最近檢查vm主機,發現有以下錯誤訊息
一直重複發送,但看不太出來問題到底出在哪裡?
有人有遇過嗎?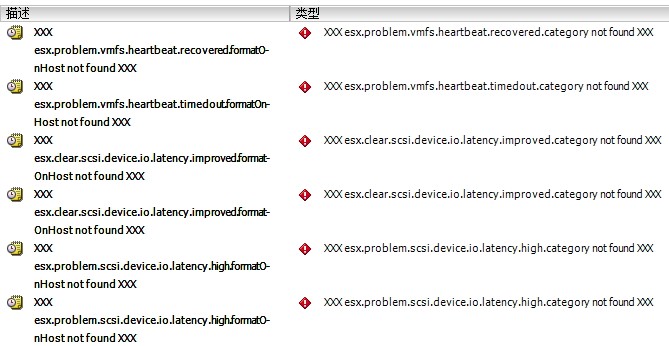
已邀請的邦友 {{ invite_list.length }}/5
ESX 每三秒鐘會去詢問一次你的 datastore 是否仍活著? 如果超過 16 秒沒有獲得 datastore 的回應, 就會觸發一次 timedout 事件.
從你的 Event 看來, 你的 datastore 有反覆發生: 斷線>連線>斷線>連線...的連續事件, 也就是一般稱為 flapping 的狀態, 此問題發生的原因有很多種可能性, 請洽商最了解您環境架構的 Storage 廠商協查.....無架構圖和相關設定內容, 大家無法隔空診斷...
根據您貼上的訊息中,看起來主要發生問題的部分為: vmfs ,scsi-device, problem, not found, esx.clear.scsi.device. 似乎是源於儲存裝置所導致產生的。
vmfs: VMware File System - WMware 檔案系統。
scsi-device: 基本指的都是存儲裝置的連結。
esx.clear.scsi.device. 可能為先前 未正常關機 或 當機 所致partition內有不乾淨(不正常)之檔案連結。
not found. 找不到,當然就會發生「問題」囉 -> Problem.
您參考看看!
