延續「葵花寶典」的心法,AI 原生開發的第一步就是「意念先行」。在獨孤九劍的劍法中,最高境界是心中無劍、手中無劍,只有意念。今天,我們將學習如何將心中的「測試意圖」,透過自然語言與 AI 協作,自動生成一份專業的測試計畫與案例。
.github/prompts/playwright-manual.test-plan.prompt.md
Copilot Chat
playwright-manual.test-play.prompt.md 建立測試計畫參考 Manual Testing with Playwright MCP 建立了一個完整的測試計畫撰寫指引,在 playwright-manual.test-plan.prompt.md 檔案中。這份檔案就像是我們的「心法口訣」,它將告訴 AI 如何系統化地思考並產出高品質的測試計畫。建立了一個完整的測試計畫撰寫指引,在 playwright-manual.test-plan.prompt.md 檔案中。這份檔案就像是我們的「心法口訣」,它將告訴 AI 如何系統化地思考並產出高品質的測試計畫。
---
mode: agent
tools: ['changes', 'codebase', 'editFiles', 'fetch', 'findTestFiles', 'problems', 'runCommands', 'runTasks', 'runTests', 'search', 'searchResults', 'terminalLastCommand', 'terminalSelection', 'testFailure', 'playwright', 'browser_click', 'browser_close', 'browser_console_messages', 'browser_drag', 'browser_file_upload', 'browser_handle_dialog', 'browser_hover', 'browser_install', 'browser_navigate', 'browser_navigate_back', 'browser_navigate_forward', 'browser_network_requests', 'browser_pdf_save', 'browser_press_key', 'browser_resize', 'browser_select_option', 'browser_snapshot', 'browser_tab_close', 'browser_tab_list', 'browser_tab_new', 'browser_tab_select', 'browser_take_screenshot', 'browser_type', 'browser_wait_for']
model: 'Claude Sonnet 4'
---
# 測試計畫撰寫指引
這份文件主要是如何撰寫系統化的測試計畫,並且基於此份文件可作為測試報告或是手動測試結果
## 目標
建立一份全面性的測試計畫文間,並基於現有的測試報告或手動測試結果,並建立系統性、優先順序、並且可以實際執行的測試計畫。
## 指引說明
### 1. 分析階段
- 根據目前的測試報告或者使用 Playwright MCP 進行初步的手動測試
- 判斷主要的使用者流程和關鍵的功能
- 紀錄目前的功能,包含功能模組、UI 元件和使用者互動流程
- 標注已知問題或者有疑慮的部分
### 2. 測試計畫架構
建立一份測試計畫文件,並且包含下列章節:
測試計畫總覽
- 功能/應用程式:名稱與描述
- 測試範圍:測試涵蓋與未涵蓋的地方
- 測試目標:主要目標與評估通過準則
- 測試環境:URL、瀏覽器、裝置等
### 3. 測試案例格式
每個測試案例需包含:
測試案例 X.Y:[清楚、且描述性的標題]
- 優先級: [高 / 中 / 低]
- 分類: [功能 / UI / 無障礙 / 其他]
- 前置條件: [執行測試前需要事先設定或資料]
- 測試步驟:
1. [逐步操作說明]
2. [每一步的預期結果]
- 預期結果: [最終應有的結果]
- 驗收條件: [通過 / 失敗 判斷依據]
### 4. 風險評估
在撰寫過程需翹能夠辨識並記錄:
- 高風險區域:可能需要額外注意的功能
- 測試案例之間的相依性
- 潛在阻礙因素與對應的因應策略
- 測試限制與假設條件
### 5. 衡量測試是否通過的指標
定義可量化的測試通過的標準:
- 通過率目標(例如:Priority 1 測試需達 95%,Priority 2 測試需達 90%)
- 效能基準(頁面載入時間、回應時間等)
- 無障礙標準(需符合 WCAG 等級要求)
- 瀏覽器/裝置覆蓋率
### 6. 測試計畫輸出
最終產出文件應包含:
- 總結(包含關鍵功能和需要強調需要關注的地方)
- 完整的測試案例清單
- 依優先順序排列的執行計畫
- 風險評估與對應的緩解策略
- 測試通過準則與衡量指標
- 自動化測試的建議方向
## 最佳實務建議
- 具體明確:在測試步驟中使用清楚、可執行的描述
- 以使用者為中心:聚焦於真實使用場景與流程
- 涵蓋邊界情境:測試邊界值與錯誤場景
- 完整紀錄:包含前置條件、步驟、預期結果
- 嚴格優先排序:先測試對於商業最為關鍵的功能
## 最後需要交付的文件
測試計畫文件:包含完整測試案例的 Markdown 檔,存放於 manual-tests 目錄。
撰寫完成後請關閉相關的瀏覽器分頁。
我直接在 VS Code 中,向 Copilot Chat 提出指令,並引用剛剛撰寫好的 Prompt。
使用 playwright-manual.test-plan.prompt.md 建立測試計畫
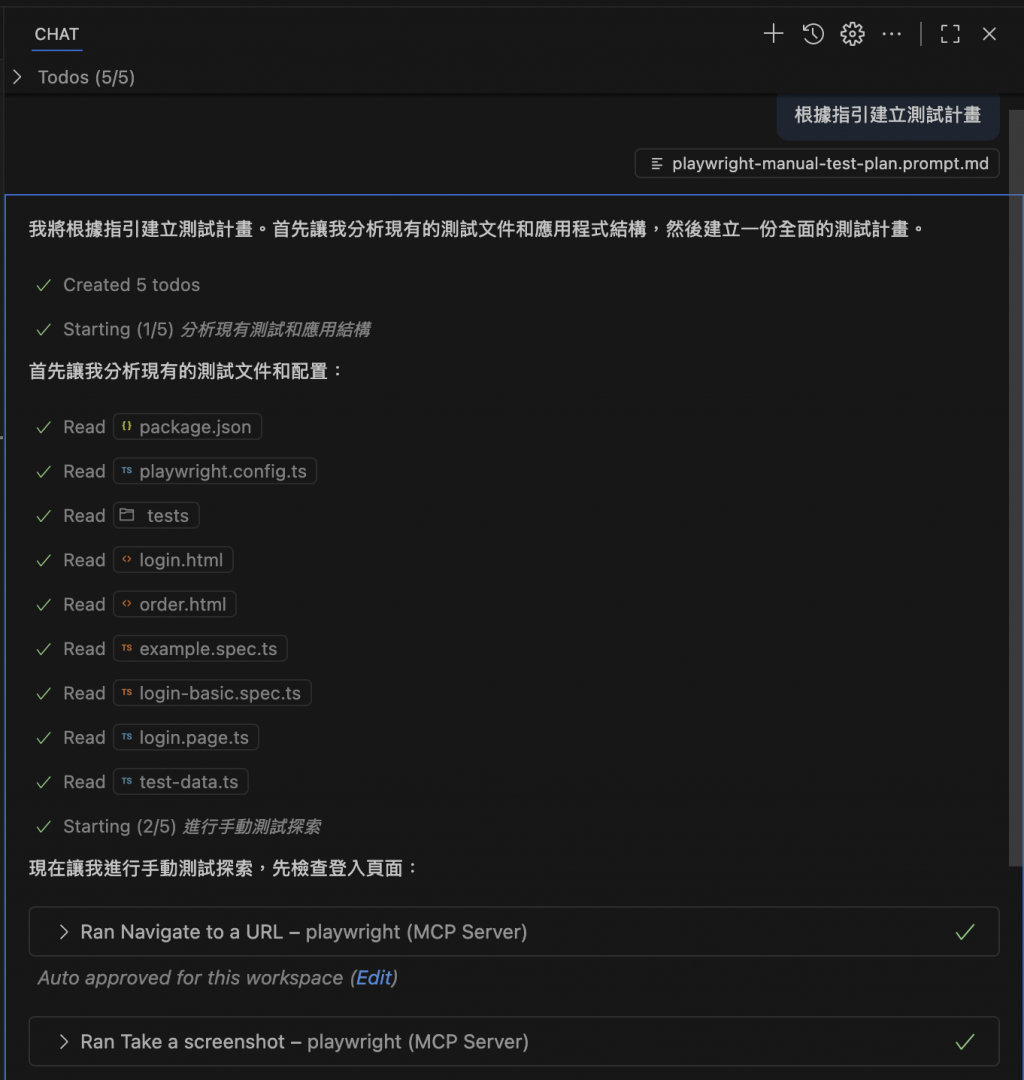
執行後,AI 根據我的指令與現有專案結構,自動產生了一份完整且結構化的測試計畫檔案,如下所示:
# 手動測試計畫:登入與訂單系統
## 測試計畫總覽
### 功能/應用程式
**應用程式名稱:** 登入與訂單管理系統
**描述:** 基於 HTML/JavaScript 的簡易測試應用,包含使用者登入驗證功能以及訂單建立流程
### 測試範圍
#### 涵蓋範圍
- 使用者登入功能(包含各種登入情境)
- 訂單建立與提交流程
- 基本 UI 元件互動測試
- 表單驗證與錯誤處理
- 使用者體驗流程測試
#### 未涵蓋範圍
- 後端 API 整合測試(目前為前端模擬)
- 跨瀏覽器相容性測試(僅覆蓋 Chrome)
- 效能與負載測試
- 安全性與滲透測試
- 行動裝置響應式設計測試
### 測試目標
1. **功能正確性:** 驗證所有功能按預期運作
2. **使用者體驗:** 確保介面直觀易用且錯誤處理適當
3. **資料完整性:** 驗證表單資料正確處理與儲存
4. **錯誤處理:** 確認各種錯誤情境的適當回應
### 測試環境
- **URL:** `file:///Users/wclee/workspace/playwright-testing-ai-examples/tests/fixtures/`
- **瀏覽器:** Chrome (Chromium)
- **作業系統:** macOS
- **測試工具:** Playwright MCP + 手動測試
## 測試案例
### 1. 登入功能測試
#### 測試案例 1.1:正常登入流程
- **優先級:** 高
- **分類:** 功能
- **前置條件:** 開啟 `login.html` 頁面
- **測試步驟:**
1. 在使用者名稱欄位輸入 "testuser"
2. 在密碼欄位輸入 "password123"
3. 點擊「登入」按鈕
4. 觀察頁面回應
- **預期結果:** 顯示綠色的 "Welcome" 訊息
- **驗收條件:** Welcome 訊息可見且為綠色
#### 測試案例 1.2:錯誤密碼登入
- **優先級:** 高
- **分類:** 功能
- **前置條件:** 開啟 `login.html` 頁面
- **測試步驟:**
1. 在使用者名稱欄位輸入 "testuser"
2. 在密碼欄位輸入 "wrongpassword"
3. 點擊「登入」按鈕
4. 觀察錯誤訊息
- **預期結果:** 顯示紅色錯誤訊息「帳號或密碼錯誤」
- **驗收條件:** 錯誤訊息正確顯示且為紅色
#### 測試案例 1.3:不存在的使用者帳號
- **優先級:** 高
- **分類:** 功能
- **前置條件:** 開啟 `login.html` 頁面
- **測試步驟:**
1. 在使用者名稱欄位輸入 "nonexistentuser"
2. 在密碼欄位輸入 "anypassword"
3. 點擊「登入」按鈕
4. 觀察錯誤訊息
- **預期結果:** 顯示紅色錯誤訊息「帳號或密碼錯誤」
- **驗收條件:** 錯誤訊息正確顯示
#### 測試案例 1.4:空白欄位提交
- **優先級:** 高
- **分類:** 功能
- **前置條件:** 開啟 `login.html` 頁面
- **測試步驟:**
1. 保持使用者名稱和密碼欄位為空
2. 點擊「登入」按鈕
3. 觀察錯誤訊息
- **預期結果:** 顯示錯誤訊息「請輸入帳號與密碼」
- **驗收條件:** 錯誤訊息正確顯示
#### 測試案例 1.5:帳號被鎖定情境
- **優先級:** 中
- **分類:** 功能
- **前置條件:** 開啟 `login.html` 頁面
- **測試步驟:**
1. 在使用者名稱欄位輸入 "locked_user"
2. 在密碼欄位輸入任意密碼
3. 點擊「登入」按鈕
4. 觀察錯誤訊息
- **預期結果:** 顯示錯誤訊息「此帳號已被停用」
- **驗收條件:** 特定帳號鎖定訊息正確顯示
#### 測試案例 1.6:只填寫使用者名稱
- **優先級:** 中
- **分類:** 功能
- **前置條件:** 開啟 `login.html` 頁面
- **測試步驟:**
1. 在使用者名稱欄位輸入 "testuser"
2. 保持密碼欄位為空
3. 點擊「登入」按鈕
4. 觀察錯誤訊息
- **預期結果:** 顯示錯誤訊息「請輸入帳號與密碼」
- **驗收條件:** 部分欄位空白時的錯誤處理正確
### 2. 訂單建立功能測試
#### 測試案例 2.1:正常訂單建立流程
- **優先級:** 高
- **分類:** 功能
- **前置條件:** 開啟 `order.html` 頁面
- **測試步驟:**
1. 在商品名稱欄位輸入「筆記型電腦」
2. 在數量欄位輸入「2」
3. 點擊「送出訂單」按鈕
4. 觀察成功訊息和訂單摘要
- **預期結果:**
- 顯示綠色成功訊息「訂單建立成功!您的訂單已送出並儲存至系統。」
- 顯示訂單摘要包含正確的商品名稱和數量
- 表單被清空
- **驗收條件:** 成功訊息、訂單摘要顯示正確,表單重置
#### 測試案例 2.2:空白商品名稱提交
- **優先級:** 高
- **分類:** 功能
- **前置條件:** 開啟 `order.html` 頁面
- **測試步驟:**
1. 保持商品名稱欄位為空
2. 在數量欄位輸入「1」
3. 點擊「送出訂單」按鈕
4. 觀察錯誤訊息
- **預期結果:** 顯示錯誤訊息「請填寫完整的商品資訊」
- **驗收條件:** 錯誤訊息正確顯示
#### 測試案例 2.3:空白數量提交
- **優先級:** 高
- **分類:** 功能
- **前置條件:** 開啟 `order.html` 頁面
- **測試步驟:**
1. 在商品名稱欄位輸入「滑鼠」
2. 保持數量欄位為空
3. 點擊「送出訂單」按鈕
4. 觀察錯誤訊息
- **預期結果:** 顯示錯誤訊息「請填寫完整的商品資訊」
- **驗收條件:** 錯誤訊息正確顯示
#### 測試案例 2.4:零數量或負數量
- **優先級:** 中
- **分類:** 功能
- **前置條件:** 開啟 `order.html` 頁面
- **測試步驟:**
1. 在商品名稱欄位輸入「鍵盤」
2. 在數量欄位輸入「0」
3. 點擊「送出訂單」按鈕
4. 觀察錯誤訊息
5. 重複步驟並輸入負數(如 "-1")
- **預期結果:** 顯示錯誤訊息「請填寫完整的商品資訊」
- **驗收條件:** 無效數量的錯誤處理正確
#### 測試案例 2.5:特殊字元商品名稱
- **優先級:** 中
- **分類:** 功能
- **前置條件:** 開啟 `order.html` 頁面
- **測試步驟:**
1. 在商品名稱欄位輸入包含特殊字元的名稱「iPhone 15 Pro Max (256GB)」
2. 在數量欄位輸入「1」
3. 點擊「送出訂單」按鈕
4. 觀察訂單處理結果
- **預期結果:** 訂單成功建立,訂單摘要正確顯示特殊字元商品名稱
- **驗收條件:** 特殊字元正確處理和顯示
#### 測試案例 2.6:大數量訂單
- **優先級:** 低
- **分類:** 功能
- **前置條件:** 開啟 `order.html` 頁面
- **測試步驟:**
1. 在商品名稱欄位輸入「辦公用品套組」
2. 在數量欄位輸入大數值「999」
3. 點擊「送出訂單」按鈕
4. 觀察訂單處理結果
- **預期結果:** 訂單成功建立,數量正確顯示
- **驗收條件:** 大數量訂單正確處理
### 3. UI/UX 測試案例
#### 測試案例 3.1:頁面載入與外觀
- **優先級:** 中
- **分類:** UI
- **前置條件:** 分別開啟 `login.html` 和 `order.html` 頁面
- **測試步驟:**
1. 檢查頁面標題顯示
2. 驗證表單元件排版
3. 確認按鈕樣式和可點擊狀態
4. 檢查字體和色彩配置
- **預期結果:** 頁面外觀整潔,元件排列合理,無明顯視覺問題
- **驗收條件:** UI 元件正常顯示且符合設計要求
#### 測試案例 3.2:表單欄位互動性
- **優先級:** 中
- **分類:** UI
- **前置條件:** 開啟任一測試頁面
- **測試步驟:**
1. 點擊各個輸入欄位,確認焦點切換
2. 使用 Tab 鍵進行鍵盤導航
3. 檢查 placeholder 文字顯示
4. 驗證輸入時的即時回饋
- **預期結果:** 表單欄位響應良好,鍵盤導航正常
- **驗收條件:** 所有互動功能正常運作
#### 測試案例 3.3:錯誤訊息顯示效果
- **優先級:** 中
- **分類:** UI
- **前置條件:** 開啟測試頁面並觸發錯誤情境
- **測試步驟:**
1. 故意觸發各種錯誤情境
2. 觀察錯誤訊息的顯示位置
3. 檢查錯誤訊息的顏色和字體
4. 驗證錯誤訊息的清除機制
- **預期結果:** 錯誤訊息顯示明顯,位置合適,容易理解
- **驗收條件:** 錯誤訊息 UX 友善且有效
### 4. 資料完整性測試
#### 測試案例 4.1:訂單資料儲存驗證
- **優先級:** 高
- **分類:** 功能
- **前置條件:** 開啟 `order.html` 頁面並建立訂單
- **測試步驟:**
1. 建立一筆訂單(商品:「測試商品」,數量:3)
2. 使用瀏覽器開發者工具檢查 DOM
3. 驗證訂單資料是否正確儲存在隱藏的資料庫區域
4. 檢查時間戳記和使用者資訊
- **預期結果:** 訂單資料完整儲存,包含正確的商品、數量、時間戳記和使用者資訊
- **驗收條件:** 模擬資料庫中的資料與輸入一致
## 風險評估
### 高風險區域
1. **表單驗證邏輯:** 各種邊界值和無效輸入的處理
2. **錯誤處理機制:** 確保所有錯誤情境都有適當的使用者回饋
3. **資料儲存模擬:** 雖然是前端模擬,但需確保邏輯正確性
### 測試案例相依性
- 訂單測試假設使用者已經登入(透過 `order.html` 中的預設登入狀態)
- 部分 UI 測試依賴於功能測試的正常運作
### 潛在阻礙因素與因應策略
1. **瀏覽器相容性問題**
- 緩解策略:在不同瀏覽器版本中進行抽樣測試
2. **JavaScript 執行錯誤**
- 緩解策略:使用開發者工具監控控制台錯誤
3. **檔案路徑問題**
- 緩解策略:確保使用正確的絕對檔案路徑
### 測試限制與假設條件
- 測試基於靜態 HTML 檔案,無真實後端服務
- 資料持久性僅限於瀏覽器 session 期間
- 使用者認證為簡化的前端模擬邏輯
## 測試通過準則與衡量指標
### 通過率目標
- **優先級 1(高)測試:** 需達 100% 通過率
- **優先級 2(中)測試:** 需達 95% 通過率
- **優先級 3(低)測試:** 需達 85% 通過率
### 效能基準
- **頁面載入時間:** 本地檔案應在 1 秒內完全載入
- **表單回應時間:** 使用者操作後立即顯示回饋(< 100ms)
- **錯誤處理回應:** 錯誤訊息應在 200ms 內顯示
### 品質標準
- **功能正確性:** 所有核心功能按預期運作
- **使用者體驗:** 錯誤訊息清楚易懂,操作流程順暢
- **介面一致性:** UI 元件和互動行為保持一致
### 自動化測試建議
#### 適合自動化的測試
1. **功能性測試:** 所有登入和訂單建立的核心流程
2. **表單驗證:** 各種輸入驗證和錯誤處理情境
3. **回歸測試:** 確保修改後功能正常運作
#### 建議的自動化測試工具
- **Playwright:** 已有基礎框架,建議擴展覆蓋更多情境
- **測試資料管理:** 使用現有的 `test-data.ts` 模組化架構
- **頁面物件模式:** 繼續使用 `login.page.ts` 的模組化設計
## 總結
### 關鍵功能
此測試系統涵蓋了基本的使用者認證和訂單管理功能,適合作為 Web 應用程式測試的學習範例。
### 需要特別關注的地方
1. **輸入驗證的完整性:** 確保所有邊界情況都被正確處理
2. **使用者體驗的一致性:** 錯誤處理和成功回饋的使用者友善程度
3. **測試環境的穩定性:** 確保本地檔案路徑和瀏覽器環境的一致性
### 執行建議
建議按照優先級順序執行測試,先完成所有高優先級測試,確保核心功能穩定後再進行其他測試項目。每次修改程式碼後,應至少執行一次完整的高優先級測試套件。
---
**文件版本:** 1.0
**建立日期:** 2025-10-04
**最後更新:** 2025-10-04
**測試負責人:** GitHub Copilot
使用 Copilot Chat 可以根據 prompt 產生測試計畫,透過生成的測試案例可以和自己的測試案例比較,當然也可以審查這些測試案例是否合理,如果與自己的版本相差就需要調整 prompt 的內容,讓 Copilot 產生合理且預期的測試案例。但就如同我前幾天講的,測試案例的產生決定測試的品質,如果不能確保合理的測試範圍的話,讓 Copilot 幫忙輔助缺少的測試情境可能更好,不過隨著 AI 的進步,相信給足夠的資訊,還是能夠產生涵蓋範圍和合理的測試案例。
今天,我們將「意念先行」的心法落地為具體可行的測試計畫。我們證明了 AI 不僅能撰寫程式碼,更能協助我們進行高層次的測試規劃與風險評估。透過一份結構化的 Prompt,我們讓 AI 成為了我們的測試顧問,自動產出了一份專業、全面的測試計畫,這不僅大幅提升了效率,更確保了測試的品質。
但我也想再次強調,AI 產出的測試案例,終究需要我們的專業判斷與審核。測試案例的品質,最終還是取決於人類的洞察力。我認為,最好的策略是將 AI 視為一個強大的「輔助」與「放大器」,它能放大我們的專業,彌補我們的盲點,但無法取代我們對品質的承諾。

