前言:多數量化開發者都有的資料認知誤區
身為長期带队研發量化交易系統與金融行情中間件的技術負責人,我早期在接入 A 股行情 API 時,也曾抱持過非常普遍的錯誤觀念。過去我單純認為,Level1 與 Level2 行情的差異,僅止於資料更新速度的快慢,頂多是體驗上的差別,不會影響策略核心邏輯與判斷結果。
但隨著團隊投入漲停監控、盤口強度辨識、高頻博弈策略的開發與實盤驗證,我才真正意識到:兩者的差距並非延遲差異,而是資料維度與交易視角的根本性不同。尤其在漲停這種特殊盤面情境下,資料層次的落差,會直接改變程式對多空博弈的判讀,甚至造成回測完美、實盤頻繁失效的狀況。
漲停盤面具備很特殊的市場特性:價格被制度鎖定、不再向上浮動,表面看起來行情停滯,但實際上委託掛單、撤單、排隊撮合的動作從未停止。若開發者只依賴基礎行情資料,很容易誤判盤面處於靜止狀態,而高階行情才能還原底層真實的資金運行節奏。
一、研發痛點:為何漲停策略總是出現實盤偏差?
在一般震盪、趨勢行情中,透過價格、漲跌幅、累計成交量等基礎指標,足以支撐大部分量化邏輯運行。但漲停階段的交易邏輯完全反轉——價格失去波動性,所有的獲利訊號、風險訊號,全部隱藏在微觀盤口結構之中。
我复盘過大量策略異常案例,發現多數漲停策略失效,並非演算法設計缺陷,而是底層資料顆粒度不足。傳統 Level1 行情只能告訴我們「結果」,卻無法解釋「過程」,導致程式無法分辨真實強勢封板、與虛弱的假性封板,這也是量化開發最容易忽視的技術盲點。
簡單來說:普通行情看價格,漲停行情必須看結構,而基礎行情資料剛好缺失所有結構性資訊。
二、量化開發的真實數據需求:從「狀態判定」走向「行為解析」
以技術開發角度來看,漲停場景對行情資料的需求,已經從傳統的數值統計,升級為資金行為解析。我們在建構策略時,不再只需要判斷「是否漲停」,更需要即時掌握以下關鍵資訊:
這些屬於動態、微觀、過程型的市場特徵,是 Level1 資料天生無法覆蓋的領域,也是為什麼高精密量化策略必須依賴更高維度行情來源的核心原因。
三、Level1 基礎行情:只記錄結果,完全缺失交易過程
Level1 行情的定位屬於輕量級市場快照,欄位單純、結構簡潔,主要提供即時價格、區間高低價、漲跌幅、累計成交量等總結性數據。
當個股進入漲停狀態後,這組資料會呈現極度平整的走勢:價格固定、量能波動微弱,整體數據表現趨於靜止。從程式讀取的視角來看,會誤以為盤面已經沒有任何交易變化。
但真實市場並非如此。Level1 只會告知開發者「該標的已封鎖漲停」,卻無法呈現盤內所有細節:包含資金是否持續駐守、是否有主力悄悄撤退、隊列支撐是否充足等關鍵資訊,全部處於空白狀態。
因此我們可以總結:Level1 是典型的結果導向行情資料,適合大盤狀態辨識,完全不適合精細化的漲停盤口分析。
四、Level2 高階行情:還原漲停盤口真實的微觀博弈結構
相較於扁平化的基礎行情,Level2 高階行情能夠完整還原交易所原始委託簿結構,貼近市場最真實的交易細節。即便漲停價格鎖死,買一委託隊列仍會每秒不斷更迭、新增、撤單,動態從未停止。
我在長期介接行情 API、觀測盤口變化的過程中,透過 Level2 捕捉到大量基礎行情看不到的交易特徵:
其中 A 股獨有的「時間優先排隊機制」,是量化判斷封板強度的關鍵指標。誰的委託優先排入隊列、誰能優先成交,這套決定盤面強弱的微觀機制,只有 Level2 資料能夠完整呈現。
五、漲停場景下兩類行情資料的核心差異對照
價格鎖定的特殊環境,會極大放大 Level1 與 Level2 的能力差距,直接決定量化模型的判斷精準度,兩者差異可以整理如下: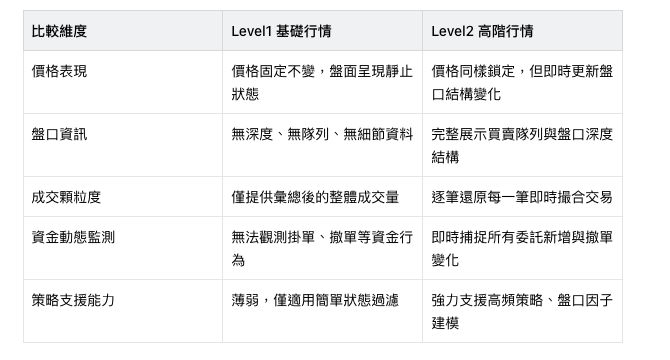
在實際開發場景中,這組差異是分辨「真封板」與「假封板」的關鍵,業界大多透過** AllTick API** 實現雙通道行情訂閱,一站式整合雙層資料來優化漲停監控邏輯。
六、工程實踐:雙層資料互補的訂閱架構(程式碼保留)
單一行情來源一定存在資訊盲點,我團隊的標準實踐方式為:以 Level1 做全域狀態快速過濾,以 Level2 做微觀盤口深度解析,兩者互補才能完整還原漲停真實盤勢。
import websocket
import json
def on_message(ws, message):
data = json.loads(message)
if data.get("type") == "level2":
print("盘口更新:", data["bids"][0], data["asks"][0])
if data.get("type") == "level1":
print("基础行情:", data["price"], data["volume"])
def on_open(ws):
sub = {
"action": "subscribe",
"symbol": "600000.SH",
"channels": ["level1", "level2"],
"id": 1
}
ws.send(json.dumps(sub))
ws = websocket.WebSocketApp("wss://api.alltick.co/ws",
on_message=on_message,
on_open=on_open)
ws.run_forever()
此架構的核心優勢非常明顯:Level1 快速標定漲停標的,Level2 持續解析內部資金強度,讓原本模糊的靜止盤面,變成可量化、可追蹤的動態博弈過程。
七、重新理解漲停本質:表面靜止、內部高頻博弈
累積多年量化開發經驗後,我對漲停盤面有了更清晰的定義:漲停從來不是交易停止,而是一場價格被限制的高頻資金對峙。
Level1 會把這段複雜的多空博弈,壓縮成單一個固定價格結果,隱藏所有風險與轉折訊號;而 Level2 的價值,就是把被壓縮的交易過程完整展開,讓開發者看見隊列增減、資金進退、成交脈衝等細微變化。
現階段許多高頻量化策略,都會單獨依賴 Level2 的隊列變化判斷封板強度,包含隊列增速、撤單突發頻率、成交時間集中性等因子,這些核心交易特徵,在 Level1 資料中都會完全消失。
八、技術落地與學術研究的雙層價值
從工程角度來看,雙層行情搭配能大幅提升策略穩定性、降低實盤誤判;從學術研究角度,這套資料架構也具備極高的市場分析價值。
Level1 提供宏觀市場狀態標籤,Level2 提供微觀交易行為樣本,兩者結合可以用來研究漲停存續機制、機構資金行為模式、炸板風險量化模型,是市場微觀結構研究與量化建模的重要資料底座。
九、結語
總結來說,Level1 帶給開發者的是「結果視角」,適合一般行情觀測;Level2 帶來的是「過程視角」,是精準量化開發不可或缺的基礎。
漲停場景之所以容易策略踩雷,正是因為多數人只看結果、不看過程。唯有結合 Level1 狀態過濾與 Level2 微觀解析,才能建構完整的盤口認知。這也是我在所有精進型量化專案中,都優先以 Level2 資料為核心判斷依據的原因——它最貼近市場真實的交易行為邏輯。
 keddyyoung
keddyyoung

 iThome鐵人賽
iThome鐵人賽