今天來講一個頗為重要的議題,就是有關 LLM 的表現
之前在無預警的請況下從 Llama3.2 調整成 Gemma3,很大程度上是因為,Llama 系列一直以來在中文的表現就不是很好,反倒是發展較長的 Mistral 與 Gemma3 表現比較好,中國那邊訓練的模型更不用說,他們的資料及應以中文的為主,所以對中文的回答表現也會比較好。
所以這次除了比對西方國家訓練的模型,也要測試一下在中文圈較有名的模型
Gemma3:12b
關於內輪差的敘述,何者錯誤?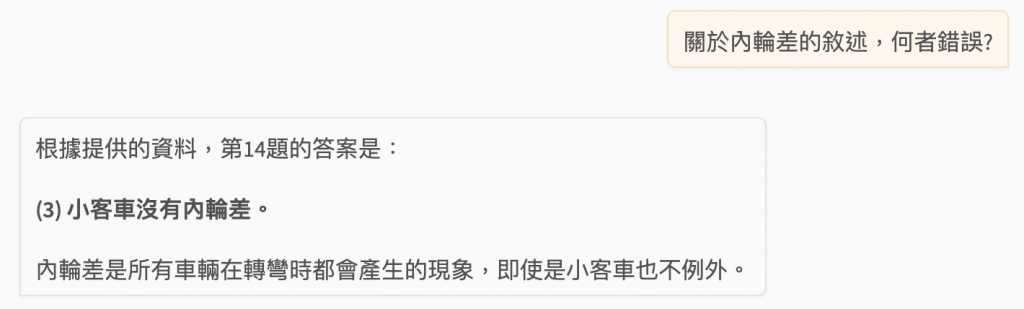
騎機車時若發現煞車系統失靈,第一時間應如何作較為適當?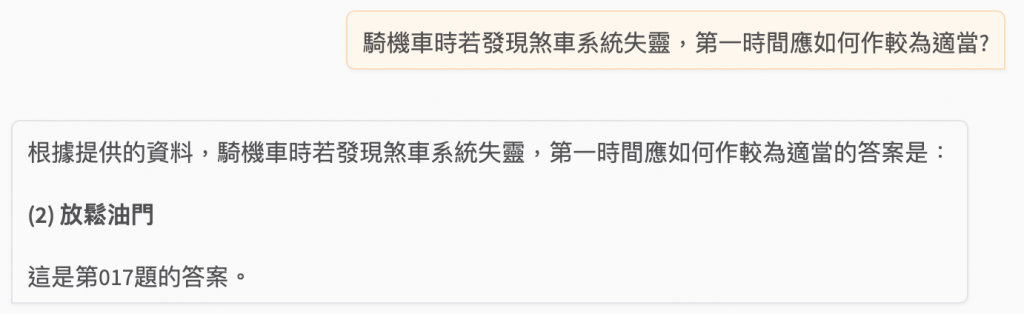
mistral:7b
關於內輪差的敘述,何者錯誤?
騎機車時若發現煞車系統失靈,第一時間應如何作較為適當?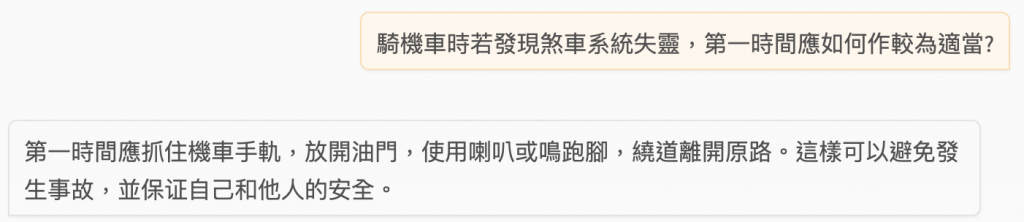
llama3.2:3b
關於內輪差的敘述,何者錯誤?
騎機車時若發現煞車系統失靈,第一時間應如何作較為適當?
gpt-oss:20b
關於內輪差的敘述,何者錯誤?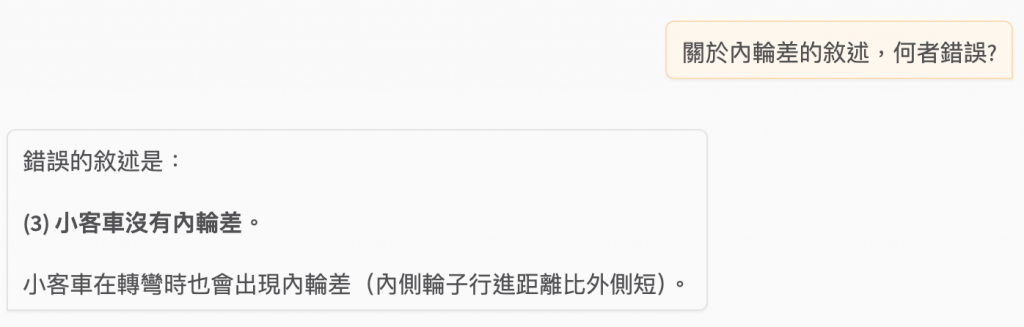
騎機車時若發現煞車系統失靈,第一時間應如何作較為適當?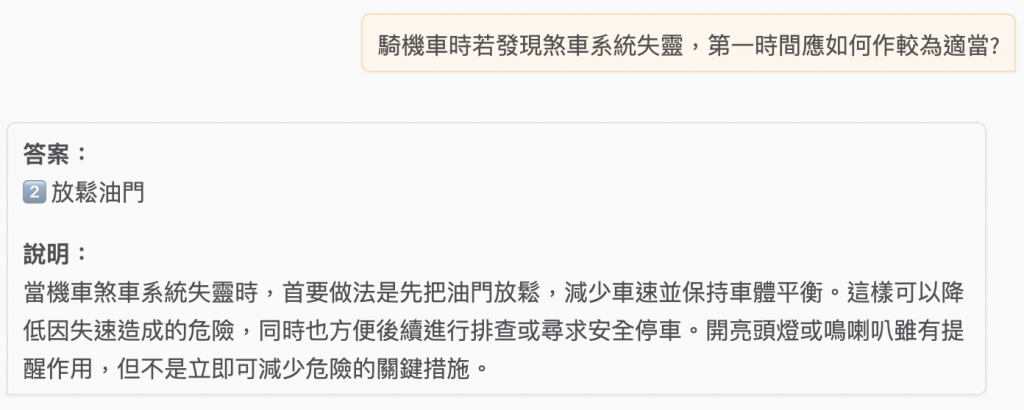
deepseek-r1:7b
關於內輪差的敘述,何者錯誤?
騎機車時若發現煞車系統失靈,第一時間應如何作較為適當?
qwen3:14b
關於內輪差的敘述,何者錯誤?
騎機車時若發現煞車系統失靈,第一時間應如何作較為適當?
我們可以把模型的參數量量化成人類的腦容量,頭腦有多少神經元,就可以儲存多少語言的字典 (Vocabulary),綜合上述結果可以看出,除了 llama3.2 的表現異於常人 (反串),其他的模型皆有有缺點,有的不會從 RAG 的搜尋結果裡面找答案,有的會。
而不同的模型又有不同的回覆風格,像是 deepseek 與 qwen 兩個模型會顯示他的思考過程 (也沒有辦法確認是不是真的會比較準),其實做 RAG 的話,Mistral 在這邊應該輸出的話會很多,但在這邊異常少倒是有點出乎意料。

