這篇要來分享的是之前將 Effect 用在資料遷移的經驗,其實這篇就是「8. Effect 實戰分享 1 :資料清理」的後續,稍微前情提要一下,你拿到了一個老舊系統,系統上的資料都是存在 json 檔案中,你今天的目標是要將這些資料遷移到 db 中
在那時,我們提到了要保證資料遷移的幂等性,也就是多次執行同樣的動作,結果要保持一樣的這件事,我們這篇也會來提到
那就開始吧,在上次我們已經將資料都整理完了,接下來只要儲存起來就行了,我們先假設有個儲存的 function
// 關於 type 的定義請到上一篇去看,回傳值是在資料庫中的 id
function saveItem(item: Item): Effect<string, Error> {
// 裡面是儲存的實作細節
}
那我們上次提到這個老系統沒辦法一次讓你全部存進去,必須要一個一個的存,而且還要限制一下速度避免吃光系統資源,同樣的,我們可以用 Effect.all 去控制一下同時的 concurrency 數
import { Array } from 'effect'
pipe(
// 上一篇清理出來的資料
validData,
Array.map((item) => saveItem(item)),
Effect.allWith({ concurrency: 2, mode: 'either' })
)
先說為什麼要確保重覆執行不會導致重覆的資料,因為遷移過程有可能會因為錯誤或是其它原因而被中斷,雖然我們已經盡可能的確保我們有正確的處理錯誤了,但還是存在著疏漏的可能性,這時候重覆執行也不會造成重覆的資料就很重要
那麼要怎麼讓重覆執行不會產生重覆的資料呢?你有聽過增量備份嗎?簡單來說就是只備份從上次備份以來,有修改過的資料
那這要如何做到呢?我們可以有兩種做法
話說大家可能會想到,我們在前一篇中有提到我們這個系統中,有部份的資料已經在資料庫中,因此在前一篇的資料清理的過程中,我們還加入了檢查是否已經在資料庫的判斷,不過那僅限於一部份的資料,當時候的情況中,我們並不是所有的資料都能做到檢查是否已經在資料庫中的狀態
這邊來講第 2 種方法,另外記錄哪些資料已經遷移過,我們的邏輯很簡單,如果畫成流程圖就會如下
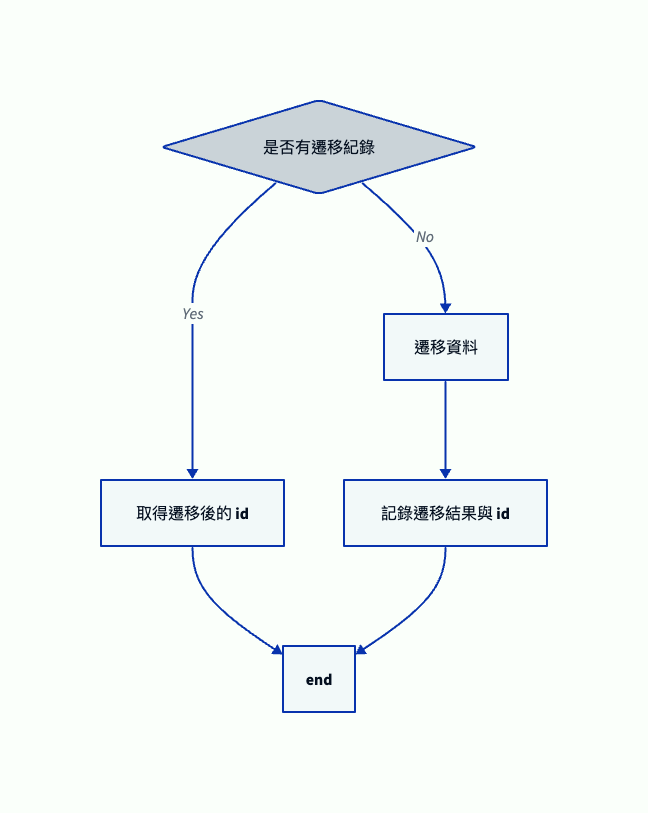
其實像這樣畫成流程圖就覺得沒有多複雜,而我們在遷移資料的流程在上面就已經完成了,接下來我們先來設計一下要保存的紀錄吧
const SaveRecordSchema = z.object({
// 檔案中的 id
localId: z.string(),
// 資料庫中的 id
databaseId: z.string(),
// 這筆紀錄新增的時間
timestamp: z.number(),
})
type SaveRecord = z.infer<typeof SaveRecordSchema>;
再來我們把紀錄的部份設計成一個 service
class RecordService extends Effect.Service<RecordService>()("RecordService", {
sync: () => ({
addRecord: (record: SaveRecord): Effect.Effect<void> => { /* 實作內容 */ },
getRecord: (localId: string): Effect.Effect<SaveRecord | null> => { /* 實作內容 */ },
}),
accessors: true,
}) {}
最後是整個流程
function saveWithRecord(
item: Item
): Effect.Effect<string, Error, RecordService> {
return Effect.gen(function* () {
const savedRecord = yield* RecordService.getRecord(item.id);
if (savedRecord) {
return savedRecord.databaseId;
}
const databaseId = yield* saveItem(item);
yield* RecordService.addRecord({
localId: item.id,
databaseId,
timestamp: Date.now(),
});
return databaseId;
});
}
再來我們只需要換掉原本直接呼叫 saveItem 的版本,就可以盡可能的避免出現重覆的資料了
import { Array } from 'effect'
pipe(
validData,
Array.map((item) => saveWithRecord(item)),
Effect.allWith({ concurrency: 2, mode: 'either' })
)
最後,在這個系統要開始遷移前,我們做了很多的測試與準備
其中有一個是我們在上線前做的小小的準備,確保這個系統在任何的資料缺少的情況下都能正常的處理而不會因此 crash ,這邊我們使用 deepPartial 建立有可能缺少欄位的 schema
const PartialItemSchema = deepPartial(ItemSchema)
然後我們再用 zod-fast-check 將 zod 的 schema 轉換成 fast check 的資料產生器
import { ZodFastCheck } from "zod-fast-check";
const itemArbitrary = ZodFastCheck().inputOf(PartialItemSchema);
現在你安裝可能會無法使用,這個案例當初實際發生時,使用的是 zod v3 ,而 zod-fast-check 也只支援 v3 ,還不支援 v4 ,如果你要實際測試,務必注意安裝的版本
之後我們將取得資料與儲存資料的部份都另外包裝成 service ,就可以用之前提過的 fast-check 測試我們的程式是否可以處理大部份欄位有缺少的情況了的資料了
import { it } from '@effect/vitest'
it.effect.prop('can handle missing fields', [itemArbitrary], (item) => {
// 測試 migrate 過程
})
這次的實戰分享就到這邊,我們主要看了冪等性的重要性與如何實作,還有如何模擬資料進行測試,下一篇要再來看 Effect 中如何使用 fork 在背景執行


 iThome鐵人賽
iThome鐵人賽