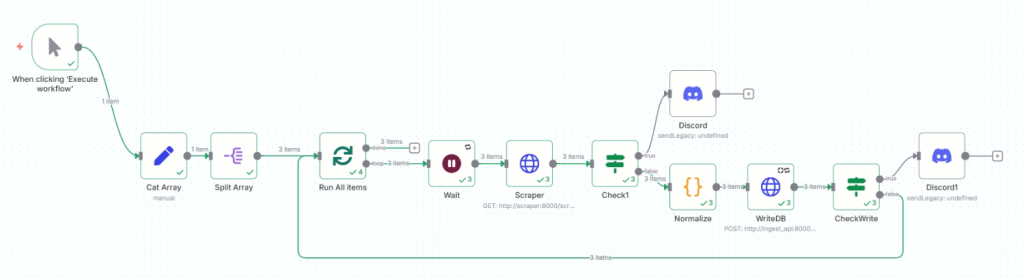
我們昨天終於成功寫入資料庫了,現在把n8n流程串在一起,那我們定期爬蟲寫資料庫就初步完成了。
在寫入資料庫前,我要先將拿到的資料進行正歸化,也就是將這些東西轉換成我們資料庫可以吃的。
有幾個重點:
欄位一致化:不同來源欄位名稱不一樣,若不統一,下游查表、JOIN、去重都要寫分支。把不同來源的 product_code / raw.code 統一成 gu_id,名稱統一到 name,避免下游還要判斷多種欄位名。
型別正確化::字串/boolean 混用容易在 DB/分析階段出錯(例如數值排序、聚合)。 價格用 Number(...) 轉數字、in_stock 僅允許 true/false,captured_at 固定 ISO 字串,降低 DB 型別錯誤。
缺值處理與保底:實務資料常有缺漏;直接丟進 DB 容易觸發 not-null/型別錯誤或造成分析 noisy。name 缺失就退回 gu_id,url、list_price 不存在就設 null,確保每筆資料都有可預期的值。
資料過濾:必須同時有價格與代碼。避免髒資料入庫、影響統計。
一致的時間戳:同一次批次共用 nowIso,方便追蹤「這一批」的抓取時間,利於稽核與回溯。
來源標記:固定 source: 'tw_site',之後可跨來源比對或除錯。
結構穩定:categories 一律是陣列(有值則 [cat],否則 []),方便後續擴充成多分類、不必改 schema。
降低下游複雜度:把判斷邏輯丟到每個消費端,會造成重複與不一致。HTTP/DB 節點可以直接拿 payload 入庫,少寫判斷邏輯、錯誤率更低。
完成了以上正歸化 才能接我們的寫入資料庫。
跟之前同樣的想法,寫入資料庫後也要檢查是否成功。
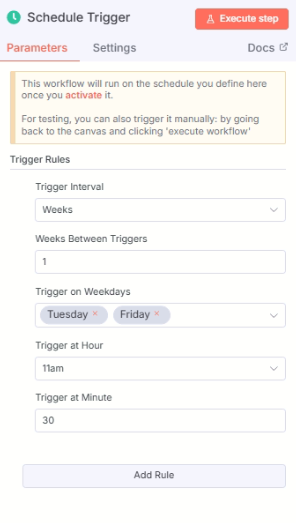
為了之後它能夠幫我們定時自動跑這流程,我們需要設立 Schedule Trigger。
同時並把右上的Active打開,這樣時間一到,它就會幫我們跑這workflow了。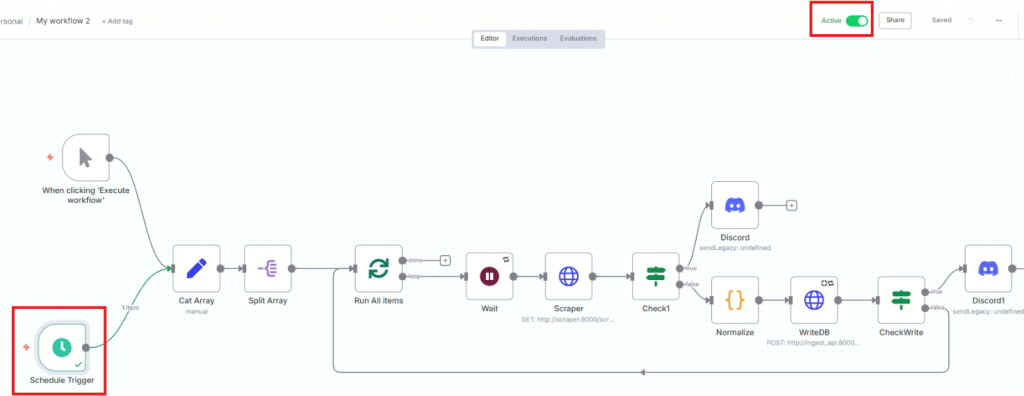
Done (͡ ͡° ͜ つ ͡͡°)

