題目連結:https://rosalind.info/problems/mrna/
今天這題,也要繞個彎想一下才能看懂題目在問的內容
輸入:
MA
輸出:
12
前面在 008. PROT(Translating RNA into Protein) 時提過
蛋白質是胺基酸鏈(amino acid chain, aas)
胺基酸鏈是由密碼子(codon)序列組成,一個密碼子就是三個核甘酸(A、U、C、G)順帶一提,因為是mRNA,不會有T,T只會在DNA上出現
我們知道每個蛋白質會對應到一種字母縮寫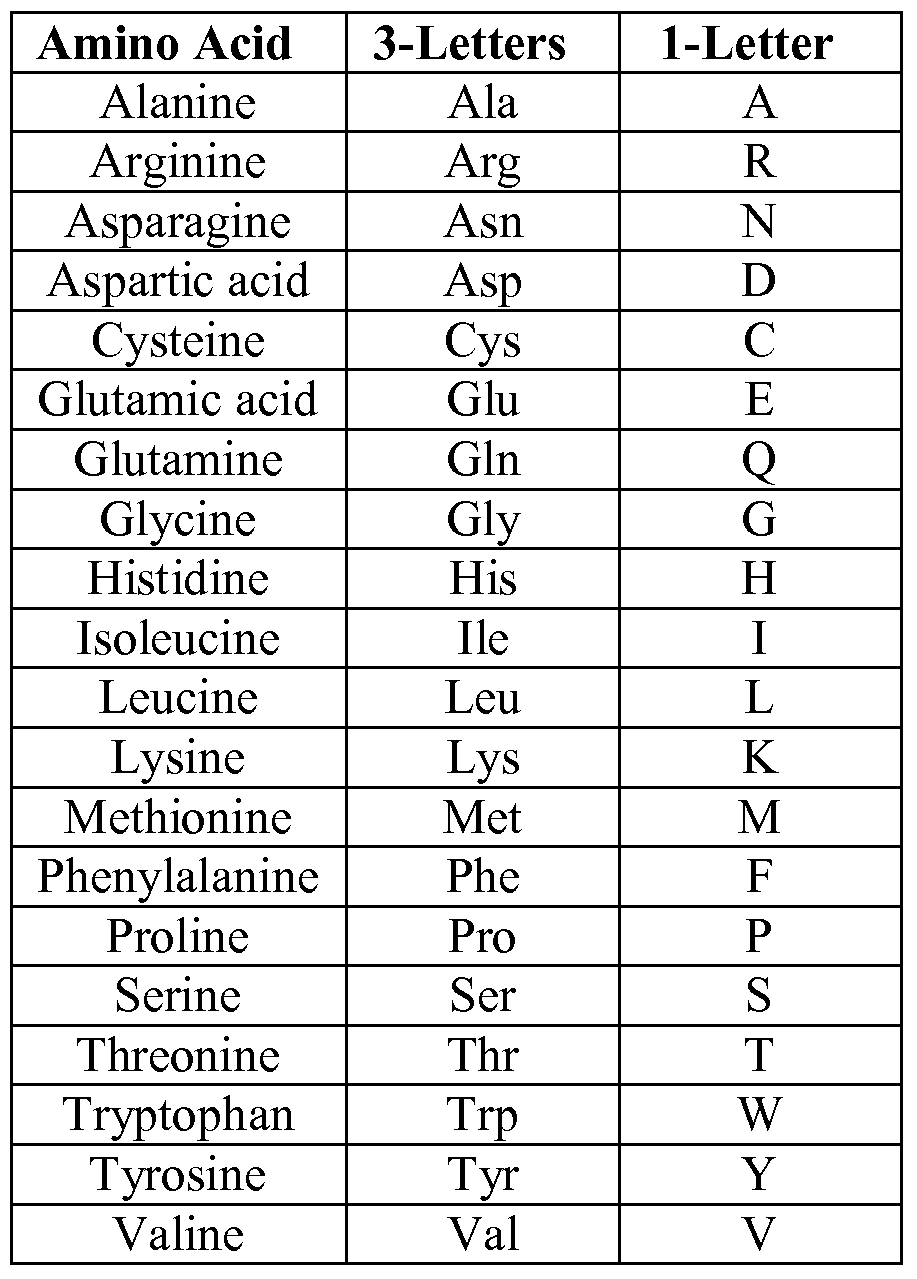
也知道密碼子表長這樣,仔細看能發現
一種蛋白質可以對應到多個(1~6)密碼子序列
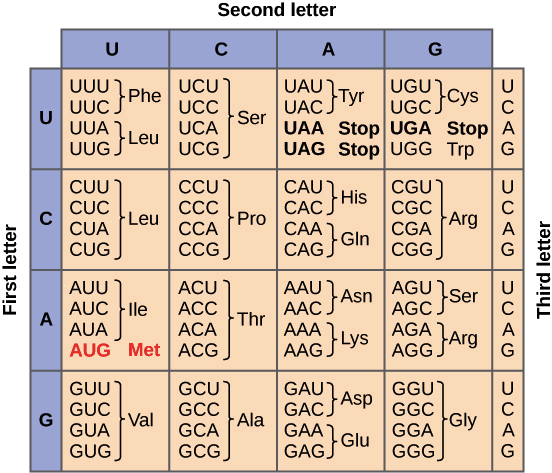
這題題目問的是,
如果給一段蛋白質的縮寫序列,求這段序列可以有幾種排列組合?
也就是,有多少種 codons 能產生相同的胺基酸鏈?
哦,因為一種胺基酸對應到mRNA序列(AUCG)可能有2種寫法、或者4種寫法,將每一個 胺基酸 x 胺基酸 乘在一起,就會產生排列組合數目
但同時,當序列非常大的時候,可以想像組合會膨脹很快、數字大的非常誇張...
題目最多只會給最多1000個aa.
然後要我們取 modulo 1,000,000(取餘數,mod 一百萬)
所以,首先要做的事情
我們必須將每一種蛋白質有幾種排列組合先列一張表出來,
才可以做後面排列組合的乘法計算
| 一字母代碼 | 三字母代碼 | 英文名稱 (Amino Acid) | 可用密碼子數 (# of Codons) |
|---|---|---|---|
| A | Ala | Alanine | 4 |
| C | Cys | Cysteine | 2 |
| D | Asp | Aspartic acid | 2 |
| E | Glu | Glutamic acid | 2 |
| F | Phe | Phenylalanine | 2 |
| G | Gly | Glycine | 4 |
| H | His | Histidine | 2 |
| I | Ile | Isoleucine | 3 |
| K | Lys | Lysine | 2 |
| L | Leu | Leucine | 6 |
| M | Met | Methionine | 1 |
| N | Asn | Asparagine | 2 |
| P | Pro | Proline | 4 |
| Q | Gln | Glutamine | 2 |
| R | Arg | Arginine | 6 |
| S | Ser | Serine | 6 |
| T | Thr | Threonine | 4 |
| V | Val | Valine | 4 |
| W | Trp | Tryptophan | 1 |
| Y | Tyr | Tyrosine | 2 |
轉換成程式碼如下
codon_count = {
'A': 4, 'C': 2, 'D': 2, 'E': 2, 'F': 2, 'G': 4,
'H': 2, 'I': 3, 'K': 2, 'L': 6, 'M': 1, 'N': 2,
'P': 4, 'Q': 2, 'R': 6, 'S': 6, 'T': 4, 'V': 4,
'W': 1, 'Y': 2
}
其中,原文還提到一點:
Don't neglect the importance of the stop codon in protein translation.
不要忽視stop codon的重要性,雖然正常來說他不會轉譯出胺基酸
stop codon代表「蛋白質翻譯終點」的結束訊號,總是在一段mRNA的最尾端才會出現,所以也要考量進去
因為總共有三種stop codon(UAA、UAG、UGA)!所以要乘以3
aas = "MA"
MOD = 1000000 # 或者也可寫成這樣 `1_000_000` 提高位數辨識度
codon_count = {
'A': 4, 'C': 2, 'D': 2, 'E': 2, 'F': 2, 'G': 4,
'H': 2, 'I': 3, 'K': 2, 'L': 6, 'M': 1, 'N': 2,
'P': 4, 'Q': 2, 'R': 6, 'S': 6, 'T': 4, 'V': 4,
'W': 1, 'Y': 2
}
ans = 1 # 排列組合初始為1
for aa in aas:
ans = (ans * codon_count[aa]) % MOD # 每一次乘法乘完就取mod,能夠加速下次運算(讓運算量不會太大)
# 乘上stop codon的3種選項
ans = (ans * 3) % MOD
print(ans)
最後不要忘記將答案*3,再取mod(因為有可能超過100萬)
完工!

