參照網頁的做法http://freeloda.blog.51cto.com/2033581/1275528
已經做到"crmsh資源管理"這步驟,但DRBD一直無法設定成功,卡關N星期了
懇求高手指點明路,小弟願給予酬勞 拜託
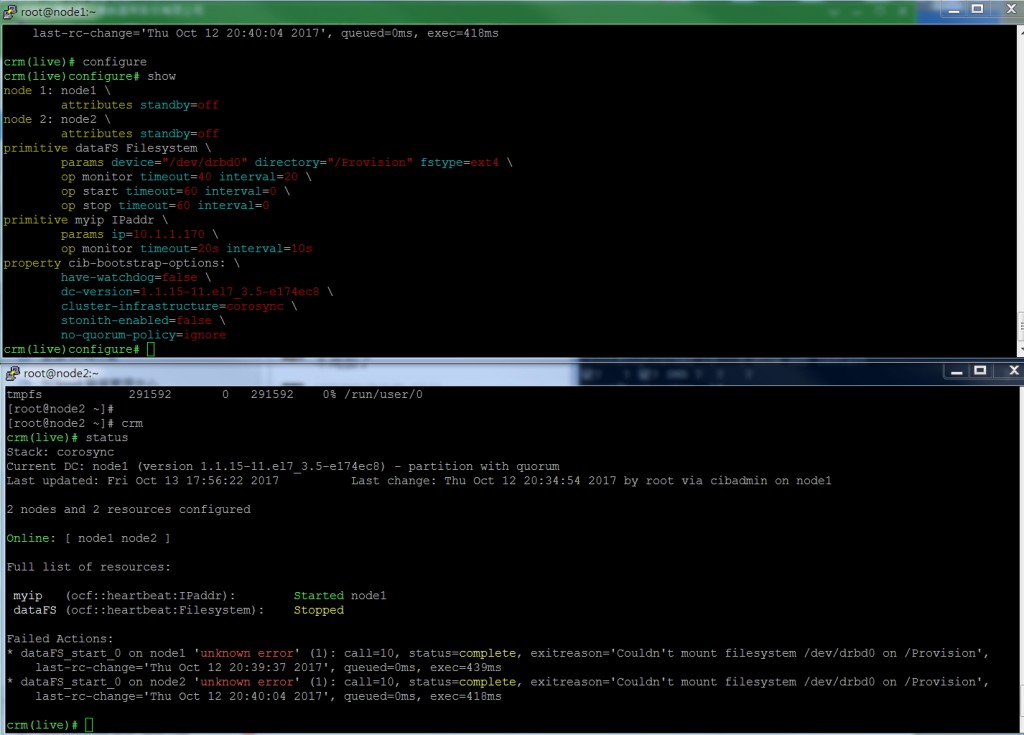
故障情形如下,在crm設定,要DRBD 自動掛上/Provision
會出現錯誤訊息!
Failed Actions:
已邀請的邦友 {{ invite_list.length }}/5
現在是要大家一起觀落陰嗎?.....
你只提供《無法設定成功》這條線索, 對查修有甚麼用處?
如果有人電腦裝作業系統裝不起來, 只告訴你「我安裝到一半失敗」, 其他甚麼都沒說, 你要怎麼查下去?
每次看到這種我都在想,我能觀落陰我就去當seafood啦,有人送勞斯萊斯給我開,幹嘛還要在這幫人debug做功德。哈
每次看到這種我都在想,我能觀落陰我就去當seafood啦,有人送勞斯萊斯給我開,幹嘛還要在這幫人debug做功德。哈
謝謝雷大指點,我都忘記PO錯誤資訊,待整理後再來請教,謝謝
raytracy大神 我已補上錯誤訊息,如果可以再請幫忙看一下,謝謝
你看看這篇, 跟你很接近的錯誤, 但是不知道他的解法是否可以給你用? "mkfs.ext3 /dev/drbd0"
https://www.howtoforge.com/community/threads/drbd-problems.40203/
謝謝raytracy回應,照做後還是一樣情形(mkfs.ext3 /dev/drbd0)
望請高手繼續指點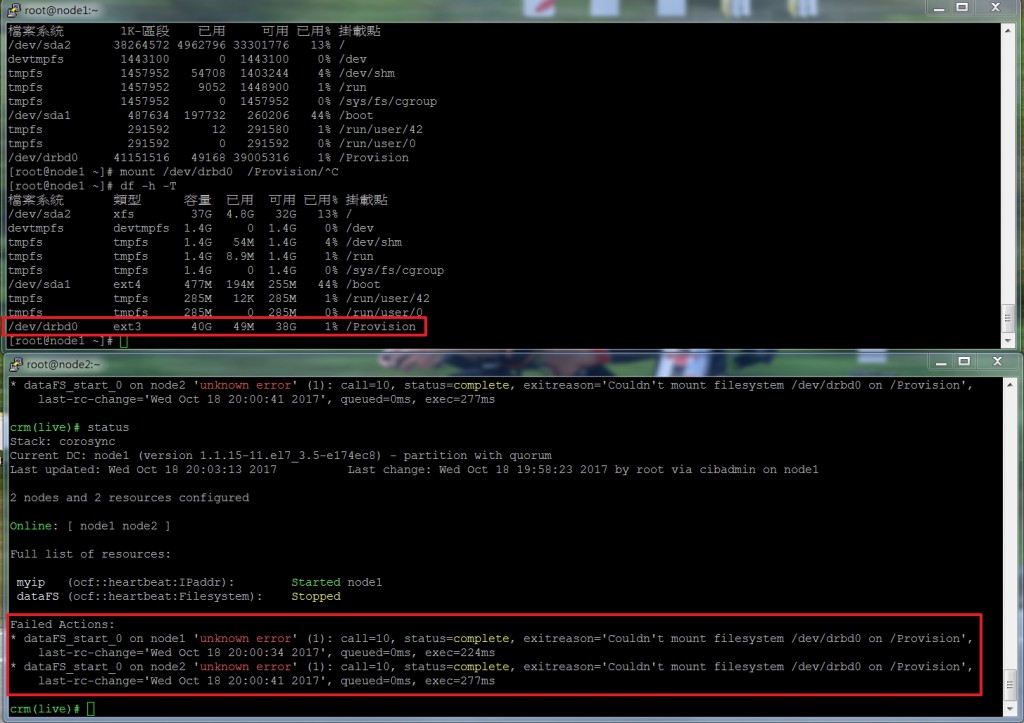
cat /var/log/cluster/corosync.log 如圖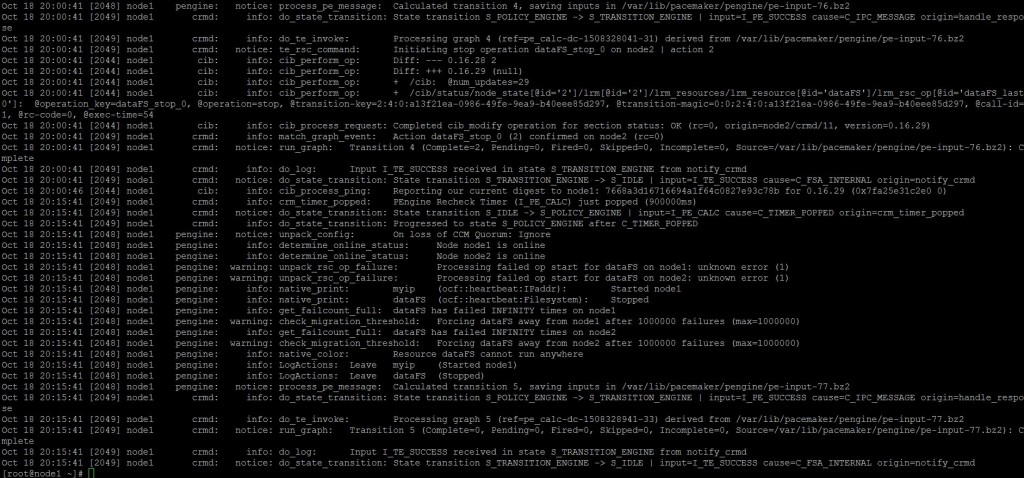
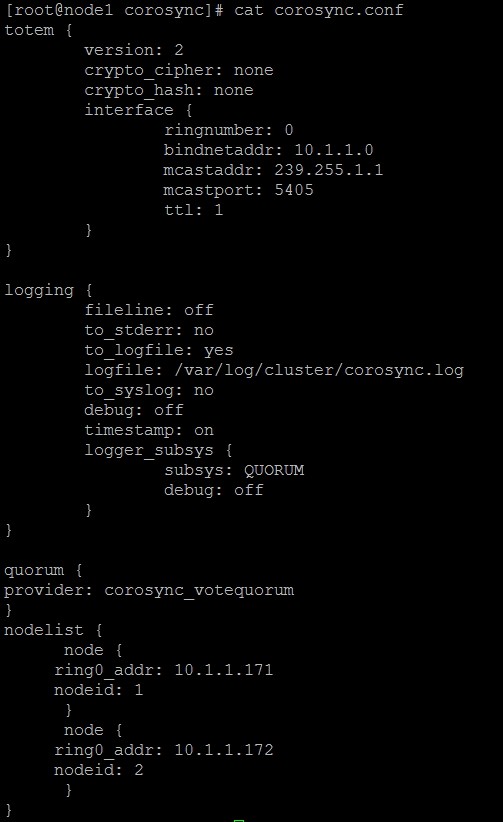
別照抄網路教學, 該篇文章也很舊了, 現在都使用systemd, 更何況寫文件時丟三忘四的不少, 如文中corosync.conf就少了:
quorum {
provider: corosync_votequorum
two_node: 1
}
nodelist {
node {
ring0_addr: 第一台真實IP, 如192.168.1.201
name: primary
nodeid: 1
}
node {
ring0_addr: 第二台真實IP, 如192.168.1.202
name: secondary
nodeid: 2
}
}
, 正常corosync需要三台, 其中two_node=1表示只用兩台組corosync. 請參考:
http://clusterlabs.org/doc/en-US/Pacemaker/1.1/html/Pacemaker_Explained/_enabling_pacemaker.html
我用heartbeat+DRBD做兩台Zimbra的HA, 正常運作, 也發生過幾次切換, 客戶未曾抱怨過掉信或不能寄信, DRBD真的太強了.
說到DRBD, 該篇文章並未處理腦裂(split-brain)的問題, 這是實際生產環境中必須處理的. 文中HA的部份只有MySQL的Data部份, MySQL主程式並未加入DRBD HA, 那MySQL更新時將造成版本不一致, 記得兩邊更新步驟要一致.
