我們在測試集上確認了 ResNet34 是我們的冠軍模型。今天,我們將使用兩大評估工具——混淆矩陣 (Confusion Matrix) 和 ROC 曲線 (Receiver Operating Characteristic),對模型進行最深入的診斷,找出模型的優勢與盲點。最後,我們將把冠軍模型部署到 Hugging Face Spaces 平台。
一、混淆矩陣分析:找出模型的盲點
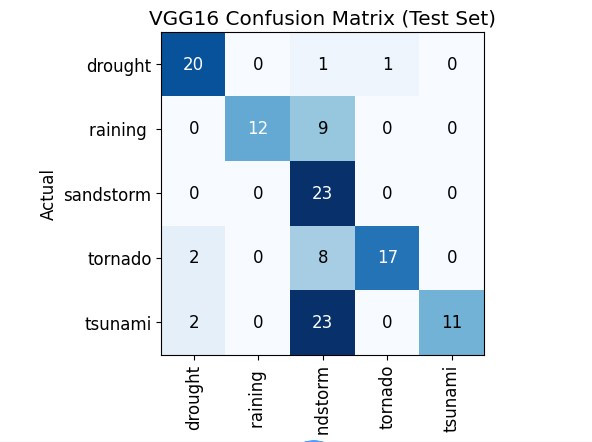
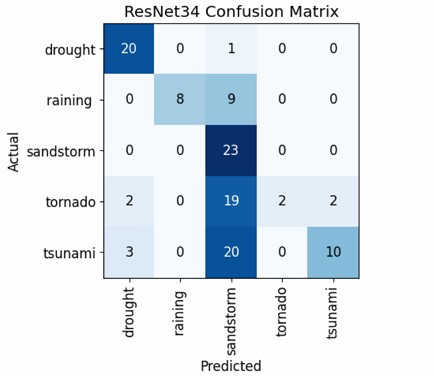
單純的「準確度」無法告訴我們模型錯在哪裡。混淆矩陣詳盡地展示了每個類別被誤判到其他類別的具體數量,是診斷模型盲點的利器。我使用 Fast.ai 的 ClassificationInterpretation 類來生成冠軍模型 ResNet34 的混淆矩陣。
# 對訓練好的 ResNet34 進行解釋並計算矩陣
interp_resnet = ClassificationInterpretation.from_learner(learn_resnet)
# 繪製混淆矩陣
interp_resnet.plot_confusion_matrix(figsize=(8, 8))

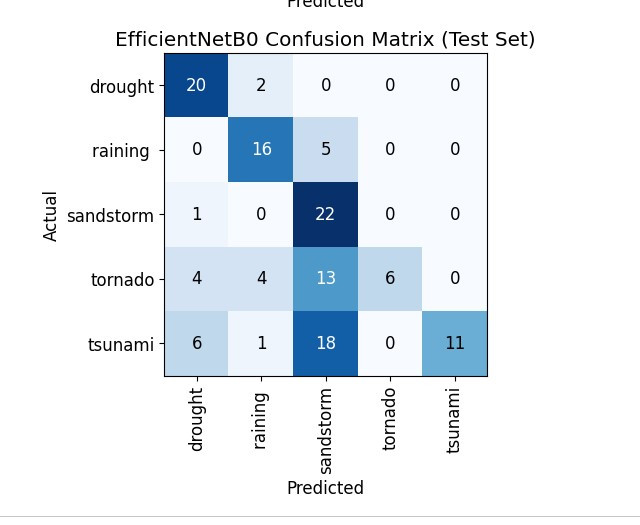
我順便做另外兩個的混淆矩陣,可以拿來參考~
二、訓練狀態診斷:過度擬合分析
什麼是過度擬合 (Overfitting)?
過度擬合 (Overfitting) 是機器學習中一種常見的現象,指的是模型在訓練集上表現得非常好,甚至能達到幾乎完美的準確率,但對**未見過的數據(例如驗證集或測試集)的表現卻很差。你可以將過度擬合想像成學生「死記硬背」教科書上的每一個細節和錯誤,而非「理解」**核心概念。
在深度學習中,當模型過度擬合時,它開始學習訓練數據中的噪聲 (Noise) 或不相關的細節。這導致模型的泛化能力 (Generalization ability) 下降,無法將所學知識成功應用到現實世界的新數據上。
我們的目標是訓練出一個泛化能力強的模型,因此必須透過觀察訓練和驗證損失曲線(如 Day 23 所見),在模型開始過度擬合時,立即實施早期停止 (Early Stopping),以鎖定具有最佳泛化性能的權重。
舉Resnet 為例子:
這種 「訓練損失持續下降,但驗證損失停止改善(甚至微弱上升)」 的趨勢,正是過度擬合 (Overfitting) 的典型訊號。模型已經學得太過細節化,開始記住訓練集的雜訊,犧牲了對一般數據的適應性。
最終決策 (早期停止):
為了獲得最穩定的泛化能力,我們必須實施 早期停止 (Early Stopping) 原則。我們選用 驗證損失達到最低點時 的權重(大約在第 4 Epoch),而非訓練結束時的權重。這確保了我們選出的 ResNet34 冠軍模型是最穩定、泛化能力最強的版本。

