本來只打算分享一下這次專案的費用就結束這回合。
最後一天,原本預計要做簡單的成本分享...但是對目前的專案成果實在太不滿意,所以就...
現行實作方式是透過 Bedrock 調用 Claude 3.7 Sonnet,但是每一次呼叫時間至少需要 30 秒以上。以聊天性質的占卜小助手來說,實在太慢了...
於是嘗試在程式碼中加上 Log
import boto3
import json
import time
class BedrockService:
def __init__(self):
self.client = boto3.client("bedrock-runtime", region_name="ap-northeast-1")
# 公開方法
def daily_tarot_reading(self, system_role, prompt):
return self.__daily_tarot(system_role, prompt)
# ===== Daily Tarot =====
def __daily_tarot(self, system_role, prompt):
"""
呼叫 Bedrock 服務進行每日占卜
system_role: 要提供給模型的角色設定
prompt: 要輸入的提示詞
"""
model_id = 'arn:aws:bedrock:ap-northeast-1:590184072539:inference-profile/apac.anthropic.claude-3-7-sonnet-20250219-v1:0'
params = {
"system": system_role,
"anthropic_version": "bedrock-2023-05-31",
"messages": [
{"role": "user", "content": [{"type": "text", "text": prompt}]}
],
"max_tokens": 1200,
"temperature": 0.7
}
print("\n[Bedrock] === Start daily tarot reading ===")
print(f"Model: {model_id}")
print(f"max_tokens={params['max_tokens']}, temperature={params['temperature']}")
start_all = time.time()
# Step 1: 準備請求
t1 = time.time()
body = json.dumps(params)
t2 = time.time()
# Step 2: 呼叫 Bedrock API
try:
response = self.client.invoke_model(modelId=model_id, body=body)
except Exception as e:
print("[Bedrock] invoke_model failed:", str(e))
raise
t3 = time.time()
# Step 3: 處理回傳結果
output = json.loads(response['body'].read())
t4 = time.time()
result = output['content'][0]['text']
elapsed_total = round(t4 - start_all, 2)
# ===== 印出詳細時間 =====
print(f"[Bedrock] Prepare body: {round(t2 - t1, 2)}s")
print(f"[Bedrock] Invoke API: {round(t3 - t2, 2)}s")
print(f"[Bedrock] Parse JSON: {round(t4 - t3, 2)}s")
print(f"[Bedrock] Total time: {elapsed_total}s")
print(f"[Bedrock] Response length: {len(result)} chars\n")
return result
輸出結果
[Bedrock] === Start daily tarot reading ===
Model: arn:aws:bedrock:ap-northeast-1:590184072539:inference-profile/apac.anthropic.claude-3-7-sonnet-20250219-v1:0
max_tokens=1200, temperature=0.7
[Bedrock] Prepare body: 0.0s
[Bedrock] Invoke API: 20.97s
[Bedrock] Parse JSON: 0.0s
[Bedrock] Total time: 20.97s
[Bedrock] Response length: 859 chars
END RequestId: 2c3d8cf3-b94f-4e55-b045-1276a16c5809
REPORT RequestId: 2c3d8cf3-b94f-4e55-b045-1276a16c5809 Duration: 22283.60 ms Billed Duration: 22284 ms
光是 Invoke AI Model 就要花掉 20 秒以上,可以說是整個 Request 都在等 AI 回覆。
既然是在等 AI Model 回覆,那就從使用中的模型下手。
區域性共用配置
先前在Day 20 因為在 Bedrock Playground 中不斷遇到 ThrottlingException 錯誤訊息,所以從一般的 on-demand 模型切換成了 cross-region (跨區域推論)模型,並且在後續的程式開發中繼續沿用。
但現在遇到問題了,似乎得要重新審視一下直接在功能上使用它是不是適當。
程式使用的 inference profile 是 AWS 提供的共用 inference profile。
使用版本:
arn:aws:bedrock:ap-northeast-1:590184072539:inference-profile/apac.anthropic.claude-3-7-sonnet-20250219-v1:0
Inference Profile 分成兩種類型:
目前使用的是 AWS 提供的 Inference Profile,也就是 SYSTEM_DEFINED,只能使用多區間導向。
另外,從官方文件:Increase throughput with cross-Region inference
Inference profiles currently don't support Provisioned Throughput.
可以得知:跨區域推論模式是 不支援 Provisioned Throughput 的。
(Provisioned Throughput 是預先購買以保留模型運算資源)
換句話說,使用跨區域推論時,送出的請求可能還是需要排隊,也有可能遇到延遲。
Claude 3.7 Sonnet 不包含在 AWS 的 Latency-Optimized Inference 中
Latency-Optimized Inference
可讓基礎模型在推論時具有 更低延遲、更快回應的特性,特別適合需要即時互動的應用,例如:
根據這次專案的測試,使用 AWS 提供的共用 inference profile(SYSTEM_DEFINED)時,Bedrock 的推理延遲約落在 20 秒上下,若遇到尖峰時間會更久。
另從官方文件可知:
雖然 Inference Profile 能讓多區共用模型端點,避免高峰期瓶頸,但目前它並不支援 Provisioned Throughput。
即便使用的是 inference profile ARN,仍然會走 AWS 的共享資源,無法享有專屬的 GPU 實例與低延遲保證。
若要真正提升穩定度與速度,大概只能直接呼叫綁定 Provisioned Throughput 的模型 ARN,或等 AWS 將 latency-optimized inference 擴展到該模型了吧...再不然就是直接拿出魔法小卡,直接去接官方 API!
[Bedrock] === Start daily tarot reading ===
Model: anthropic.claude-3-5-sonnet-20240620-v1:0
max_tokens=1200, temperature=0.7
[Bedrock] Prepare body: 0.0s
[Bedrock] Invoke API: 16.08s
[Bedrock] Parse JSON: 0.0s
[Bedrock] Total time: 16.08s
[Bedrock] Response length: 665 chars
END RequestId: 8dc37cd3-2ace-4810-9699-b6d3ce23d420
REPORT RequestId: 8dc37cd3-2ace-4810-9699-b6d3ce23d420 Duration: 17371.34 ms Billed Duration: 17372 ms
-> 有比較快 (一點點)
-> 會發生 ThrottlingException
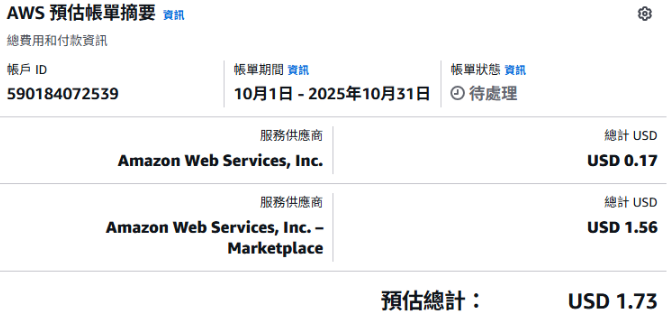
其中 AI 的花費: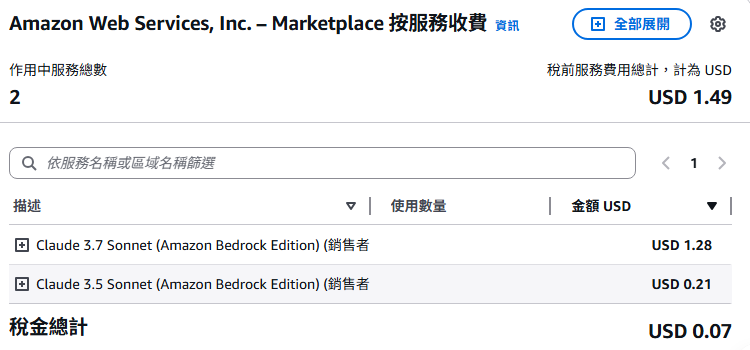
作為測試用是真的不貴,但要做為服務使用...這樣的執行速度在應用上的範圍就會大幅度受限。
這趟 30 天鐵人賽,從最初的發想、設計、開發、測試,到最後在雲端上成功占卜,過程中踩了無數坑,也學到比預期更多的東西。
雖然鐵人賽到這裡告一段落,但實驗還沒結束。
後續大概會嘗試改接官方 API,或許這個小小的專案就能達到原先的目標,成為能即時給予回應的占卜小助手。
懶的改文章了直接上圖: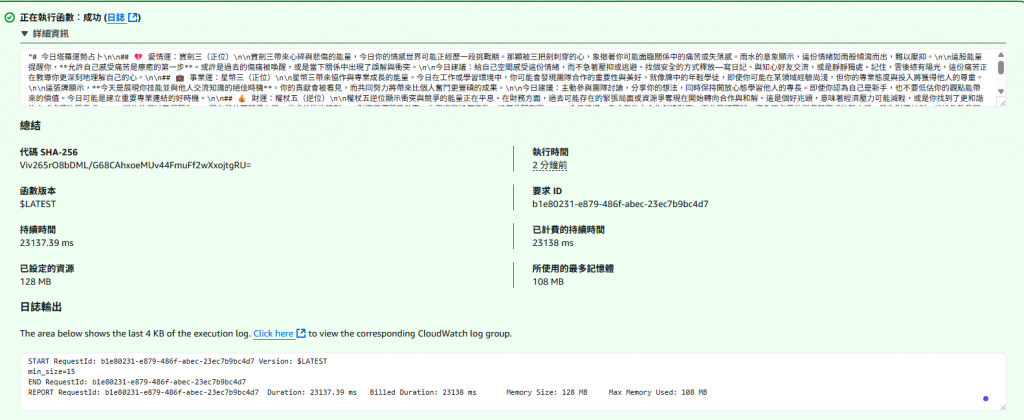
改叫官方 API 平均從 35 秒降到 20 秒,還是不夠快...
Log 紀錄如下:
[Anthropic] === Start daily tarot reading ===
Model: claude-3-7-sonnet-latest
max_tokens=1200, temperature=0.7
[Anthropic] Prepare body: 0.00s
[Anthropic] Invoke API: 18.50s
[Anthropic] Parse JSON: 0.06s
[Anthropic] Total time: 18.56s
[Anthropic] Response length: 868 chars
END RequestId: ebc61b77-62b9-4e87-8632-cecf87f36031
REPORT RequestId: ebc61b77-62b9-4e87-8632-cecf87f36031 Duration: 24163.58 ms Billed Duration: 25418 ms Memory Size: 128 MB Max Memory Used: 117 MB Init Duration: 1254.17 ms
調整 system_role + 降低 max_tokens 可以再加快一點
大概是從 20 -> 16 秒
START RequestId: fe9627f8-2f4b-464c-b1ac-0ab84b27c697 Version: $LATEST
min_size=15
[Anthropic] === Start daily tarot reading ===
Model: claude-3-7-sonnet-latest
max_tokens=800, temperature=0.7
[Anthropic] Prepare body: 0.00s
[Anthropic] Invoke API: 14.92s
[Anthropic] Parse JSON: 0.00s
[Anthropic] Total time: 14.92s
[Anthropic] Response length: 716 chars
END RequestId: fe9627f8-2f4b-464c-b1ac-0ab84b27c697
REPORT RequestId: fe9627f8-2f4b-464c-b1ac-0ab84b27c697 Duration: 15651.19 ms Billed Duration: 15652 ms Memory Size: 128 MB Max Memory Used: 107 MB

