自從 GPT 系列爆紅之後大家一提到大型語言模型,腦中浮現的幾乎都是那幾個熟悉的縮寫 GPT-2、GPT-3、GPT-4⋯⋯ 但有趣的是這幾年另一條技術支線正在快速崛起,並以更少的參數、更快的推理效率,打出了媲美甚至超越 GPT 的性能。這條支線的主角之一正是 Meta 所推出的 LLaMA 模型系列。
LLaMA 的設計理念幾乎反其道而行不是一昧堆疊參數,而是透過精巧的架構優化、數學設計與訓練策略,達到小而強的模型效果。你可能會好奇它怎麼做到的?又為什麼越來越多研究者和開發者開始轉向 LLaMA 生態系?
今天這篇文章就帶你一探究竟,從 RMSNorm、SwiGLU、RoPE 到 GQA,一步步拆解 LLaMA 的底層設計,看它如何在不走傳統套路的情況下,重塑大型語言模型的技術格局。
從 2023 年 2 月 LLaMA 問世以來,Meta 已推出多個版本的改進型模型,每一代皆具備獨特的架構創新與設計理念,以下為各版本的概覽:
LLaMA 1(2023.02):採用 Decoder-only Transformer 架構,核心技術包括 RMSNorm、SwiGLU 以及 RoPE,支援原生 2K 上下文長度。常見的模型參數規模有 7B、13B、33B 與 65B,奠定了 LLaMA 架構的基礎。
LLaMA 2(2023.07):在訓練資料規模與品質上有所提升,並同步推出針對對話應用與商用授權的版本。延續前代核心技術,並引入 Grouped-Query Attention(GQA),有效減少 KV cache 占用。原生支援 4K 上下文,模型尺寸涵蓋 7B、13B 與 70B。
LLaMA 3(2024.04):初期推出 8B 與 70B 版本,原生支援 8K 上下文。這一代強調使用大規模、乾淨的語料,並透過更加嚴謹的後訓練流程(如 SFT 與 DPO)來提升模型表現。
LLaMA 3.1(2024.07):新增 405B 的超大模型版本,將上下文長度擴展至 128K,並全面採用 GQA。此版本著重於強化長上下文推理能力與工具使用的整合性,展現出更強大的實用性與泛化能力。
而架構中的 RMSNorm、SwiGLU、RoPE 和 GQA 這些技術,現在幾乎已經成了 LLM 的基本配備,幾乎每個新模型都少不了它們,因此我們現在來特別了解一下這些架構是基於何種的理由進行改動,並他與原始究竟差異在哪裡。
RMSNorm 是一種用來取代 LayerNorm 的正規化技術,主要目的是提升模型的運算效率與梯度穩定性。與 LayerNorm 不同的是,RMSNorm 不會計算輸入的平均值,而是專注於根據輸入的均方根(RMS)進行縮放。
簡單來說它的運作方式如下。首先將每個輸入值平方,接著計算這些平方值的平均,再開根號得到 RMS 值。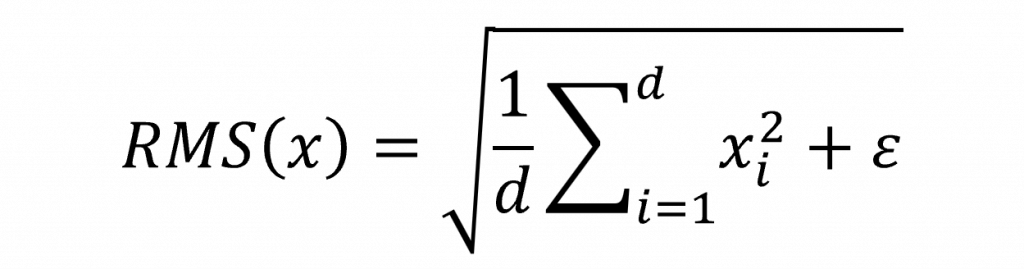
然後將原始輸入除以該 RMS,達到穩定整體數值的效果,最後再乘上一組可學習的縮放參數,使模型能根據任務需求自動調整輸出尺度。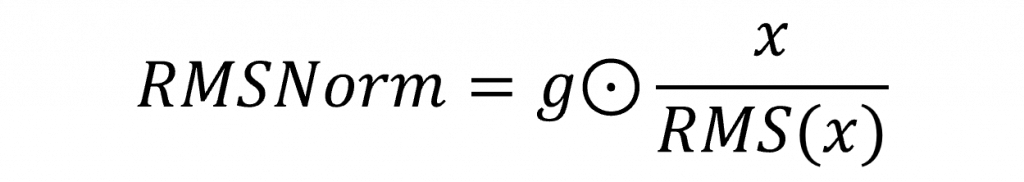
這組參數為逐維度的縮放向量,不僅簡化了計算流程,省去均值與方差的處理,也有助於保持反向傳播時的梯度穩定。在 LLaMA 架構中,則採用了 Pre-Norm 策略,將 RMSNorm 放置於注意力層與前饋神經網路,進一步提升訓練的穩定性。而在程式中我們可以如此表示。
import torch
import torch.nn as nn
class RMSNorm(nn.Module):
def __init__(self, dim, eps=1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def forward(self, x):
# x: (B, T, C)
rms = x.pow(2).mean(dim=-1, keepdim=True).add(self.eps).sqrt()
x_hat = x / rms
return self.weight * x_hat
當我們在講 Transformer 架構裡的 FFN 傳統的做法就是兩層線性轉換,中間夾一個像 ReLU 或 GELU 這樣的激勵函數。這種設計其實蠻直覺的但它有個問題,激勵函數是直接套用在整個中間層輸出上,沒辦法幫我們選擇哪些資訊比較重要,導致模型在處理複雜表達時比較不靈活。
用比較簡單的方式來看,整個 FFN 就像這樣運作先做一次線性轉換,套個激勵函數,再做一次線性轉換,因此公式可以寫成樣: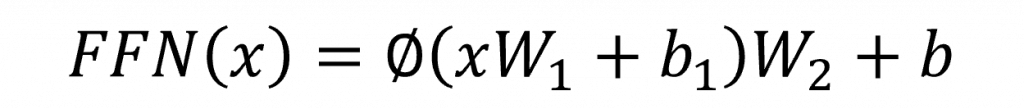
但這樣的設計它不會告訴你:「欸,這個資訊有用,那個沒用」。在深度學習裡當我們想要讓模型自己決定哪些特徵該留下,通常的做法就是用 Wx + b,讓它透過參數自己學。所以這時就出現了 SwiGLU 這個比較新穎的前饋層設計。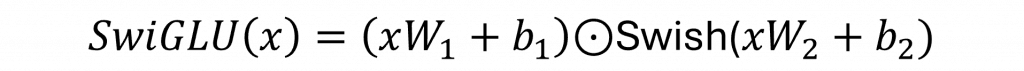
這個方法的核心在於引入一種閘控機制,概念上與我們學過的 LSTM 中使用 sigmoid(Wx + b) 的結構相似,用來判斷哪些訊號該被保留、哪些該被抑制。SwiGLU 的實作方式,是將中間層的輸出切成兩半其中一半直接作為主要訊號保留,另一半則經過 Swish 函數處理後,作為閘門訊號使用。
這個閘門負責調整哪些訊號應該被強化,哪些應該被抑制,等於替模型增加了一層訊息過濾的能力,使其在表達複雜關係時更具彈性,也更容易聚焦於關鍵特徵。對應的程式碼實作如下,展示了如何用 PyTorch 實現 SwiGLU 的前饋計算邏輯:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SwiGLU(nn.Module):
def __init__(self, d_model, d_ff):
super().__init__()
self.linear1 = nn.Linear(d_model, d_ff) # 主訊號
self.linear2 = nn.Linear(d_model, d_ff) # 閘門訊號
self.output_proj = nn.Linear(d_ff, d_model) # 最終輸出維度投影
def swish(self, x):
return x * torch.sigmoid(x)
def forward(self, x):
gate = self.swish(self.linear2(x)) # 閘門經 Swish
signal = self.linear1(x) # 主訊號
fused = signal * gate # 逐元素相乘
return self.output_proj(fused) # 投影回輸出維度
RoPE(Rotary Positional Embedding)是一種相當有趣且逐漸成為主流的位置信息編碼方式,它徹底改變了我們過去處理位置的方法。傳統的 Positional Encoding 通常是將一組 sin/cos 值加進詞向量中,等於是替每個詞貼上位置標籤。但 RoPE 採取的是完全不同的策略它不加而是轉進向量中。
更具體地說RoPE 將位置資訊以旋轉的方式直接作用在注意力機制中的 Query 和 Key 向量上。可以想像一下原始的向量是一根箭頭,而位置資訊就像是在多維空間中給這根箭頭旋轉一個角度,讓每個位置的向量指向不同的方向。這種旋轉式融合會讓模型更自然地感知相對位置,特別在處理長距離依賴的文本時,效果相當顯著。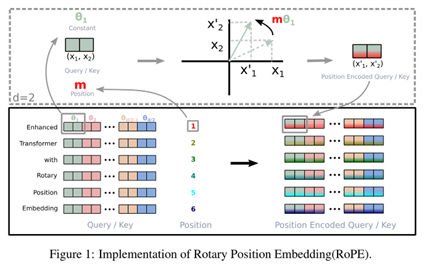
當我們看圖中上半部的時候,其實它就是在講 RoPE 是怎麼動手處理這些向量的,假設現在我們只看一小部分的向量,也就是 Query 或 Key 裡面的一對維度首先 θ₁ 是根據位置算出來的一個角度,就有點像以前 Positional Encoding 用 sin/cos 去搞出的那些週期性訊號。然後紅色的 m 就是你目前這個詞的位置(比如說是第 1 個字、第 2 個字…這樣)。
接著你原本那個向量是 (x₁, x₂),RoPE 就是拿那個位置算出來的角度 mθ₁,然後把這個向量整個旋轉一下。想像一下你在平面上拿著一根箭頭,把它轉個角度,方向就變了,但它還是同樣的長度。而這個轉過角度的新向量 (x′₁, x′₂),就是經過 RoPE 編碼後的版本。這種方式不只加上了位置感,而且還讓每個位置的向量指向不一樣的方向,這對模型來說非常有幫助,因為它就能更靈活地理解 誰跟誰的距離感 這種語言特性。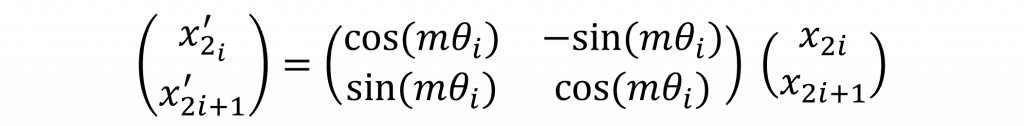
在數學實作上,RoPE 結合了 sin 與 cos 函數所構成的旋轉基底(這點與傳統方法相似),圖像上你可以把它想成,對於每一維的特徵,RoPE 都是在複數平面上轉了一圈而這個角度由位置決定。值得注意的是,它所使用的參數 θ 和傳統 Positional Encoding 中的 10000^(2i/d) 結構其實很接近,只是 RoPE 沒有把它當成加法項處理,而是作為旋轉角度使用。這也意味著 RoPE 可以自然保留向量之間的相對位置信息,並在注意力內積的過程中持續發揮作用,而這樣子的好處是,因此注意力可天然編碼相對距離 m−n 使其知道序列之間的距離,而原始的RoPE我們可以如此撰寫
import torch
class RoPEOriginal:
def __init__(self, seq_len, dim, base=10000.0, device="cuda"):
# 確保維度是偶數,因為 RoPE 會將維度分成兩半處理
assert dim % 2 == 0
half = dim // 2
# 建立索引,用於計算不同頻率的旋轉角度
idx = torch.arange(half, device=device)
# 計算每個維度對應的旋轉頻率比例 θ
# theta = base^(-2i/dim)
theta = base ** (-2 * idx / dim)
# 建立序列位置 pos,形狀為 [seq_len, 1]
pos = torch.arange(seq_len, device=device).float().unsqueeze(1)
# 計算位置與頻率的乘積角度矩陣 [seq_len, dim/2]
angles = pos * theta.unsqueeze(0)
# 預先儲存 cosine 與 sine 值,供後續旋轉使用
self.cos = angles.cos() # [seq_len, dim/2]
self.sin = angles.sin() # [seq_len, dim/2]
def apply(self, x):
# x 的形狀為 [batch, seq_len, dim]
# 將最後一個維度拆分成偶數與奇數索引兩部分
x1, x2 = x[..., ::2], x[..., 1::2]
# 將 cos 和 sin 的形狀擴展以便與 x 對齊
# 形狀變為 [1, seq_len, 1, dim/2]
cos = self.cos.unsqueeze(0).unsqueeze(2)
sin = self.sin.unsqueeze(0).unsqueeze(2)
# 套用旋轉位置編碼公式
# x1p = x1 * cos - x2 * sin
# x2p = x1 * sin + x2 * cos
x1p = x1 * cos - x2 * sin
x2p = x1 * sin + x2 * cos
# 將旋轉後的結果重新拼接回 [batch, seq_len, dim]
return torch.stack([x1p, x2p], dim=-1).flatten(-2)
其實你仔細看程式碼就會發現,原本的 RoPE 是先把整個 cos/sin 的表格都算好,這種做法在序列長度不長、模型又比較小的時候還算 OK。但一旦進入長序列訓練或推理這樣的表格就會使用超多記憶體。LLaMA 2 為了解決這問題,就改成「動態計算」cos 跟 sin,不再預先建立整張表。還有一點原本的頻率縮放是用 10000^(2i/d),但 LLaMA 2 把它換成了 base^(−d/2i),其實兩種寫法在數學上是等價的,只是後者看起來更簡潔,還直接表達出每半個維度頻率會降低的這個特性。
import torch
import torch.nn.functional as F
class RoPELlama2:
def __init__(self, dim, base=10000.0, device="cuda"):
assert dim % 2 == 0, "dim 必須為偶數"
half = dim // 2
# 頻率比例 (inv_freq),根據維度遞減
# θ_i = base^(-2i/dim)
self.inv_freq = base ** (-torch.arange(0, half, device=device).float() / half)
self.device = device
def get_cos_sin(self, seq_len):
# 建立位置索引 [seq_len]
pos = torch.arange(seq_len, device=self.device).float()
# 計算每個位置的角度 pos * inv_freq -> [seq_len, dim/2]
angles = torch.einsum('i,j->ij', pos, self.inv_freq)
# cos, sin 形狀 [seq_len, dim/2]
cos = angles.cos()
sin = angles.sin()
return cos, sin
def apply_rotary(self, x, cos, sin):
# 將維度拆成兩半 (even, odd)
x1 = x[..., ::2]
x2 = x[..., 1::2]
# 擴展 cos, sin 尺寸匹配
cos = cos.unsqueeze(0).unsqueeze(2) # [1, seq_len, 1, head_dim/2]
sin = sin.unsqueeze(0).unsqueeze(2)
# 套用旋轉公式
x_rotated_even = x1 * cos - x2 * sin
x_rotated_odd = x1 * sin + x2 * cos
# 合併回原始形狀
return torch.stack([x_rotated_even, x_rotated_odd], dim=-1).flatten(-2)
在 LLaMA 3 中,為了支援極長上下文 RoPE 的設計再最關鍵的變化是將旋轉頻率的 base 值從 LLaMA 2 的 10000 提升至 500000,這樣的調整使得角度變化的頻率下降得更慢,進而讓模型在面對長距離的 token 時仍能保持穩定且可區分的相對位置信息。
由於 sin 與 cos 本質上是週期函數,當序列長度變得非常長時,若 base 選得過小,會出現位置編碼繞回來的現象,使得序列尾端的位置信息與開頭產生混淆。而提升 base 的設定,正是為了拉長這樣的週期,避免長序列尾端出現與序列開頭環環相扣的錯位對齊問題,從而確保模型能穩定地捕捉遠距依賴關係。
import torch
class RoPELLama3:
def __init__(self, head_dim, max_seq_len=4096, base=500000.0, device="cuda", dtype=torch.float32):
# head_dim 必須為偶數
assert head_dim % 2 == 0
self.dim = head_dim
self.device = device
self.dtype = dtype
# LLaMA 3 採用較大的 base(500000)以支援長上下文
half = head_dim // 2
idx = torch.arange(half, device=device, dtype=dtype)
inv_freq = 1.0 / (base ** (idx / half)) # 頻率倒數,用於控制角度變化速度
# 建立位置張量 [seq_len, 1]
pos = torch.arange(max_seq_len, device=device, dtype=dtype).unsqueeze(1)
# 角度矩陣 [seq_len, dim/2]
angles = pos * inv_freq.unsqueeze(0)
# 儲存 cosine/sine 值供後續使用
self.register_buffers(angles)
def register_buffers(self, angles):
self.cos_cached = angles.cos() # [seq_len, dim/2]
self.sin_cached = angles.sin() # [seq_len, dim/2]
def apply_rotary_emb(self, x, seq_len=None):
if seq_len is None:
seq_len = x.shape[1]
# 取對應長度的 cos/sin
cos = self.cos_cached[:seq_len].unsqueeze(0).unsqueeze(2) # [1, seq_len, 1, dim/2]
sin = self.sin_cached[:seq_len].unsqueeze(0).unsqueeze(2)
# 拆分偶數與奇數索引
x1, x2 = x[..., ::2], x[..., 1::2]
# 旋轉操作
x1p = x1 * cos - x2 * sin
x2p = x1 * sin + x2 * cos
# 合併回 [batch, seq_len, num_heads, head_dim]
return torch.stack([x1p, x2p], dim=-1).flatten(-2)
並且你可以看到 LLaMA 3 不再在每次 forward pass 中動態生成 sin 與 cos 表格,而是在初始化時就根據預設的最大序列長度(如 4096 或更長)預先計算好整張角度矩陣並緩存起來。這種方式在推理時只需從快取中擷取對應長度的部分,兼顧了執行效率與記憶體使用。
Grouped-Query Attention(GQA) 的核心想法是讓多個查詢(Query)頭共用較少數量的鍵(Key)和值(Value)頭。假設有 H 個 attention 頭,我們可以將它們分成 G 組,讓每組共用同一組 Key 和 Value。這麼做的好處包括:
在 LLaMA 系列模型中ROPE 是套用在 q 和 k 上,因此在此實作中我們也使用該作法。
class GQAAttention(nn.Module):
def __init__(self, dim, num_heads, num_kv_heads, rope_base=500000.0, max_seq_len=4096):
super().__init__()
assert num_heads % num_kv_heads == 0 # 確保 Query 頭數能被 KV 頭數整除(好做分組)
self.dim = dim # 輸入特徵維度
self.h = num_heads # Query 總頭數
self.kvh = num_kv_heads # KV 頭數
self.head_dim = dim // num_heads # 每個 attention 頭的維度
# 線性轉換層:生成 Q, K, V
self.wq = nn.Linear(dim, dim, bias=False) # 為所有 Q 頭產生 Q
self.wk = nn.Linear(dim, self.kvh * self.head_dim, bias=False) # 為 G 組產生 K
self.wv = nn.Linear(dim, self.kvh * self.head_dim, bias=False) # 為 G 組產生 V
self.wo = nn.Linear(dim, dim, bias=False) # 輸出映射層
# Rotary Positional Embedding:LLaMA 風格的位置編碼
self.rope = RoPELLama3(self.head_dim, max_seq_len=max_seq_len, base=rope_base)
def forward(self, x, mask=None):
B, T, C = x.shape # B: batch size, T: sequence length, C: hidden dim
# 產生 Q, K, V,並 reshape 成多頭格式
q = self.wq(x).view(B, T, self.h, self.head_dim)
k = self.wk(x).view(B, T, self.kvh, self.head_dim)
v = self.wv(x).view(B, T, self.kvh, self.head_dim)
# 套用 Rotary Positional Embedding 到 Q 和 K 上
q = self.rope.apply_rotary_emb(q, seq_len=T)
k = self.rope.apply_rotary_emb(k, seq_len=T)
# 將較少的 KV 頭複製,使其能與所有 Q 頭對應
group_size = self.h // self.kvh # 每組共享多少 Q 頭
k = k.repeat_interleave(group_size, dim=2)
v = v.repeat_interleave(group_size, dim=2)
# 計算注意力分數
attn_scores = torch.einsum("bthd,bThd->bhtT", q, k) / math.sqrt(self.head_dim)
# 如果有 mask,將無效位置設為 -inf 以避免注意力聚焦
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 0, float("-inf"))
# 計算 softmax 注意力權重
attn = torch.softmax(attn_scores, dim=-1)
# 使用注意力權重加權 V 並輸出
out = torch.einsum("bhtT,bThd->bthd", attn, v).contiguous().view(B, T, C)
return self.wo(out)
到這裡為止我們可以清楚地看到,目前的大型語言模型在設計上已進行了多項技術層面的革新,而這些改良往往不只是單純的效能優化,更是針對原有方法進行深度的重構。像是 RoPE 的演進過程便是一個鮮明的例子從原始版本中的預算旋轉表格,到 LLaMA 2 採用的動態計算策略,再到 LLaMA 3 透過提升 base 值來穩定長距離表徵,這些變化雖然在實作上大幅度偏離了傳統 Positional Encoding 的架構,但其核心概念仍舊保留在其中。
這些創新不是完全拋棄舊技術,而是在其原理的基礎上,針對現代模型的需求進行了極具針對性的強化與轉化。這種保留骨幹、重構細節的策略,幾乎成為了所有AI模型的演化方式。
今天我們已經把 LLaMA 這個語言模型的架構拆解完畢,讓大家對它的內部運作有了初步了解。那明天呢我們會進一步教你們怎麼從零開始建立一整個 LLaMA 模型,還會帶你操作怎麼登入 Hugging Face、取得權限,還有其他實用功能。
接下來我們也會陸續介紹 base 版本跟 chat 版本的建構方式,以及怎麼優化推理速度、提升效能等重要資訊。這些通通都會在之後的內容中告訴你們,就敬請期待囉!
我們明天見~


 iThome鐵人賽
iThome鐵人賽