前面有介紹過一些傳統的指標像是精確率、召回率那些,不過那些指標都不能完整的反應 RAG 的效能,因為 RAG 的系統同時會牽涉到「檢索」與「生成」兩個部分,所以我們需要更具針對性的評估方式。
所以有專家學者就提出了 RAGAs(Retrieval-Augmented Generation Assessment) 框架,用來專門量化 RAG 系統的品質。其中也定義了三個核心的 RAG 特定品質指標:
這三個指標不僅是 RAGAs 的基礎,也能幫助我們更全面地評估 RAG 系統的表現,並在優化系統時提供具體的改善方向。接下來就讓我們來逐一介紹吧!
上下文相關性主要是用來評估檢索到的文件,跟你查詢的問題的關聯程度,之前就有說過,你檢索到的內容就是為了降低 LLM 的回答產生幻覺的機率,才需要檢索相關資訊補足它資訊不足的問題。
它會有幾個重點:主題一致性(檢索內容是否真的圍繞在查詢問題上)、資訊有用性(檢索內容裡是否包含能幫助回答問題的訊息)、冗餘度(檢索內容是否有太多不相關或多餘的句子)。
公式: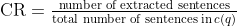
來源:Ragas: Automated Evaluation of Retrieval Augmented Generation
這邊解釋一下他的公式
也就是說,c(q) 就是 AI 為了回答問題 q,所找到的相關文件片段集合。這個公式要算的就是在它檢索到的內容當中,真的有助於回答問題的比例。
在檢索完相關資訊後,我們要看一下 LLM 有沒有在胡言亂語,會不會產出其實是跟檢索到的內容相互矛盾的。
這邊用公式來解釋它的做法,公式:
重點就是:答案中的每條「主張」是否 能由檢索到的上下文 c(q) 推導出來(可被支持)。
補充一下,若上下文本身有誤,答案仍可能在此指標拿高分;因此通常需要搭配 Answer relevance(是否答到題)與 Coverage(是否涵蓋該說的重點)一起看。
關於公式這邊可能需要解釋一下,假設我們的提問是:「LOL 的 Faker 是誰?他奪得世界冠軍幾次了?」,而 AI 產出的回應是:「Faker 本名李相赫,是韓國職業電競選手,總共贏得 5 次世界冠軍。」
每一段斜體都代表著一條一條主張(S),所以他的 |S| = 3,|V| 就是代表這些主張是否有在檢索的上下文中出現,希望這樣有比較好理解。
其實這邊的概念跟上下文相關性很像,只不過上下文相關性是上下文跟查詢,而答案相關性則是衡量產生出來的答案跟查詢的相關程度,重點要關注:
這邊一樣用公式來解釋它的做法,公式:
其實就是用答案產生的回應去反推原始問題,照道理來說應該是要差不多的。
今天先簡單介紹一下,明天來總結一下。

