題目連結:https://rosalind.info/problems/mprt/
這題題目讓我看了非常久,尤其不懂他符號所代表的意思
輸入:
A2Z669
B5ZC00
P07204_TRBM_HUMAN
P20840_SAG1_YEAST
輸出:
B5ZC00
85 118 142 306 395
P07204_TRBM_HUMAN
47 115 116 382 409
P20840_SAG1_YEAST
79 109 135 248 306 348 364 402 485 501 614
今天這一題開始變得繁瑣,是真正的「上機題目」
要連上網並且出動爬蟲(requests)套件,來取得UniProt網站上的蛋白質序列資料
UniProt(Universal Protein Resource)是全球最大、最權威的蛋白質序列與功能資料庫
透過蛋白質id取得蛋白質序列
這邊以 題目範例輸入給這四個序列名稱為例:
A2Z669
B5ZC00
P07204_TRBM_HUMAN
P20840_SAG1_YEAST
分別各自要去以下四個網址取得序列
https://rest.uniprot.org/uniprotkb/A2Z669.fasta
https://rest.uniprot.org/uniprotkb/B5ZC00.fasta
https://rest.uniprot.org/uniprotkb/P07204.fasta
https://rest.uniprot.org/uniprotkb/P20840.fasta
蛋白質名字太長的要把底線_之後的字符給去掉,留下id即可,否則訪問會出錯
P07204_TRBM_HUMAN 這種寫法是 Entry Name(名稱顯示)
P07204 則是 Accession ID(主鍵、唯一值)
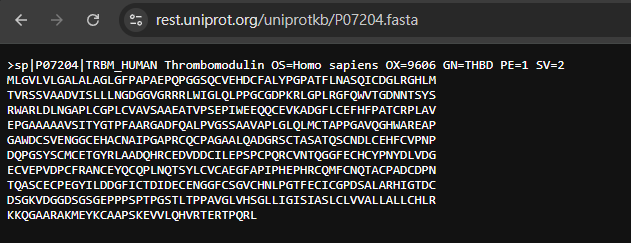
打開網址長這樣,獲得一條完整序列
題目原文有這一句:
[XY] means "either X or Y" and {X} means "any amino acid except X
For example, the N-glycosylation motif is written as N{P}[ST]{P}.
Motif 規則拆解:N{P}[ST]{P}代表連續4個胺基酸位置要符合以下:
位置i:要為N
位置i+1:不為P
位置i+2:是S或T
位置i+3:不是P
大括號{}代表排除
中括號[]代表包含其中之一
| PROSITE | 代表意義 | 近似Regex |
|---|---|---|
| A | 字母A | A |
| [ST] | S或T | [ST] |
| {P} | 非P | [^P] |
| x | 任意1字元 | . |
| x(3) | 任意3字元 | .{3} |
| x(2,4) | 任意2到4字元 | .{2,4} |
| < | 開頭 | ^ |
| > | 結尾 | $ |
詳細規則參考:PROSITE pattern syntax
PROSITE 是生物資訊學中影響深遠的始祖之一,是蛋白質家族與功能位點(functional sites)資料庫,生物學界的正規化表示法(motif表示語法)源於此
import re
from typing import List
import requests
# motif規則(N-glycosylation)
MOTIF_RULE = re.compile(r'(?=(N[^P][ST][^P]))')
def normalize_id(uid: str) -> str:
# 標準化蛋白質id,統一去除底線後,僅保留底線之前的字串
return uid.split("_", 1)[0]
def fetch_api(uniprot_id: str) -> str:
n_id = normalize_id(uniprot_id)
urls = [
f"https://rest.uniprot.org/uniprotkb/{n_id}.fasta", # 新版api(2022後),若失敗再去嘗試取舊版
f"https://www.uniprot.org/uniprot/{n_id}.fasta", # 舊版api
]
for url in urls:
resp = requests.get(url, timeout=1) # 設置爬取冷卻時間
if resp.status_code == 200 and resp.text.strip(): # 若有成功訪問網站,直接返回取得序列
lines = [ln.strip() for ln in resp.text.splitlines() if ln.strip()]
seq = "".join(ln for ln in lines if not ln.startswith(">"))
if seq:
return seq
# 沒成功返回代表爬取失敗
print(f"{uniprot_id}爬取失敗")
return ""
def find_positions(seq: str) -> List[int]:
pos = []
for m in MOTIF_RULE.finditer(seq):
start = m.start() + 1 # 起始位置轉成 1-based
pos.append(start)
return pos
def solve(ids: List[str]) -> None:
for id in ids:
try:
seq = fetch_api(id)
except Exception as e: # 錯誤處理
continue
indices = find_positions(seq)
if indices: # indexes
print(id)
print(" ".join(map(str, indices)))
if __name__ == "__main__":
ids = ["A2Z669", "B5ZC00", "P07204_TRBM_HUMAN", "P20840_SAG1_YEAST"]
solve(ids)

