本次實作是 RAG Chatbot 專案的最終版本,旨在整合所有先進功能,包括 大型語言模型(LLM)的生成能力、對話記憶(Conversation Memory),以及自動化的品質評估機制。
| 核心功能 | 實作方式 | 價值 |
|---|---|---|
| LLM 生成 | langchain.chat_models.ChatOpenAI |
根據檢索結果,生成自然、連貫的回答。 |
| 對話記憶 | 歷史記錄傳遞 (chat_history) |
支援多輪對話,使回答更具上下文連貫性。 |
| 自動評估 | ROUGE-L & BLEU 評分機制 | 提供客觀指標衡量系統回答的品質與準確性。 |
| 介面整合 | Gradio gr.Chatbot |
最終的 Web 應用介面。 |
本版本程式碼(Day 29 最終整合版)是基於 LangChain 實現的 RAG 核心,並加入了多項生產級功能。
系統使用 OpenAI 的 Embedding 模型和 GPT-3.5-turbo 作為 LLM。知識庫 (docs.pkl) 載入後直接轉換為 FAISS 向量庫和檢索器 (retriever)。
# RAG 核心組件
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
vectorstore = FAISS.from_documents(docs, embeddings)
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
llm = ChatOpenAI(model="gpt-3.5-turbo")
chatbot 函數是 RAG 系統的最終實現。它不僅執行檢索,更整合了對話歷史來優化 Prompt:
# Day 29 新增:加入對話記憶
chat_history = []
def chatbot(query):
# 擷取最近三輪對話作為上下文
history_text = "\n".join([f"使用者: {h[0]}\n助理: {h[1]}" for h in chat_history[-3:]])
full_prompt = f"{system_prompt}\n\n{history_text}\n\n使用者問題: {query}"
# ... 檢索與 LLM 生成 ...
# 儲存對話歷史
chat_history.append((query, answer))
# ...
優勢:在 LLM 生成階段,模型能參考過往對話,減少重複回答,並能處理代詞指涉(如「它在哪裡?」)。
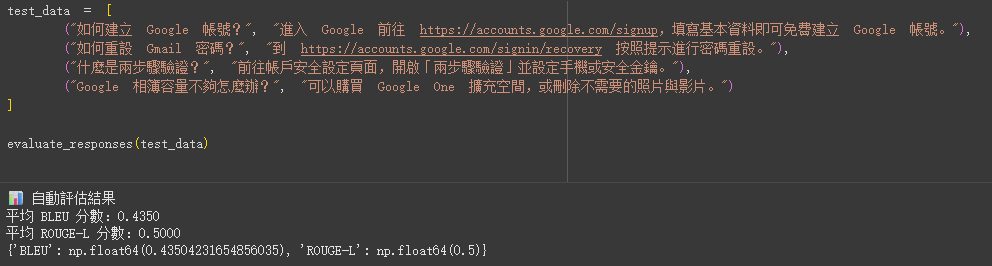
為了客觀衡量 RAG 系統的表現,我們新增了 evaluate_system 函數,使用業界標準的 ROUGE 和 BLEU 分數來比較系統回答 (response) 與預期答案 (expected) 的相似度。
def evaluate_system(test_cases):
rouge = Rouge()
results = []
for q, expected in test_cases:
response = chatbot(q)
# ROUGE-L:衡量回答與預期答案的最長公共子序列相似度
rouge_score = rouge.get_scores(response, expected)[0]["rouge-l"]["f"]
# BLEU:衡量回答的詞彙精準度
bleu_score = sentence_bleu([expected.split()], response.split())
results.append((q, response, rouge_score, bleu_score))
return results
test_data = [
("如何建立 Google 帳號?", "進入 Google 前往 https://accounts.google.com/signup,填寫基本資料即可免費建立 Google 帳號。"),
("如何重設 Gmail 密碼?", "到 https://accounts.google.com/signin/recovery 按照提示進行密碼重設。"),
("什麼是兩步驟驗證?", "前往帳戶安全設定頁面,開啟「兩步驟驗證」並設定手機或安全金鑰。"),
("Google 相簿容量不夠怎麼辦?", "可以購買 Google One 擴充空間,或刪除不需要的照片與影片。")
]
evaluate_responses(test_data)


 iThome鐵人賽
iThome鐵人賽