在我們日常開展美股行情分析與量化策略開發的過程中,長期依賴K線聚合數據總會遇到一個共性問題。K線圖表的視覺效果簡潔清晰,能夠快速呈現週期價格波動,但本質上是對海量交易資訊的二次壓縮與整合。
在數據聚合的過程中,大量短時交易行為、資金流動細節都會被自動過濾掉。這也解釋了為什麼很多策略在歷史回測中表現優異,落地實測卻偏差極大。在深入使用美股Tick數據後我們徹底明白:資本市場的價格波動,並非圖表線條的機械變動,而是由無數次獨立撮合交易持續推動形成的完整動態過程。
一、Tick逐筆數據的核心定義與基礎欄位構成
簡單來說,美股Tick數據可以理解為市場每一次交易完成後的原始數據快照,完整記錄了單次交易的全部有效資訊,沒有經過任何人為聚合與平滑處理。這套數據主要由五大核心欄位組成,精準還原市場微觀運行狀態: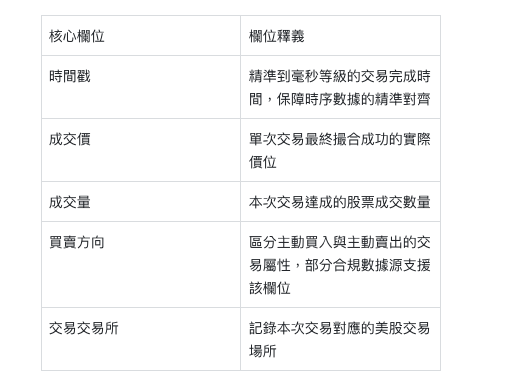
依託這套精細化的原始數據,原本碎片化、跳躍式的價格波動,會被還原成連續完整的交易鏈路。我們不再只能看到行情變動的最終結果,而是可以清晰追溯每一次價格變動對應的交易行為。
二、實時行情採集的兩種方案:效率與時效性對比
想要穩定獲取美股實時Tick數據,業界主流技術方案分為兩種,二者在時效性、運行效率、適配場景上存在明顯差異,也是量化開發中必須取捨的核心要點:
1.HTTP定時輪詢方案
該方案的核心邏輯是透過程式定時呼叫數據介面,拉取最新的行情資訊。整體開發門檻低、邏輯簡單,但存在天然的時效性缺陷,數據延遲普遍偏高。僅適用於對數據實時性要求較低、以靜態行情觀測和基礎數據統計為主的輕量場景,完全無法適配高頻Tick數據的採集需求。
2. WebSocket長連線推送方案
不同於輪詢模式,WebSocket只需初次建立持久通訊鏈路,伺服器就會主動持續推送最新交易數據,無需用戶端反覆發起請求。一旦市場產生新的交易行為,數據會即時同步更新,幾乎無額外延遲,是實時數據運算、高頻策略分析的最優解。目前也是業界擷取逐筆高頻數據的主流技術選型。
在實際專案開發中,我們可以藉助AllTick API簡潔的封裝邏輯,快速完成美股Tick數據的訂閱與實時採集工作。
三、實時Tick數據接入完整實操程式碼
整體接入邏輯清晰易懂,核心流程為建立長連線通道、提交標的訂閱指令、持續監聽接收實時推送數據,完整可執行程式碼如下:
import websocket
import json
def on_message(ws, message):
data = json.loads(message)
ticks = data.get("ticks", [])
for item in ticks:
time = item.get("time")
price = item.get("price")
volume = item.get("volume")
exchange = item.get("exchange")
print(time, price, volume, exchange)
def on_open(ws):
sub_msg = {
"type": "subscribe",
"symbols": ["AAPL", "TSLA", "NVDA"]
}
ws.send(json.dumps(sub_msg))
ws = websocket.WebSocketApp(
"wss://api.alltick.co/stock/tick",
on_open=on_open,
on_message=on_message
)
ws.run_forever()
整套程式碼的運行邏輯十分直觀,透過持久化長連線實現穩定的數據訂閱,後續所有的數據清洗、特徵統計、策略迭代等開發工作,都可以基於這份實時原始數據流展開拓展。
四、Tick數據標準化處理與存儲適配方案
直接採集到的原始Tick數據,存在格式雜亂、冗餘資訊較多等問題,不適合直接用於量化計算、數據統計和長期歸檔存儲,必須經過標準化加工處理。
我們長期沿用的標準化處理流程為:原始數據接收 → 暫存快取緩衝 → 持久化落庫 → 二次深度加工。在存儲介質的選擇上,可依專案規模靈活適配:SQLite、Redis等輕量儲存工具,足以滿足日常實驗除錯和中小型策略回測需求;如果是需要7×24小時穩定運行的專業化行情系統,時序資料庫的穩定性和讀寫效率會更適配海量高頻Tick數據的存儲場景。
五、長期運行避坑:高頻數據採集的穩定性細節要點
WebSocket長連線的開發邏輯簡單易懂,但在長期不間斷的生產運行場景中,諸多細節問題會直接影響數據完整性,進而導致量化分析結果失真,是開發者極易忽略的關鍵要點:
首先是網路波動引發的斷連問題。公網網路環境存在不確定性,長連線中斷屬於高頻突發情況。若未提前配置自動重連機制,數據傳輸會直接終止,形成數據空洞,導致後續分析樣本缺失、結論失效。
其次是訂閱規模與設備算力不匹配。隨著訂閱股票標的數量增多,海量高頻數據會持續湧入,若未做批次處理最佳化,本地算力和IO讀寫壓力會持續堆積,引發數據延遲、卡頓甚至丟失等問題。
最後是時間戳格式不統一的隱性問題。多批次採集的數據若未提前完成格式標準化,初期除錯不會出現異常,但在數據聚合、行情回放、批次統計階段,會產生持續性數據偏差,間接影響策略精準度。
六、Tick逐筆數據在量化場景的核心應用價值
相較於傳統聚合K線數據,Tick原始數據能夠挖掘出大量隱藏在行情背後的微觀交易訊號,有效彌補聚合數據的短板,核心應用價值集中在三個維度:
成交密度識別市場情緒:短時間內交易頻次與成交量的快速起伏,能夠直觀反映當下市場資金活躍度,幫助開發者精準捕捉短期情緒異動。
拆解價格微觀變動邏輯:市場每一次細微的價格波動,都對應真實的逐筆交易行為,完整的Tick記錄,是捕捉短期趨勢轉向訊號、識別支撐壓力區間的核心依據。
量價分佈判斷資金參與度:對比不同時段、不同價格區間的成交量差異,能夠清晰區分有效行情波動與無效市場震盪,精準判斷資金參與深度。
總結
從量化開發的實操角度來看,K線數據只能呈現市場漲跌的最終結果,而Tick逐筆數據能夠還原行情變動的底層成因。它將抽象的行情走勢,拆解為可量化、可追溯、可運算的原始交易數據流。
依託WebSocket技術獲取的實時Tick數據,具備低延遲、高靈活性、高穩定性的優勢。搭建完善的數據採集、處理與存儲體系後,我們能夠全天候捕捉最真實的市場動態,讓量化策略開發、行情分析、數據回測徹底擺脫聚合數據的資訊侷限,大幅提升量化體系的真實性與實用性。
 keddyyoung
keddyyoung
