洛基走進茶室時,諾斯克大師已經在白板上展示一張圖表。
「這是星際政府軍官管理系統的資料模型,」大師說,「今天的任務是:把它轉換成 DynamoDB 的設計。」
洛基仔細看著白板上的 ER 圖:
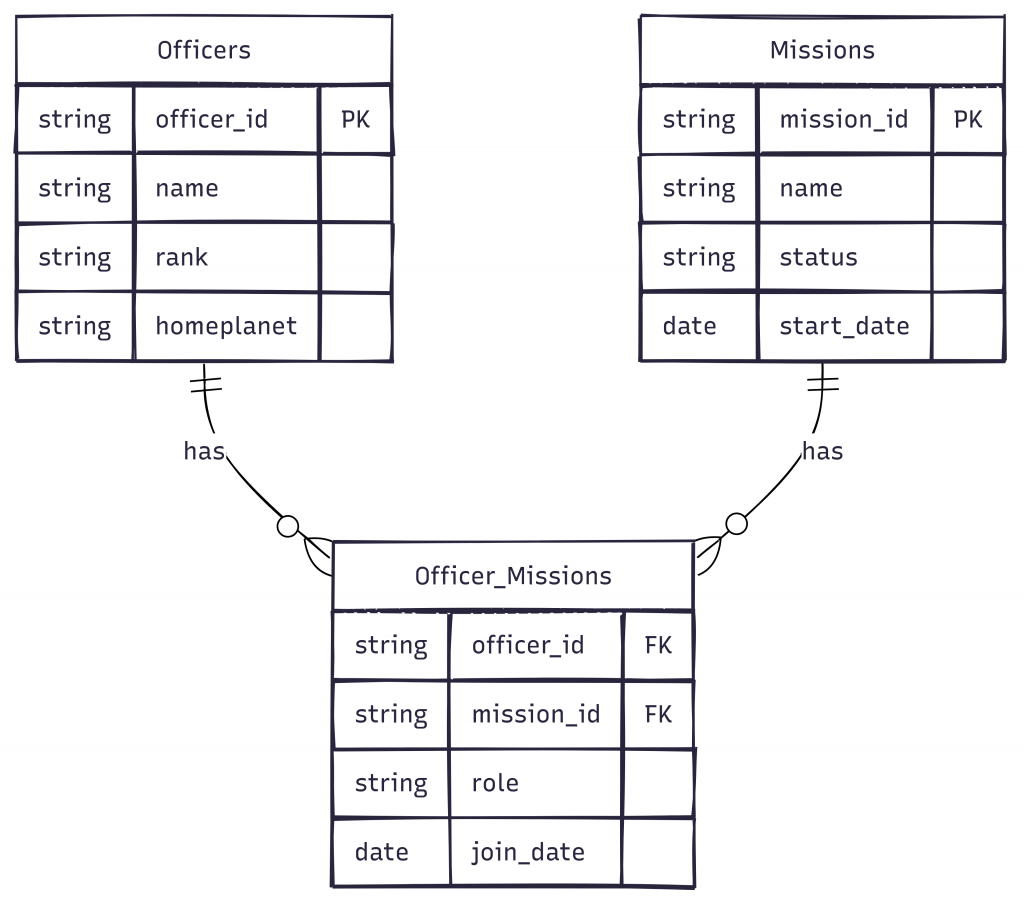
關聯關係說明:
role(在任務中的角色,如 commander, pilot)洛基想起第 6 天學到的多視角設計,若有所思地說:「這個系統...我記得您在第 6 天教過我資料重複的策略。所以我應該為不同的查詢需求建立多個視角?」
大師微笑:「你確實記得那個概念。但今天的挑戰不一樣——這次要處理的是複雜的關聯關係,不是單純的活動查詢。」
洛基遲疑了:「我...知道要用多視角,但具體怎麼處理這些關聯...」
「正是,」大師說,「第 6 天你學會了『思維』——資料重複不是問題而是策略。但今天我們要建立『系統方法』——如何面對複雜的 ER 圖,系統性地轉換成 DynamoDB 設計。實作是很好的老師,讓我們從實際動手開始。」
洛基拿起筆記本,開始設計表格結構:
// Officers 表
const officer = {
PK: 'OFFICER#alice',
SK: 'METADATA',
officerId: 'alice',
name: 'Alice Johnson',
rank: 'Captain',
homeplanet: 'Earth'
};
// Missions 表
const mission = {
PK: 'MISSION#mission001',
SK: 'METADATA',
missionId: 'mission001',
name: 'Mars Exploration',
status: 'active',
startDate: '2210-03-15'
};
// Officer_Missions 表(關聯表)
const officerMission = {
PK: 'OFFICER_MISSION#alice_mission001',
SK: 'METADATA',
officerId: 'alice', // 外鍵
missionId: 'mission001', // 外鍵
role: 'commander'
};
洛基抬頭回覆大師:「就我理解,應該是這樣的結構。」
大師問:「現在我要查詢:Alice 參與了哪些任務?」
洛基開始寫查詢邏輯:
// 洛基的查詢邏輯
async function getOfficerMissions(officerId) {
// 步驟 1:查詢 Officer_Missions 關聯表
const relations = await docClient.query({
TableName: 'IntergalacticEvents',
// 等等...怎麼查?PK 是 'OFFICER_MISSION#...'
// 我要怎麼找到所有 alice 的關聯?
}).promise();
// 步驟 2:對每個關聯,查詢任務詳情
// 但我要怎麼一次查詢多個任務?
// 而且...這不就是 JOIN 嗎?
}
洛基困惑地停下來:「等等,我要查詢『所有 officerId = alice 的關聯』,但 PK 是 OFFICER_MISSION#alice_mission001...」
大師引導:「你發現問題了?」
「我無法用 officerId 來查詢,」洛基說,「因為 officerId 不是 PK 也不是 SK。」
「對,」大師說,「DynamoDB 只能用 PK(和 SK)來查詢。那你打算怎麼辦?」
洛基想了想:「改變 PK 設計?讓 PK = OFFICER#alice?」
// 洛基的第二版嘗試
const officerMission = {
PK: 'OFFICER#alice',
SK: 'MISSION#mission001',
role: 'commander',
missionId: 'mission001' // 還需要這個來取得任務詳情
};
「好多了,」大師說,「現在你可以查詢 Alice 的所有任務關聯。但下一步呢?」
洛基繼續寫查詢邏輯:
async function getOfficerMissionsV2(officerId) {
// 步驟 1:查詢所有關聯
const relations = await docClient.query({
TableName: 'IntergalacticEvents',
KeyConditionExpression: 'PK = :pk AND begins_with(SK, :skPrefix)',
ExpressionAttributeValues: {
':pk': `OFFICER#${officerId}`,
':skPrefix': 'MISSION#'
}
}).promise();
console.log('找到的關聯:', relations.Items);
// [
// { PK: 'OFFICER#alice', SK: 'MISSION#mission001', missionId: 'mission001', role: 'commander' },
// { PK: 'OFFICER#alice', SK: 'MISSION#mission002', missionId: 'mission002', role: 'pilot' }
// ]
// 步驟 2:對每個任務 ID,查詢任務詳情
const missionDetails = [];
for (const relation of relations.Items) {
const mission = await docClient.get({
TableName: 'IntergalacticEvents',
Key: {
PK: `MISSION#${relation.missionId}`,
SK: 'METADATA'
}
}).promise();
missionDetails.push({
...mission.Item,
officerRole: relation.role
});
}
return missionDetails;
}
洛基執行測試:
找到的關聯: [
{ PK: 'OFFICER#alice', SK: 'MISSION#mission001', missionId: 'mission001', role: 'commander' },
{ PK: 'OFFICER#alice', SK: 'MISSION#mission002', missionId: 'mission002', role: 'pilot' }
]
查詢任務 mission001...
查詢任務 mission002...
完成!總耗時:45ms
「成功了!」洛基說,但隨即皺眉,「但是...」
大師問:「但是什麼?」
「這需要 3 次資料庫查詢,」洛基說,「1 次查關聯,2 次查任務詳情。如果 Alice 參與了 10 個任務,就需要 11 次查詢!」
「正是,」大師說,「在關聯式資料庫中,JOIN 操作讓你一次查詢就能拿到所有資料。但在 DynamoDB 中沒有 JOIN。」
大師在白板上畫了一個簡單的圖:
傳統資料庫(單機):
┌─────────────────────┐
│ Officers Table │
│ Missions Table │ ← JOIN 在記憶體中完成
│ Relations Table │ 毫秒級速度
└─────────────────────┘
分散式資料庫(多機):
┌──────────┐ ┌──────────┐ ┌──────────┐
│ Officers │ │ Missions │ │ Relations│
│ (Node1) │ │ (Node2) │ │ (Node3) │
└──────────┘ └──────────┘ └──────────┘
↓ ↓ ↓
└─────────網路傳輸(100-200ms)─────┘
↓
JOIN 需要:
1. 從 Node3 讀取關聯
2. 跨網路到 Node2 讀取 Missions
3. 跨網路到 Node1 讀取 Officers
= 300-600ms(還不包括處理時間)
「這就是為什麼分散式系統避免 JOIN,」大師解釋,「不是做不到,而是太慢、太不穩定。」
洛基問:「那 SQL 資料庫是怎麼做到快速 JOIN 的?」
「因為所有資料在同一台機器的記憶體中,」大師說,「但這意味著無法水平擴展。當資料量增長時...」
Hippo 補充:「當你的資料從 1GB 變成 1TB,單機資料庫就會氣喘噓噓了。但 DynamoDB 可以加機器,從 3 台變成 300 台。」
洛基若有所思:「所以這是一個取捨?」
「正是,」大師說,「讓我們看看這個取捨的本質:」
關聯式資料庫的世界觀:
┌─────────────────────────┐
│ 資料正規化(避免重複) │
│ JOIN 操作(關聯查詢) │
│ ACID 交易(強一致性) │
│ 垂直擴展(加強單機) │
└─────────────────────────┘
↓
適合場景:
- 資料量不大(< 1TB)
- 複雜查詢需求
- 強一致性要求
- 單一資料中心
DynamoDB 的世界觀:
┌─────────────────────────┐
│ 資料重複(查詢優化) │
│ 無 JOIN(單表設計) │
│ 最終一致性(彈性) │
│ 水平擴展(加機器) │
└─────────────────────────┘
↓
適合場景:
- 大規模資料(TB-PB)
- 簡單但高頻查詢
- 可容忍短暫不一致
- 全球分散部署
洛基問:「所以我不能用關聯式的思維來設計 DynamoDB?」
「不只是不能,」大師強調,「而是必須反過來思考。在關聯式資料庫中,你避免重複資料;在 DynamoDB 中,你擁抱重複資料。」
大師引導洛基重新審視需求:「讓我們回到最原始的問題:你要查詢什麼?」
洛基列出查詢需求:
查詢需求(Access Patterns):
1. 查詢軍官參與的所有任務
2. 查詢任務的所有參與軍官
3. 查詢軍官在特定任務中的角色
洛基突然想起第 6 天的學習:「等等...我想起來了!在第 6 天,我們設計活動系統時,您說過要『從查詢需求開始設計』,而不是從實體開始。所以我應該把任務的詳細資料直接放在關聯記錄裡?」
「很好,你記起來了,」大師說,「但這次不同的是——第 6 天是單一實體的多視角查詢,而現在是多實體的關聯關係。你需要系統性地思考如何轉換每一種關聯類型。」
// 洛基的頓悟設計
const officerMissionWithDetails = {
PK: 'OFFICER#alice',
SK: 'MISSION#2210-03-15#mission001',
// 關聯資訊
role: 'commander',
joinDate: '2210-03-10',
// 任務詳情(重複資料!)
missionId: 'mission001',
missionName: 'Mars Exploration',
missionStatus: 'active',
startDate: '2210-03-15',
// 現在一次查詢就能拿到所有資訊!
};
「對!」大師讚許,「這就是 DynamoDB 的思維方式。」
洛基點頭:「這個模式我在第 6 天有學過——資料重複來優化查詢。但那時只是在活動系統中重複一些基本資訊...現在面對複雜的 ER 關係,我要重複的資料規模和更新的複雜度都高很多。」
「正是,」大師說,「這就是系統性思維的關鍵。第 6 天你理解了『為什麼要重複』,但現在要理解『在複雜關聯中如何系統性地決定重複什麼、不重複什麼』。這就是取捨的藝術。」
Hippo 拿出一個實際的例子:「讓我們算算看成本。」
場景:查詢 Alice 參與的所有任務(Alice 參與了 10 個任務)
方案 A:關聯式設計(需要 JOIN)
┌────────────────────────────────┐
│ 查詢步驟: │
│ 1. Query Officer_Missions │ 20ms
│ 2. Get Mission#001 │ 15ms
│ 3. Get Mission#002 │ 15ms
│ 4. Get Mission#003 │ 15ms
│ ... (共 10 次) │
│ 總計:20 + 15×10 = 170ms │
│ 網路請求:11 次 │
│ 消耗 RCU:1 + 10 = 11 │
└────────────────────────────────┘
方案 B:資料重複設計(無 JOIN)
┌────────────────────────────────┐
│ 查詢步驟: │
│ 1. Query OFFICER#alice │ 20ms
│ (返回 10 個帶完整資料的項目) │
│ 總計:20ms │
│ 網路請求:1 次 │
│ 消耗 RCU:1 │
└────────────────────────────────┘
效能提升:
- 速度:170ms → 20ms(8.5 倍)
- 請求數:11 → 1(減少 91%)
- 成本:11 RCU → 1 RCU(減少 91%)
洛基訝異地說:「差這麼多!」
「而且這還是樂觀情況,」Hippo 說,「如果網路不穩定,11 次請求中任何一次失敗,整個查詢就失敗。」
大師補充:「在分散式系統中,每次網路請求都是風險。減少請求次數不只是優化,更是可靠性的保證。」
洛基重新審視整個 ER 圖,開始用新的思維方式設計:
// 洛基的 DynamoDB 設計思維
// Access Pattern 1: 查詢軍官參與的所有任務
{
PK: 'OFFICER#alice',
SK: 'MISSION#2210-03-15#mission001',
role: 'commander',
missionId: 'mission001',
missionName: 'Mars Exploration',
missionStatus: 'active',
startDate: '2210-03-15'
// 一次查詢拿到所有資訊
}
// Access Pattern 2: 查詢任務的所有參與軍官
{
PK: 'MISSION#mission001',
SK: 'OFFICER#alice',
role: 'commander',
officerId: 'alice',
officerName: 'Alice Johnson',
officerRank: 'Captain',
homeplanet: 'Earth'
// 反向索引,同樣一次查詢解決
}
「我理解了!」洛基說,「每個 Access Pattern 都設計成一次查詢就能完成!」
大師點頭:「這就是 DynamoDB 設計的核心原則。」
洛基問出了一直困擾他的問題:「但如果任務名稱改了,我要更新多少地方?」
大師拿出實際例子:
// 任務名稱更新的影響分析
async function updateMissionName(missionId, newName) {
// 需要更新的地方:
// 1. 任務的主記錄
await docClient.update({
TableName: 'IntergalacticEvents',
Key: { PK: `MISSION#${missionId}`, SK: 'METADATA' },
UpdateExpression: 'SET missionName = :name',
ExpressionAttributeValues: { ':name': newName }
}).promise();
// 2. 查詢所有參與這個任務的軍官
const participants = await docClient.query({
TableName: 'IntergalacticEvents',
KeyConditionExpression: 'PK = :pk AND begins_with(SK, :skPrefix)',
ExpressionAttributeValues: {
':pk': `MISSION#${missionId}`,
':skPrefix': 'OFFICER#'
}
}).promise();
// 3. 更新每個軍官視角中的任務記錄
for (const participant of participants.Items) {
// participant.SK 包含完整的 SK,如 'OFFICER#alice'
const officerId = participant.SK.replace('OFFICER#', '');
// 需要找到對應的 OFFICER -> MISSION 記錄並更新
// 這裡需要知道完整的 SK (包含日期),通常會在 participant 中儲存
await docClient.update({
TableName: 'IntergalacticEvents',
Key: {
PK: `OFFICER#${officerId}`,
SK: `MISSION#${participant.startDate}#${missionId}` // 使用完整 SK
},
UpdateExpression: 'SET missionName = :name',
ExpressionAttributeValues: { ':name': newName }
}).promise();
}
}
「看起來很複雜,」洛基說。
「確實,」大師承認,「但問題是:任務名稱多久改一次?你多久查詢一次軍官的任務列表?」
洛基思考:「改名稱可能幾個月一次,但查詢可能每秒上千次...」
「這就是關鍵,」大師說,「在 DynamoDB 中,你優化的是讀取,而不是寫入。」
讀寫比例的現實:
┌─────────────────────────┐
│ 典型應用的讀寫比例: │
│ │
│ 讀取:90-99% │
│ 寫入:1-10% │
│ │
│ DynamoDB 的策略: │
│ "讓讀取極快,寫入可以慢" │
└─────────────────────────┘
洛基問:「如果我就是需要強一致性呢?比如銀行帳戶餘額,不能有任何延遲或不一致?」
大師嚴肅地說:「那就是 DynamoDB 不適合的場景。」
選擇正確的工具:
┌─────────────────────────────────┐
│ 使用 DynamoDB: │
│ ✅ 大規模資料(TB-PB) │
│ ✅ 讀多寫少 │
│ ✅ 可容忍短暫不一致 │
│ ✅ 需要水平擴展 │
│ ✅ 簡單查詢模式 │
│ │
│ 使用關聯式資料庫: │
│ ✅ 需要複雜 JOIN │
│ ✅ 需要強一致性 │
│ ✅ 資料量適中(< 1TB) │
│ ✅ 寫入頻繁且複雜 │
│ ✅ 需要臨時查詢 │
└─────────────────────────────────┘
「沒有完美的資料庫,」大師說,「只有適合的場景。」
洛基問:「那如果我既需要大規模擴展,又需要強一致性呢?」
「那你可能需要 DynamoDB Transactions,」大師說,「或者混合架構:DynamoDB 處理大量讀取,關聯式資料庫處理關鍵交易。」
經過一整天的學習,洛基在筆記本上寫下他的領悟:
關聯式思維 vs DynamoDB 思維
關聯式資料庫:
1. 從實體開始設計(Users, Orders, Products)
2. 建立關聯關係(外鍵)
3. 正規化資料(避免重複)
4. 用 JOIN 查詢資料
5. 優化:加索引、調整 SQL
DynamoDB:
1. 從查詢開始設計(Access Patterns)
2. 直接設計資料結構支援查詢
3. 擁抱資料重複(優化讀取)
4. 避免多次查詢
5. 優化:重新設計 PK/SK
核心差異:
關聯式:「我有什麼資料?」
DynamoDB:「我要怎麼查詢資料?」
大師看著洛基的筆記,滿意地點頭:「你已經理解最根本的差異了。」
洛基恍然大悟:「我現在明白為什麼第 6 天的時候,您說『Access Pattern 優先』。當時我只是記住了概念,但沒有真正理解它在面對複雜 ER 關係時的威力。現在我理解了——不是簡單的資料重複,而是系統性地從關聯關係中提取查詢需求,然後設計支援這些需求的資料結構。」
「正是如此,」大師說,「第 6 天你學會了『思維轉換』,今天你學會了『系統方法』。只有當你嘗試轉換複雜的 ER 圖時,才會真正理解這兩者的結合。」
大師給洛基一個新的挑戰:「現在設計這個查詢:查看 Captain 級別的所有軍官及其目前任務。」
洛基立刻想到第 6 天學到的多視角設計:「我可以建立一個按職級查詢的視角!」
// 洛基的第一直覺:建立 RANK 視角
{
PK: 'RANK#Captain',
SK: 'OFFICER#alice',
officerId: 'alice',
officerName: 'Alice Johnson',
homeplanet: 'Earth',
currentMission: {...}
}
「這樣就能高效查詢所有 Captain 了!」洛基說完,突然停頓了一下。
大師問:「你想到什麼問題了?」
洛基皺眉:「如果 Alice 升職了,從 Captain 變成 Commander...」
他開始在筆記本上寫出更新步驟:
// Alice 升職時的更新操作
async function promoteOfficer(officerId, newRank) {
// 1. 從舊 rank 視角中刪除
await docClient.delete({
TableName: 'IntergalacticEvents',
Key: {
PK: 'RANK#Captain',
SK: `OFFICER#${officerId}`
}
}).promise();
// 2. 在新 rank 視角中新增
await docClient.put({
TableName: 'IntergalacticEvents',
Item: {
PK: 'RANK#Commander',
SK: `OFFICER#${officerId}`,
// ... 完整的軍官資料
}
}).promise();
// 3. 更新主記錄
await docClient.update({
TableName: 'IntergalacticEvents',
Key: {
PK: `OFFICER#${officerId}`,
SK: 'METADATA'
},
UpdateExpression: 'SET rank = :rank',
ExpressionAttributeValues: { ':rank': newRank }
}).promise();
// 4. 更新所有任務視角中的 rank 資訊...
}
洛基看著這段程式碼,若有所思:「升職需要刪除舊視角、建立新視角、更新主記錄...如果軍官很多,這個操作會很複雜。而且在第 7 天我已經體驗過,屬性變更需要跨視角更新的痛苦了。」
「很好的觀察,」大師說,「你發現了什麼?」
洛基整理思緒:「多視角設計很適合『相對固定的屬性』,像星球、主題這種不太會變的。但對於『會變動的屬性』,比如職級、狀態,每次變更都需要移動資料,維護成本很高。」
他停頓了一下,接著說:「在第 7 天,我們遇到過類似的問題——活動狀態從 AVAILABLE 變成 FULL 時,需要跨視角移動資料。那時候您說這是多視角設計的權衡。」
「正是,」大師說,「你還記得第 8 天的優先級分析嗎?」
洛基點頭:「當時我們決定『狀態查詢』不建立專門視角,而是用 Scan + Filter,就是因為狀態變更的維護成本太高。」
「對,」大師說,「但現在的情況有點不同。如果按職級查詢是一個核心級查詢(高頻且重要),用 Scan 的成本又太高。這時候你就會想:有沒有第三種方法?」
洛基思考片刻:「第三種方法...既能高效查詢,又不需要在屬性變更時移動資料?」
大師微笑:「這就引出了一個我在第 2 天簡單提過的工具。」
洛基回想:「第 2 天...您提到過全域次要索引?」
「沒錯,」大師說,「還記得我在第 2 天提到的嗎?當你需要按非主鍵的欄位查詢,可以用全域次要索引。」
「GSI...」洛基複述這個詞,「但我不知道怎麼設計。」
「沒關係,」大師說,「讓我展示一個可能的設計方向。」
// 大師展示的設計範例
{
PK: 'OFFICER#alice',
SK: 'METADATA',
rank: 'Captain',
name: 'Alice Johnson',
// 大師:「可以設計一個索引,用 rank 作為查詢鍵」
GSI1PK: 'RANK#Captain',
GSI1SK: 'OFFICER#alice'
}
// 大師示範查詢
const captains = await docClient.query({
TableName: 'IntergalacticEvents',
IndexName: 'GSI1',
KeyConditionExpression: 'GSI1PK = :rank',
ExpressionAttributeValues: {
':rank': 'RANK#Captain'
}
}).promise();
// 然後對每個軍官查詢其任務
for (const captain of captains.Items) {
const missions = await docClient.query({
TableName: 'IntergalacticEvents',
KeyConditionExpression: 'PK = :pk AND begins_with(SK, :sk)',
ExpressionAttributeValues: {
':pk': `OFFICER#${captain.officerId}`,
':sk': 'MISSION#'
}
}).promise();
}
洛基看著程式碼:「我看到了語法...但為什麼 GSI1PK 要設計成 RANK#Captain 這樣的格式?而且還有 GSI1SK...這些是什麼規則?」
「這就是索引設計的核心,」大師說,「但現在還不是深入的時候。你先記住:當主表設計無法滿足查詢需求時,索引是一個可能的解法。至於如何設計、何時使用、成本如何控制——這些是後面課程的重點。」
洛基點頭,在筆記本上寫下:「索引可以解決按非主鍵查詢的問題,但我還不理解設計原則。」
大師繼續說:「如果你只需要目前的任務呢?還有更優化的方式。」
// 大師展示的優化方案:在軍官記錄中直接存儲目前任務
{
PK: 'OFFICER#alice',
SK: 'METADATA',
rank: 'Captain',
name: 'Alice Johnson',
// 目前任務資訊(重複但優化查詢)
currentMission: {
missionId: 'mission001',
missionName: 'Mars Exploration',
role: 'commander',
startDate: '2210-03-15'
},
GSI1PK: 'RANK#Captain',
GSI1SK: 'OFFICER#alice'
}
// 現在一次查詢就能拿到所有 Captain 及其目前任務!
「這就是 DynamoDB 思維:為最常見的查詢優化資料結構,」大師說,「至於索引的詳細設計,等你掌握了關聯關係的基礎後,我們再深入探討。」
洛基看著筆記本上的 GSI 範例,心裡清楚:「我知道『有這個工具』,但完全不知道『怎麼正確使用它』。」
大師看著洛基已經理解了核心概念:「今天你明白了『為什麼 ER 圖不能直譯』,明天我們要學習『如何做設計選擇』。」
「設計選擇?」洛基問。
「一對一、一對多、多對多,」大師說,「在 SQL 中,ER 圖上畫一條線就知道要開幾個表。但在 DynamoDB 中,同樣的一條線,卻有多種設計策略可以選擇。」
洛基若有所思:「所以重點不是『怎麼寫程式碼』,而是『怎麼選擇策略』?」
「正是,」大師微笑,「但我們不會從今天這個複雜的多對多開始。」他在白板上擦掉 Officers-Missions 的 ER 圖,重新畫了一個簡單的關係,「明天,我們從最簡單的一對一關係開始——學會判斷何時嵌入、何時分離。然後一步步推進到一對多、多對多。」
洛基點頭:「從基礎建立判斷框架。」
「對,」大師說,「今天用多對多讓你看見 SQL 思維的限制,明天開始,我們系統性地重建 DynamoDB 的設計思維。每種關係類型,都有它的決策點。」
走出茶室時,洛基回頭看了看白板上的 ER 圖。那些曾經熟悉的箭頭和關聯線,現在看起來像是問號——每條線都在問他:「你會怎麼設計我?」
他在心中默念:「不是『ER 圖說什麼我就做什麼』,而是『根據查詢需求做出選擇』。這就是 DynamoDB 的設計智慧。」
時間設定說明:故事中使用星際曆(SY210 = 西元2210年),程式碼範例為確保正確執行,使用對應的西元年份。

