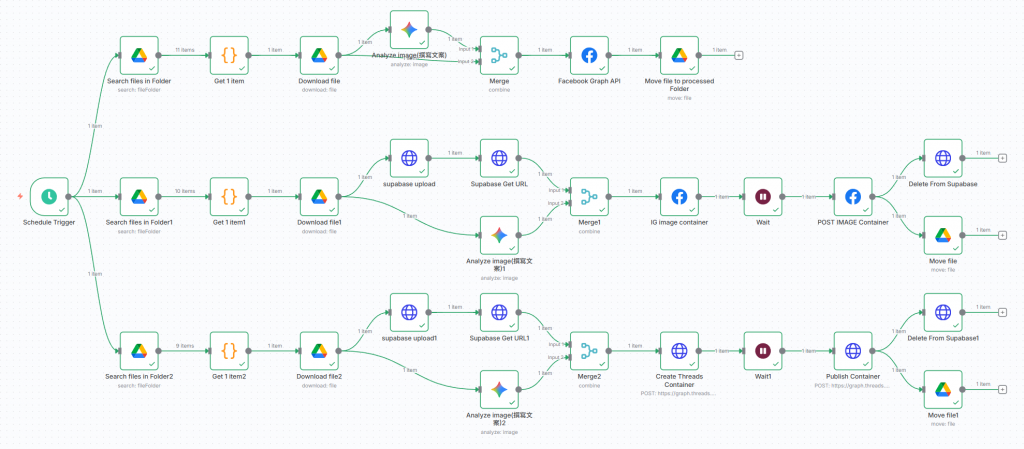
認真看的話,在暴力法工作流中,三個支流從 Google Drive 讀取到的檔案數逐漸少一個,可以驗證最上面那條支流執行完、歸檔後,才執行第二條支流。
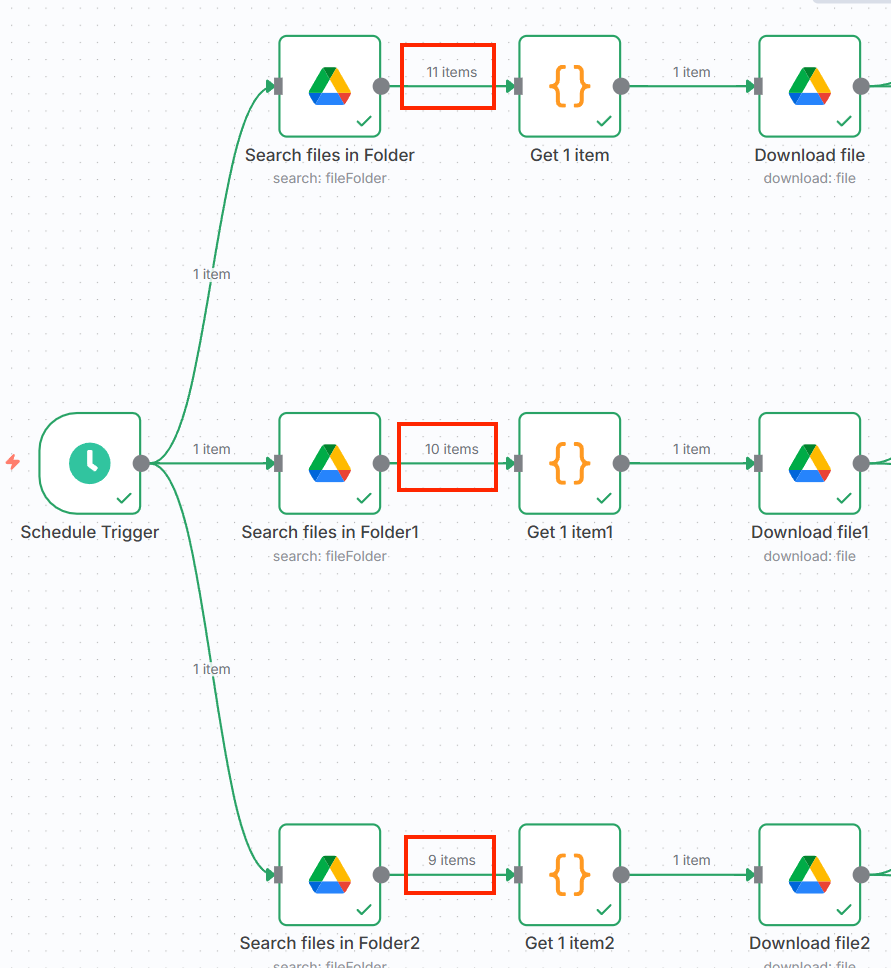
因此,在整合工作流的過程中,我們應該要去思考一下資料的流向、怎麼去走。
下圖為暴力法執行結果,可以發現雖然都有成功取得檔案、AI 撰寫文案,但是三個平台發的文都是不一樣的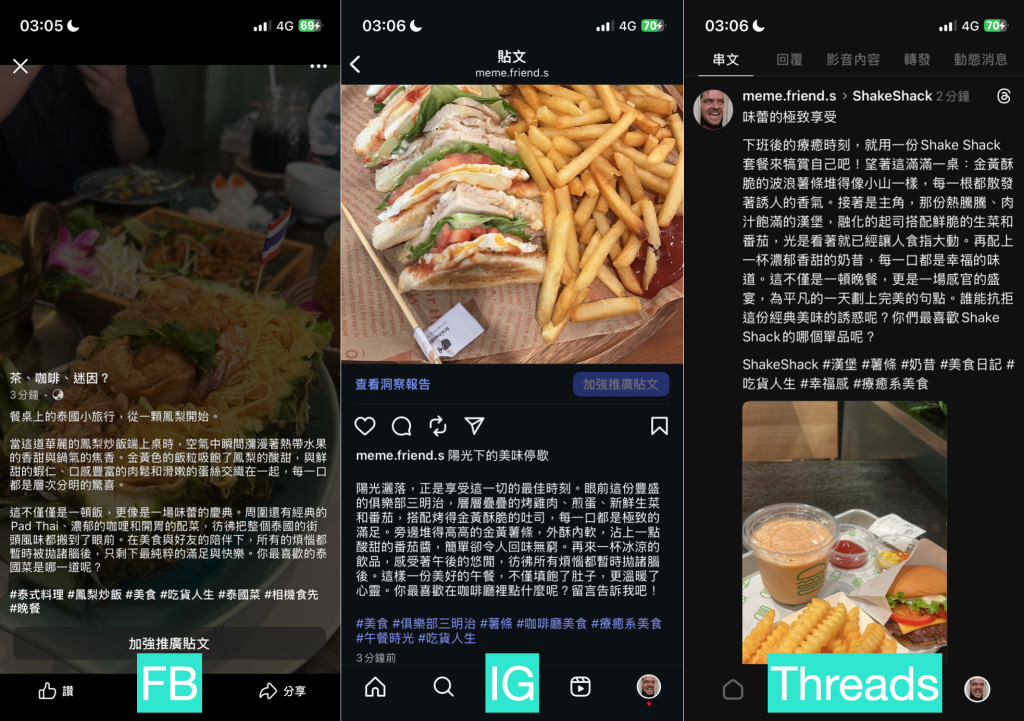
在優化之前,我們先來做一個流程盤點。我們先觀察一下,重複的節點有哪些,同時也要去思考,節點的執行順序是否會影響到資料流的處理。
仔細想想,就會發現:
這邊容易忽略的是 Binary Data,我們以前如果要取得某些資料,可以橫跨節點去取得,但是Binary Data 會洗掉,所以需要有一條直接從 Google Drive Download 節點直接接到 Merge,這樣才能成功取得 Binary Data,並讓臉書發文節點抓到這個檔案。
雖然 IG 和 Threads 都是先建立 container 在發布 container,但是container id 並不能共用,所以還是要分流
於是,我們可以根據上述想法,將工作流進行整理後,大概是這樣: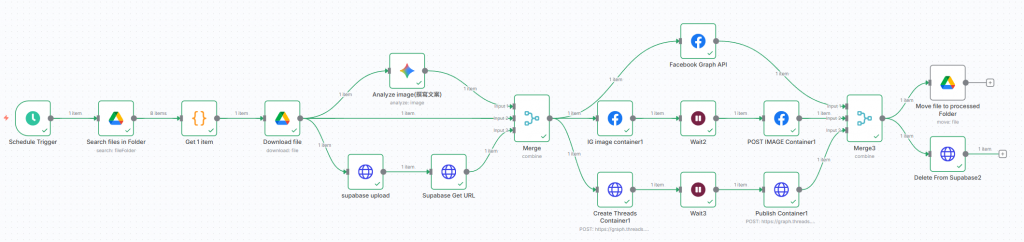
整理過程中,某些參數的名稱仍需調整,直接複製其他工作流並貼上的話,很有可能會讀取不到。
成功合併,並執行下後,可以發現三個平台發的圖文就都統一了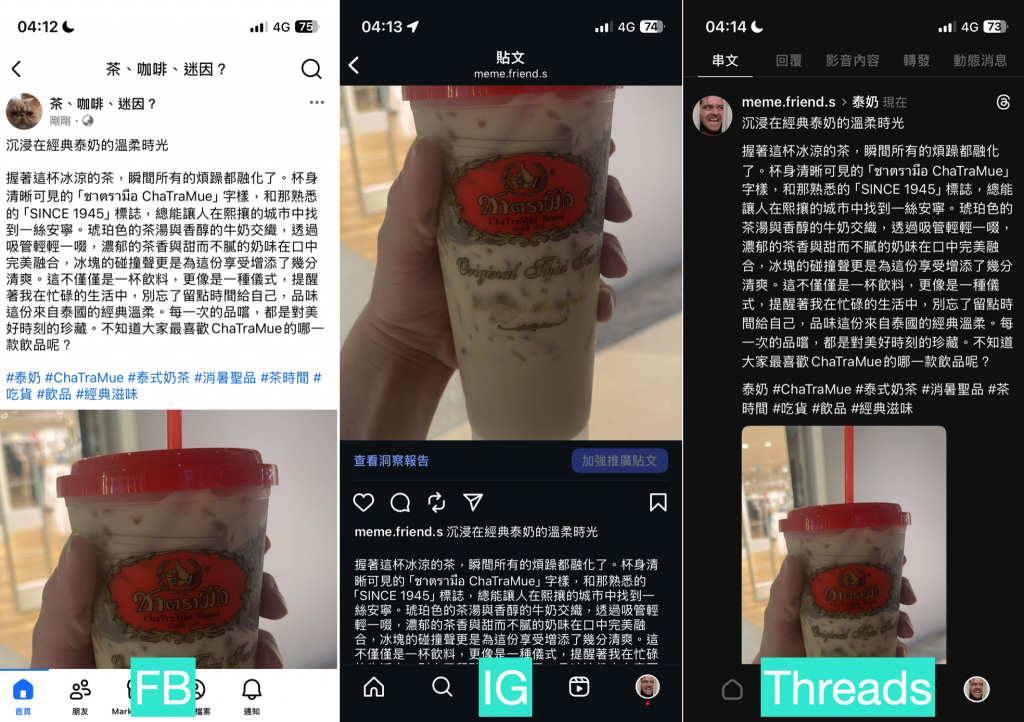
如果你追求極致的乾淨,那麼 子工作流 (Subworkflow) 會是你的救星。
n8n 有提供子工作流的功能,可以讓我們把某些流程包裝成一個獨立的子工做流去呼叫。
這邊有兩個重點:1. 子工作流如何設定、2. 如何呼叫子工作流
我個人會直接用 Accept all data,但如果你想把某些欄位的資料過濾掉、保持整潔的話,可以用(1)、(2)去自定義要接收哪些資料
注意:子工作流的 Input 最主要是接收呼叫前的「最後一個節點」所輸出的資料,如果要跨工作流取得資料也可以,但要設定成 Accept all data,而且參數的表示法名稱可能就要注意一下。所以我自己會選擇把我要的資料都往下傳(但 binary file 還是跨節點往下傳)。
以下為我將檔案獲取(含下載)、生成文案及URL、上傳 Meta 三個平台、檔案歸檔這四個步驟分別整理成四個子工作流的設定:
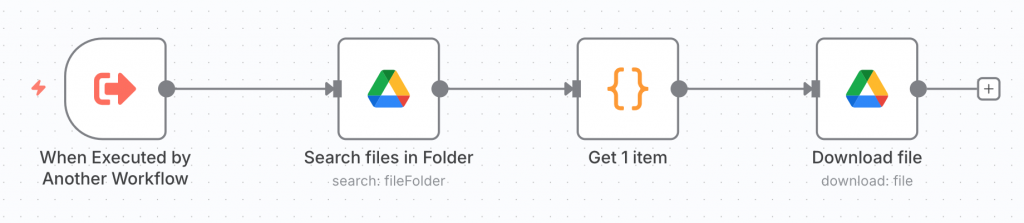
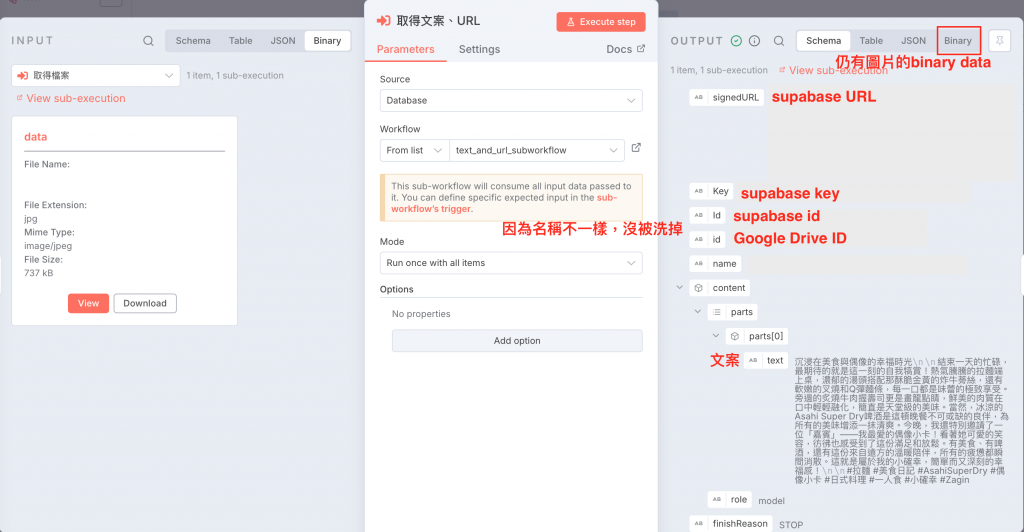
Download File 輸出的資料包含檔案在 Google Drive 上包含 ID 的資訊,以及圖片檔的 Binary File
b. 生成文案以及 URL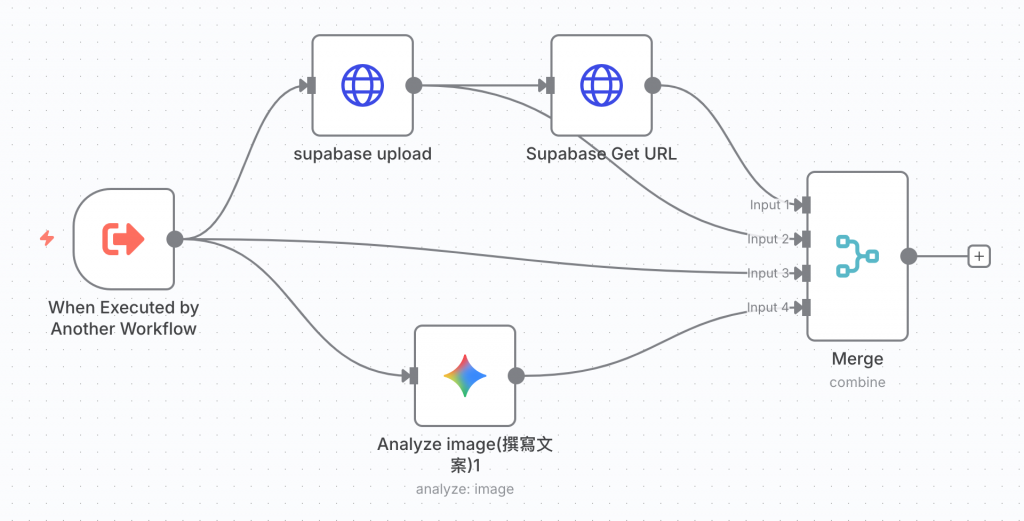
這邊要注意有兩件事:
(1) 因為後續歸檔需要 supabase 上面檔案的 Key,所以我從 supabase upload 拉一條到Merge 節點,會比較方便去取得資料。
(2) 因為臉書發文需要圖片檔案,而 Google Drive 歸檔需要有 Google Drive 上檔案的 ID,所以我也從 execute subworkflow 的節點直接拉一條到 Merge 節點中,同時將 Binary File 以及 id 往下傳地
總結來說,這道子工作流最後一個節點會輸出文案、URL、supabase 上檔案的 Key 、Google Drive 上檔案的ID 以及圖片檔
c. 上傳到 Meta 的三個平台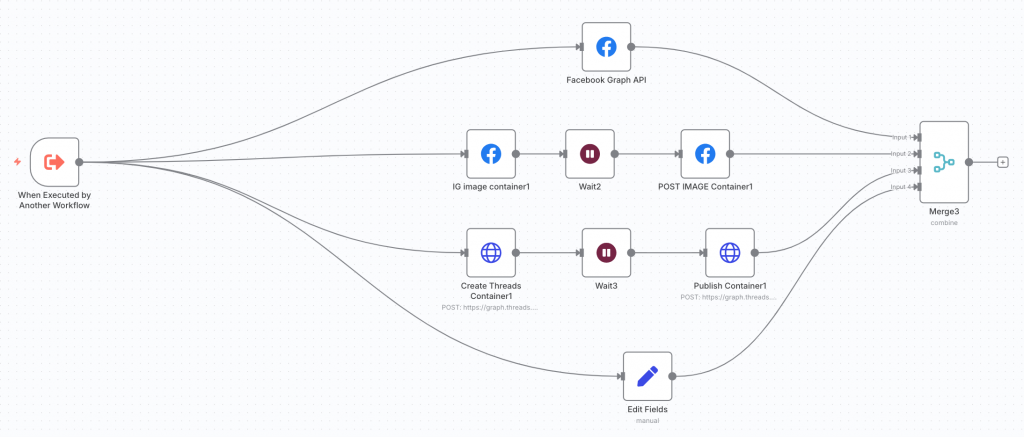
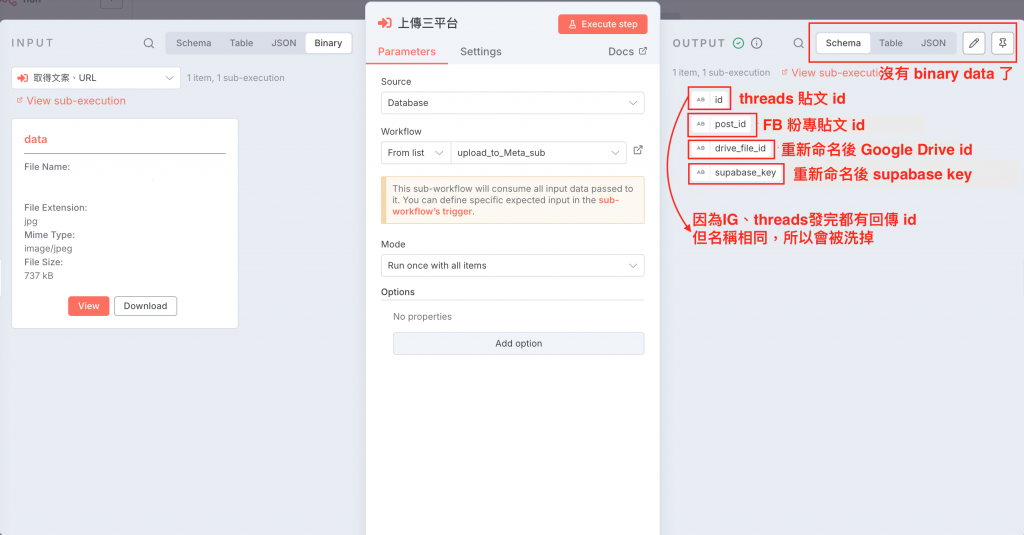
在 container 後面加上一個 wait 節點是要讓 container 準備完成,否則發布 container 時如果container 還沒準備完成會出現錯誤(要發影片的話,需要等久一點讓 container 準備完成)
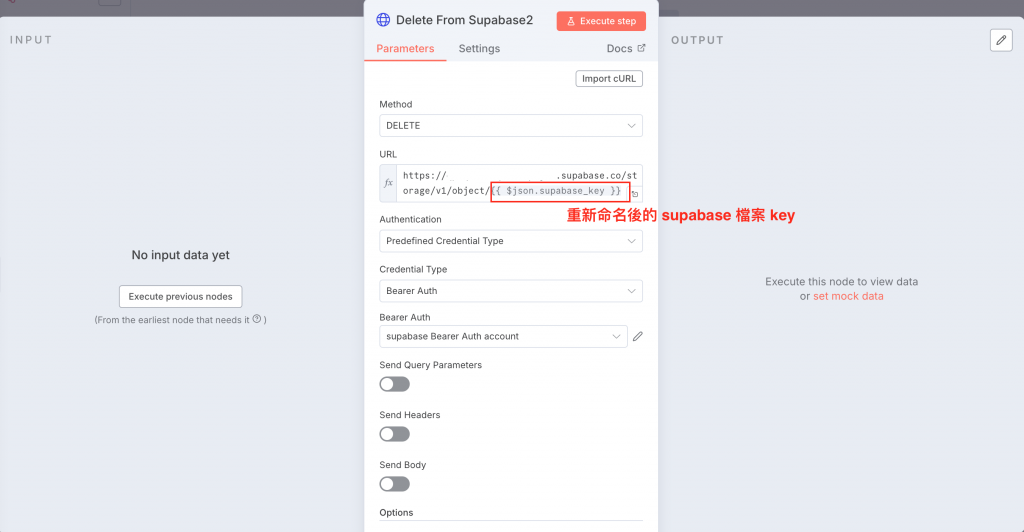
此外,因為 id 資料可能會被洗掉,而歸檔時需要 Google Drive 檔案 id 以及 supabase 檔案的 Key,所以我接一條 Edit Fields 的節點,將這兩個資料重新命名後傳到 Merge 節點再往下傳
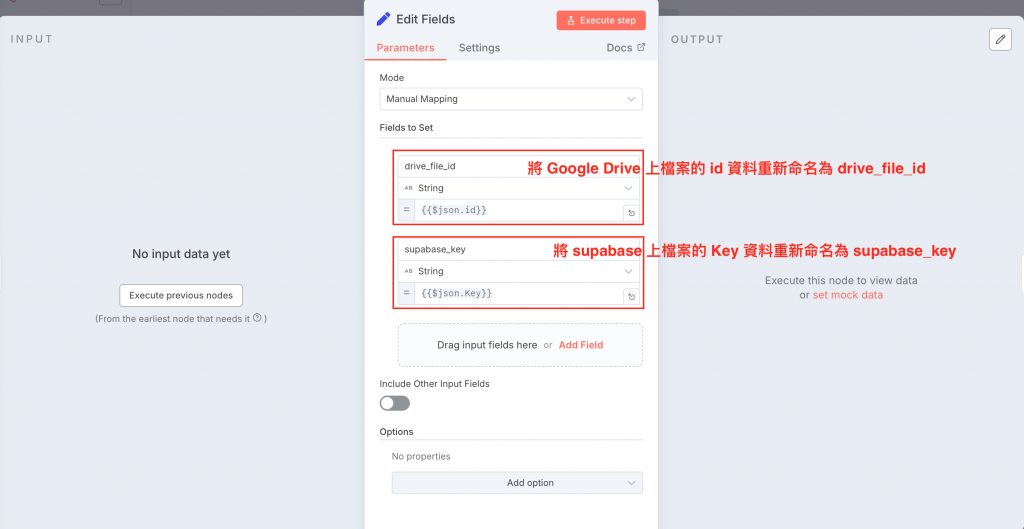
上方為此子工作流中 Edit Fields 的設定,主要是針對歸檔時所需的資料重新命名,以便調用。因為臉書節點發文完也會回傳 id ,不重新命名的話會覆蓋掉 Google Drive 的檔案 id
這邊其實因為三個平台上傳完輸出的 Data 後面不會再用到,所以沒有接到 Merge 也行
d. 歸檔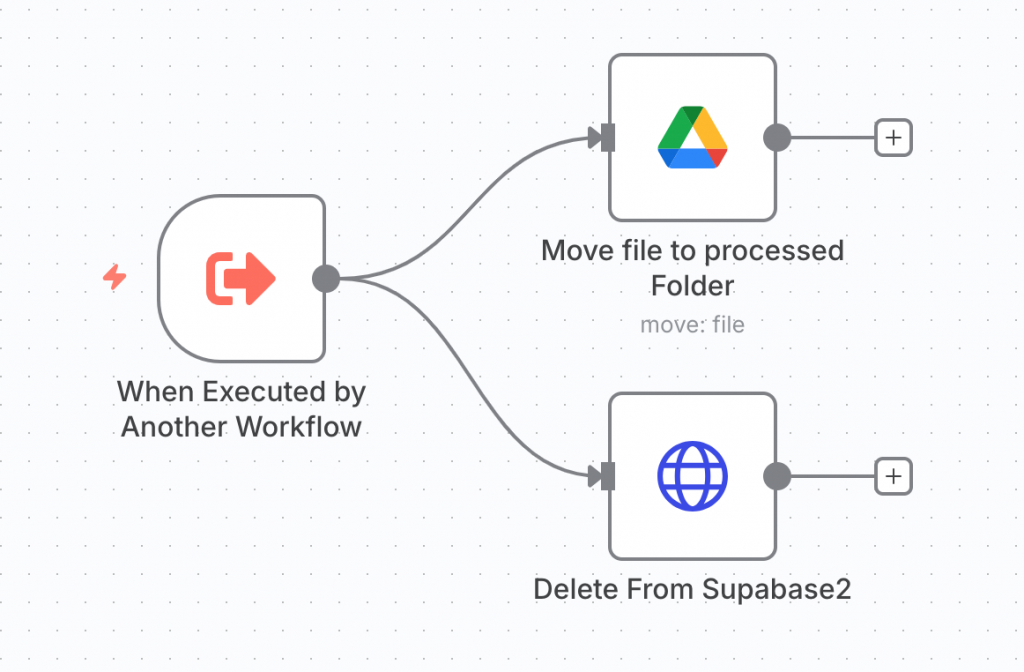
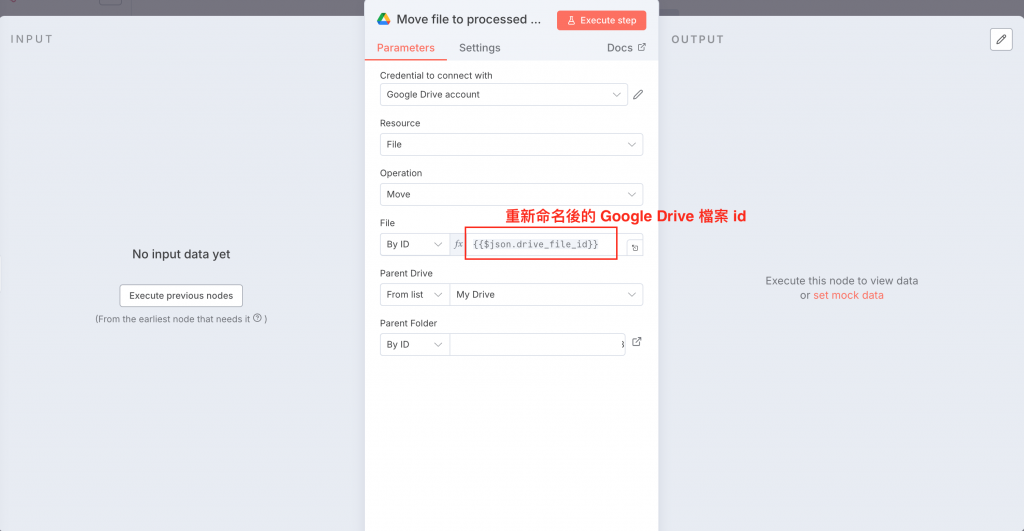
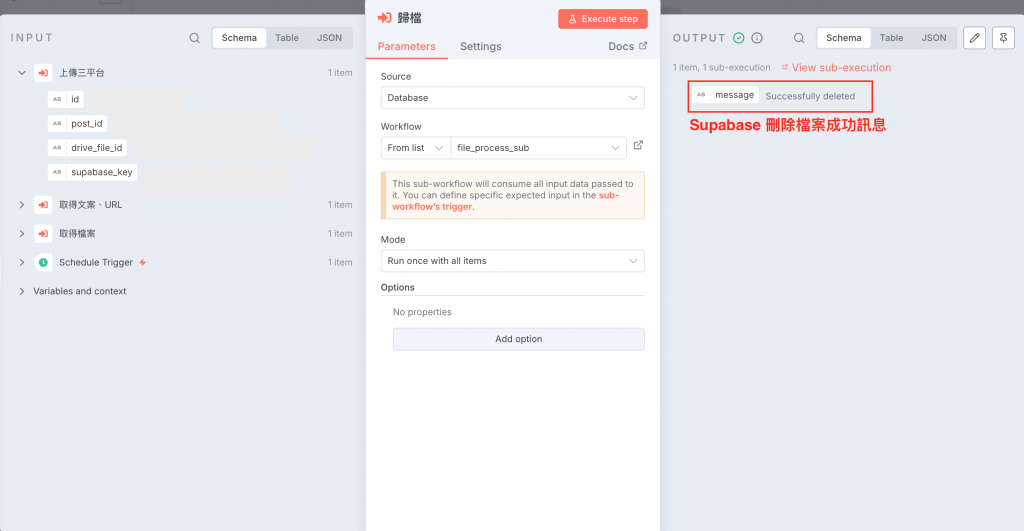
下圖為 Google Drive Move file 節點,我們需要調整成重新命名後的參數(如果直接接收前一個節點的資料,直接用 $json 就好)
下圖為 supabase delete file 節點,一樣調整成重新命名後的參數
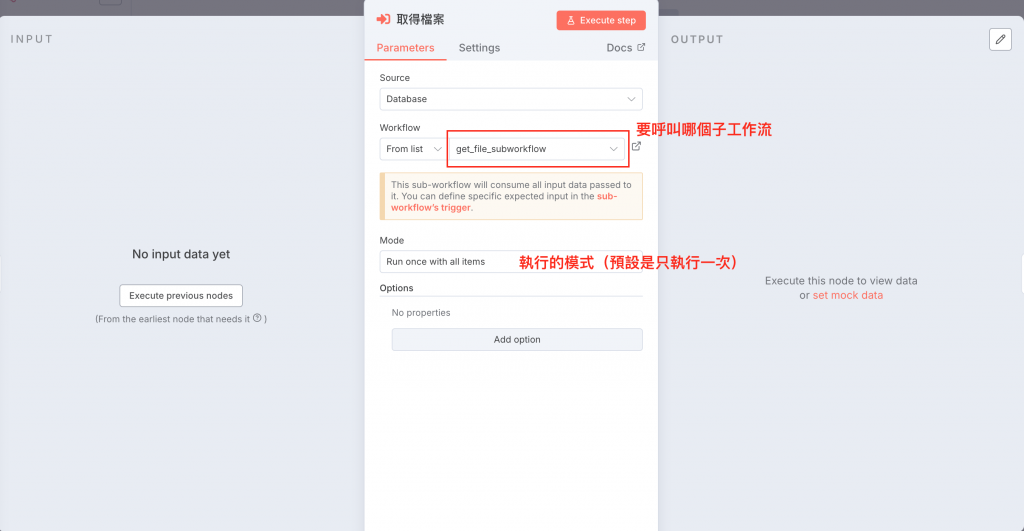
下面的示範中,我將檔案獲取(含下載)、生成文案及URL、上傳 Meta 三個平台、檔案歸檔這四個步驟分別整理成四個子工作流:
接著,在主工作流裡,只要接續呼叫這四個子工作流就好,這麼一來,主流程就會變得非常簡潔:
可以發現子工作流的設定會稍微需要動腦一點,就看你對於工作流的整潔度是否要很要求。
設計子工作流的關鍵是資料的流向,因為他跨子工作流去獲得資料會需要重新命名,所以我自己是確保有把要的資料往下傳,讓下一個子工作流可以直接收到,就可以直接用 $json 去調用。
以下為各個子工作流執行、資料輸入/輸出情況: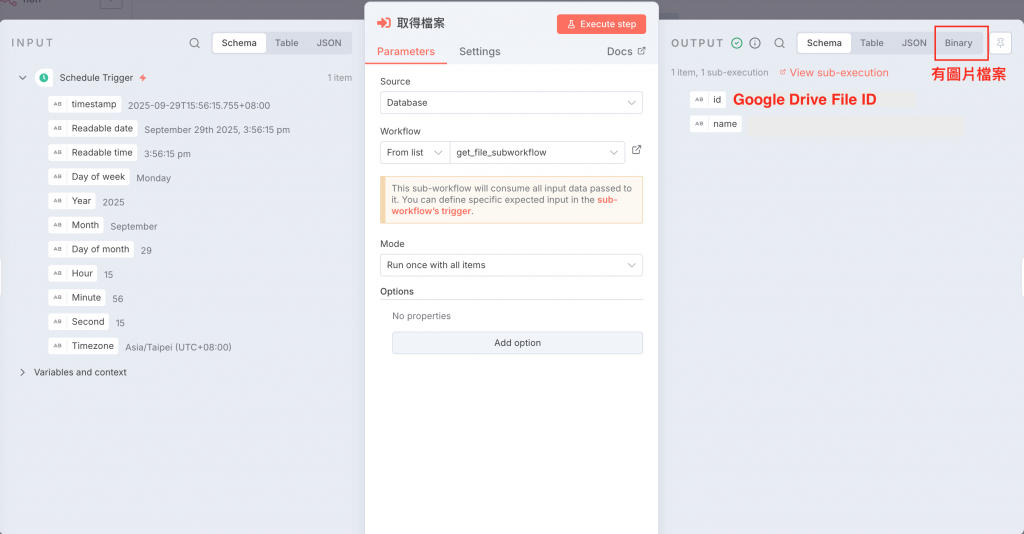
今天我們把 FB / IG / Threads 三個工作流整合成一個乾淨、可維護的主流程。同時,透過子工作流,我們能把「共用邏輯」與「平台專屬邏輯」分開,讓修改與擴充變得簡單。
而掌握了拆解工作流與子工作流的思維後,你可能會想:如果 n8n 沒有提供現成節點,我該怎麼做呢 ?別擔心,明天,我們將深入剖析 HTTP Request 節點,教你如何閱讀官方 API 文件,自己設計專屬的節點。
這樣,不管平台是否內建節點,你都能自主開發自動化流程,舉一反三,完全不受限!


 iThome鐵人賽
iThome鐵人賽