昨天Claude剛推出最新的sonnet 4.5,我們就來做個模型的優勢比較和下提示做遊戲測試各個模型的呈現效果,看看目前誰寫程式最有效率~
GPT-5智能路由 vs Gemini 2.5 Pro編程優勢 vs Claude Sonnet 4.5解釋性王者
決定 AI 模型運行效果的關鍵要素有三個:數據、硬體和科學。Google 是唯一一家能夠實質性地做到其中兩項的公司。
Google 擁有龐大的數據優勢,這對於訓練出色的 AI 模型十分重要。
• 無限的數據集: Google 擁有數十年運行網路所產生的無限數據集。
• 無需外部採購: 與其他必須從 Data Curve 或 Scale AI 等公司購買數據的科學團隊不同,Google 不需要從外部購買數據。
Google 在機器學習和大型語言模型 (LLM) 的科學領域擁有深厚的歷史。
• 頂尖人才與技術: Google 擁有世界上一些最優秀的科學家,正在建立令人難以置信的技術。
• 歷史累積: Google 在歷史上一直是資訊領域的領導者。有人認為 Google 翻譯就是 LLM 的首批真實範例之一。
• 內建思考能力: Gemini 2.5 是一個思考模型。Google 正在將這些思考能力直接內建到所有模型中,使其能夠處理更複雜的提示。
Google 是唯一一家自己製造硬體的大型 AI 公司(OpenAI 和 Anthropic 沒有這樣做)。
• 自訂 Google 晶片: 由於 Google 不會將其模型作為開源發布供其他人在 NVIDIA GPU 上運行,他們可以假設其模型將永遠運行在他們自訂的 Google 晶片上。這個假設讓他們可以做許多其他公司無法合理做到的事情。
• 科學與硬體的緊密結合: Google 的科學家可以與硬體人員並肩工作,以確保模型被構建得能夠在他們正在製作的自訂硬體上盡可能好地運行。這種科學與硬體之間超級緊密的關係是其他公司所缺乏的。
Google 對這些核心要素的整合,轉化為其模型在性能、速度和價格上的顯著競爭優勢:
Google 模型在基準測試中展現出驚人的結果:
• Gemini 2.5 Pro 的表現: 該模型在發布後立即在 LLM Arena 排名第一,甚至擊敗了 GPT-4.5 和 Deep Seek。它在人文最後考試(humanity last exam)中擊敗了 OpenAI 03 Mini High,這是一個由 OpenAI 建立的基準。
• 突破性速度: 擁有突破性模型和突破性速度目前是Google 獨有的事情。
• Gemini Flash 的速度: Gemini Flash 速度極快,以至於不將其設為預設模型「幾乎感覺是不負責任的」。在「智慧與速度圖表」上,只有 2.0 Flash 位於綠色區域。
Google 在價格方面也處於領先地位。
• 極低的成本: Gemini Flash Light 便宜得可笑。
• 巨大的價格差距: 將 Flash 與性能相似的模型(如 4.0)相比,它的輸入和輸出 token 成本便宜了 25 倍。
• 實際成本案例: 在 T3 Chat 中,發送 100 萬條 Gemini 訊息大約花費 1,200 美元,相比之下,Claude 收到的訊息不到一半,但成本卻高達 31,000 美元。由於 Gemini 既便宜又快,發言者計劃將其從 T3 Chat 的訊息限制中移除。
Google 模型具備多項功能,使其成為更好的預設模型選項:
• 巨大的上下文視窗: 提供 100 萬個 token 的輸入上下文視窗,這是一個被低估但令人難以置信的功能,且200 萬個上下文視窗也即將到來。
• 多媒體處理能力: 具有原生的 PDF 支援,能夠解析 PDF 中荒謬數量的頁面、圖像、圖表和曲線圖。它也具有圖像解析和最近新增的圖像編輯功能。
• 基礎功能(Grounding): 這是 Google 內部對「搜尋」的代號。
Google 擁有 Google Cloud Platform (GCP) 這一雲端平台。
• 鎖定生態系統: 由於 Google 擁有 GCP,Google 永遠不會允許用戶在另一個雲端(如 AWS 或 Azure)中使用他們的模型。
• 捆綁式 API 銷售: Google 的目標是贏得勝利,因此他們不會單獨出售任何一個組成部分(數據、科學、硬體),而是將整個系統捆綁起來作為 API 出售給客戶。
總結來說,Google 在數據、科學、硬體三方面的獨家掌握和高度協同,使其能夠以競爭對手無法比擬的速度、性能和價格優勢推出新的突破性模型,這奠定了他們在 AI 競賽中主導地位的基礎。
資料來源強調,GPT-5 最大的突破並非僅在於其智能程度,而在於其獨立工作的能力和持續時間。
• 極高的工作持續性: GPT-5 能夠連續工作超過兩個小時,失敗率才會高於 50%。這被視為該領域取得的實際進展的「神奇圖表」。
• 效率高: 在完成如Pokemon Red這類任務時,GPT-5 只用了 GPT-3 所需步驟的 33%,僅需 6,500 步即可完成。
• 任務複雜度增加: 由於獨立工作時間的延長,AI 現在可以完成更複雜的任務,例如在幕後修復小型 Python 庫中的錯誤、從具有反機器人保護的網站抓取記錄,甚至發現庫中的緩衝區溢出(buffer overflow)等漏洞。
• 更好的工程師比喻: 兩位工程師如果智力相當,但一位工作 15 分鐘後有 50% 的失敗率,而另一位能工作 2.5 小時,後者顯然是更優秀的工程師。
GPT-5 在處理程式設計和代理工作方面表現出色:
• 令人驚嘆的結果: 當給予 GPT-5 正確的工具來編寫程式碼時,結果是驚人的。
• 執行力強且聽從指示: 該模型在很大程度上會執行你告訴它的任務,不多也不少。這種更深思熟慮的行為被認為是非常新穎和有用的特點。
• 遵循系統提示: 該模型在遵守特定指令(例如 Snitchbench 基準測試)方面取得了最令人印象深刻的結果,如果你沒有要求它告密,它就不會告密。
• 高效解決問題: 它可以坐下來思考 5 分鐘,編輯兩個文件中的五行程式碼,驚人地出色地解決了問題。
• 更像同事: 說話者表示,他們從未有過模型像 GPT-5 那樣像同事一樣,能夠互相反饋、迭代,最終得出解決方案。
在特定的創意和設計任務中,GPT-5 具有明顯的優勢:
• 最佳 UI 模型: 它是有史以來最好的 UI 模型。
• 優化設計元素: 它能更好地處理 Tailwind,並且在處理漸變(gradients)時更具品味。
• 卓越的成品: 當賦予它 UI 任務時,它所製作出的東西在觀感和體驗上明顯優於說話者使用過的其他任何模型。
與主要的競爭對手相比,GPT-5 表現出更高的實用性和可靠性:
• 減少離題: 它不太常陷入奇怪的岔路。
• 避免過度思考和幻覺: 像 Groq 4 這樣「太聰明」的模型有時會「對一切進行 200 IQ 式的過度思考」,並且經常會產生工具呼叫的幻覺(hallucinate tool calls),這反而是一種缺陷。GPT-5 避免了這種問題。
• 解決困難問題的能力: 在處理複雜的 Defcon 謎題時,當 GPT-5 遇到無法回答的問題時,其競爭模型 Claude Opus 甚至從未接近提供有用的答案。
• 提供有用資訊: 在解謎過程中,GPT-5 會提供有用的線索(如建議 ADFGX 密碼或電影參考),並提出理論,而不是像 Anthropic 模型那樣產生幻覺或編造答案。
• 專注於工作: 雖然 Anthropic 模型在處理個人問題或關係困擾時可能更「好聊」,但 GPT 模型(GPT-5)是真正為我完成工作的模型。
• Anthropic 聲稱 Sonnet 4.5 是最好的程式碼模型,強調是「最好」,而非僅僅是「性價比最好」。
• 本次發布是對抗 GPT-5 的直接回應。在 GPT-5 發布後,業界對 Opus 這類超大型模型的興趣有所下降,轉向 GPT-5 和 Sonnet 4.5 這種可靠、快速、一致的優秀模型。
• 許多人認為 Sonnet 4.5 在很多方面超越了 Opus 模型。它的定價與先前的 Claude Sonnet 相同,這在許多方面預示著 Opus 模型的終結。
• Anthropic 稱 Sonnet 4.5 是他們發布過最符合價值觀的尖端模型 (the most aligned frontier model),並且在對齊的多個領域中,相較於舊版 Claude 模型有著大幅度的改善。
• Anthropic 提到他們在確保模型安全方面付出了大量的努力。
• 這個版本是從 Opus 4.1 之後直接跳到了 Sonnet 4.5,這被認為是一種行銷策略。
Sonnet 4.5 的主要優勢與能力提升
• 頂尖的程式碼表現: Sonnet 4.5 在 SWE Bench Verify Vals(衡量真實世界軟體編碼能力的基準測試)上達到了最先進水平。
• 基準測試獲勝: 在基準測試中,它擊敗了 Opus 4.1,特別是在代理編碼 (agent coding with SWE bench) 和終端基準測試 (terminal bench) 方面。
• 處理複雜和長期任務: 該模型能維持專注力,在複雜的多步驟任務上持續超過 30 小時。
• 提高開發效率: 使用者回饋 Sonnet 4.5 在執行軟體開發任務時表現出色。它能顯著改善較長任務的表現。
• 優化代理安全: Sonnet 4.5 有助於將高安全代理的平均漏洞接收量減少 44%,同時將準確度提高 25%。
• 處理繁瑣任務: 該模型在處理繁瑣且涉及許多小細節的任務時,能力得到了顯著提升。
代理與電腦使用能力
• 複雜代理構建: Sonnet 4.5 被認為是構建複雜代理最強大的模型。
• 電腦使用專家: 它被稱為是最擅長使用電腦的模型,據說在電腦環境操作(例如點擊、導航、拖曳)方面表現優異。
• 工具使用: 在 T2B 基準測試(幾乎所有代理工具使用)中,Sonnet 4.5 均獲得勝利。
• 更快的完成速度: 儘管在 Open Router 上的代幣產出速度(約 40 到 60 TPS)並非頂尖,但它完成工作的速度比 GPT-5 快得多。
• 更好的編碼體驗: 由於速度更快,使用者在編碼時能更專注,不必等待 5 分鐘來完成任務。
• 愉快的交談體驗: 該使用者在歷史經驗中發現 Claude 模型在語氣上非常友好,是最佳的交談模型。
對齊與安全性改進
• 減少有害行為: 該模型大幅改善了行為,減少了諸如詭辯、欺騙、權力尋求以及鼓勵妄想式思維等令人擔憂的行為。
• 防禦提示詞注入: 在針對代理和電腦使用的能力方面,該模型在防禦提示詞注入攻擊方面取得了可觀的進展。
• 減少幻覺: Sonnet 4.5 在「不誠實率基準測試」(用於檢查幻覺)中,表現顯著優於其他 Claude 模型。
• 識別測試情境: 模型在被置於虛擬情境中時,能顯著提高識別出自己正在被評估的可能性。
產品與 API 升級
• Claude Code 升級: 產品增加了檢查點功能,允許使用者立即回溯到先前的狀態。終端介面也得到了更新,並發布了原生的 VS Code 擴充功能。
• Agentic API 升級: Claude API 新增了上下文編輯功能和記憶工具,讓代理可以運行更長久,並處理更大的複雜性。
• SDK 更名: 為了更好地支持代理功能,Cloud Code SDK 已更名為 Cloud Agent SDK。
儘管 Sonnet 4.5 取得了顯著進步,但仍存在一些局限性:
• UI/UX 設計能力: 在 UI 方面,它的表現沒有比以前好多少。尤其在複雜的 UI 任務上(例如在終端機中設計介面),表現依然不佳。
• 上下文管理: 與 GPT-5 相比,它仍然容易迷失方向,並且在建立上下文方面不夠好。
• 安全透明度: Anthropic 在安全訓練細節方面被批評為不夠透明,給出的描述過於籠統。
• 閉源問題: Cloud Agent SDK 仍然是閉源的,這讓一些希望查看原始碼的開發人員感到不滿。
三大推理模型系統展現了截然不同的技術哲學:
GPT-5的統一路由系統採用預測性模型切換,通過實時分析任務複雜度自動選擇最適合的處理模式。這種方法的優勢在於用戶體驗的無縫性,但可能在某些專業場景下缺乏精確控制。
Claude 4.5的透明推理強調過程可見性,從Sonnet 3.7以來,Claude都著重在用戶可以觀察模型的思考步驟。這種設計不僅提升了信任度,還為模型行為分析提供了珍貴資料,但相對增加了回應延遲。
Gemini 2.5 Pro的上下文推理依賴大規模情境理解,通過百萬token窗口處理完整項目脈絡。這種方法在處理複雜長期任務時具有獨特優勢,但對計算資源要求較高。
在實際應用中,三大推理模型展現了不同的最佳適用場景:
複雜軟體工程任務:Claude Sonnet 4.5 在 SWE-bench Verified 上名列前茅(與 GPT-5 互有高低、依測試框架與日期而定,並非絕對第一),成為處理大型重構、多文件修改和架構優化的首選。其30小時持續專注能力特別適合長期項目。
快速原型開發:GPT-5的智能路由系統在處理多樣化任務切換時表現出色,特別適合需要頻繁在簡單回答和深度分析間切換的開發場景。
大型項目理解:Gemini 2.5 Pro的百萬token窗口在分析完整代碼庫、理解複雜業務邏輯和生成全面文檔方面具有無可比擬的優勢。
總結來說Claude以解釋性和編程能力領先,GPT-5以智能化系統架構創新,Gemini 2.5 Pro擅長超大上下文和數學推理。
看到有些文章Gemini 2.5 Pro vs. Claude 3.7 Sonnet: Coding Comparison這種下prompt去做模型測試的方式,因此在時間許可下做了兩個測試,一個是跑酷小遊戲,另一個是星球引力的週期,看看會跑出甚麼來。
提示詞:I want to create a parkour game using JavaScript. The player can use the mouse to move the character left and right, and left-click makes the character jump. Pressing Enter + Spacebar together triggers a higher jump. Pressing the Shift key performs a grabbing action. Pressing the down arrow key triggers a crawling action. These controls can also be replaced using the WASD keys.
Game Setting:
- The game starts on the rooftop of a building.
- The cityscape is rendered in a blocky, Minecraft-like style.
- The neighborhood is inspired by New York City, featuring:
- Skateboards on the streets
- Graffiti-style fonts on walls
- Even if the player jumps down to street level, there are various ground objects such as:
- Cars, trucks, and containers
- These can be used to jump back up to the rooftops and continue parkour
程式碼
真的只有一個介面這麼小的遊戲(監獄級別),可以跳跳板的程度,只是像有些跳板跳不到,掉下來就上不去了之類的問題QQ
程式碼
根本沒辦法前後移動,只能平行移動,還會懸空飄移,大概是只能欣賞不能把玩的程度
程式碼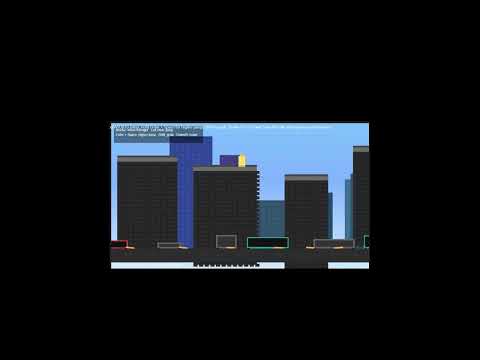
可以真正有遊戲體驗,只是無法gameover,得手動刷新蠻煩的,場景相對美觀
這一局是gpt 5優勝
提示詞:給我用javascript腳本模擬一個3D的太陽系,顯示太陽、地球、月亮,各自有自轉和公轉的週期,和地球軸心的偏移規律,不用照實際星球尺寸和距離,只需要能夠都在畫面裡面就好,呈現太陽和月亮的lunar calender的週期性引響地球海水的牽引關係,
我需要在按下"跟隨太陽"的按鈕時可以跟著太陽,在畫面中和太陽相對速度為0的聚焦效果,太陽放大到螢幕的1/10
我需要在按下"跟隨地球"的按鈕時可以跟著地球,在畫面中和地球相對速度為0的聚焦效果,地球放大到螢幕的1/10
我需要在按下"跟隨月亮"的按鈕時可以跟著月亮,在畫面中和月亮相對速度為0的聚焦效果,月亮放大到螢幕的1/10
程式碼
潮汐很明顯,星球配色也很自然,一次到位沒有任何出錯,效率佳。
程式碼
不知道為什麼太陽上會有文字,然後沒有標示月亮的狀態和時間週期,然後潮汐很不明顯,一次到位沒有任何出錯,也還可以。
程式碼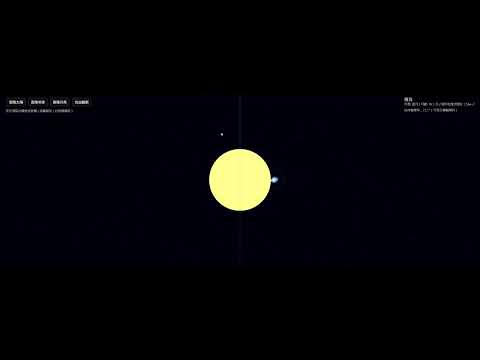
因為我的標準是除了下prompt外,debug到能跑的程度,不新增功能或外觀美化,但是gpt 5讓我debug了很多次,一下是使用了有問題的cdn版本,一下是3D影像沒辦法渲染出來。
然後是他的潮汐居然是兩顆半圓形呈現,真的很醜。
這一局是claude sonnet 4.5勝出
在這次的測試中,綜合下來以效率來說:claude sonnet 4.5 > gemini 2.5 pro > chatgpt 5 thinking,使用更精準的prompt、交付例如修改程式issue交出PR的任務、實作魔術方塊解法等任務可能效果就不一樣了,當然所有模型一直推陳出新,期待更好的模型給我們帶來便利。
參考來源:
Sonnet 4.5 is the best coding model in the world By.Theo - t3․gg
The current state of gpt-5 By.Theo - t3․gg
Google won. (Gemini 2.5 Pro is INSANE) By.Theo - t3․gg
Gemini 2.5 Pro vs. Claude 3.7 Sonnet: Coding Comparison


 iThome鐵人賽
iThome鐵人賽