各位大大好
小弟為python初學者,近日在練習使用bs4抓取人力銀行的工作列表內容,
小弟想抓起標籤 li 且 class為JobsCss 的內容時,jupyter都是回傳none,
小弟一直想不出是哪裡出錯,因此想於此版上尋求各位大大的指點。
人力銀行網頁網址:
https://www.1111.com.tw/job-bank/job-index.asp?tt=1&ks=PYTHON&wc=101800&fs=1&si=1&ts=1
以下附上小弟的程式碼與網頁截圖: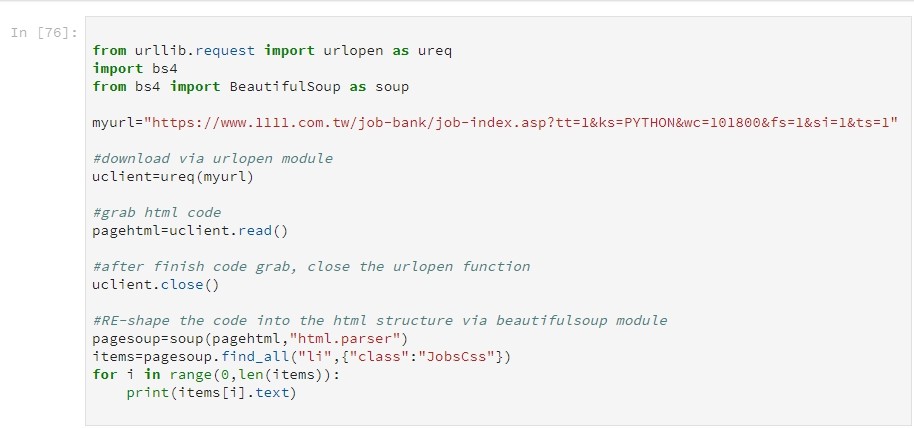
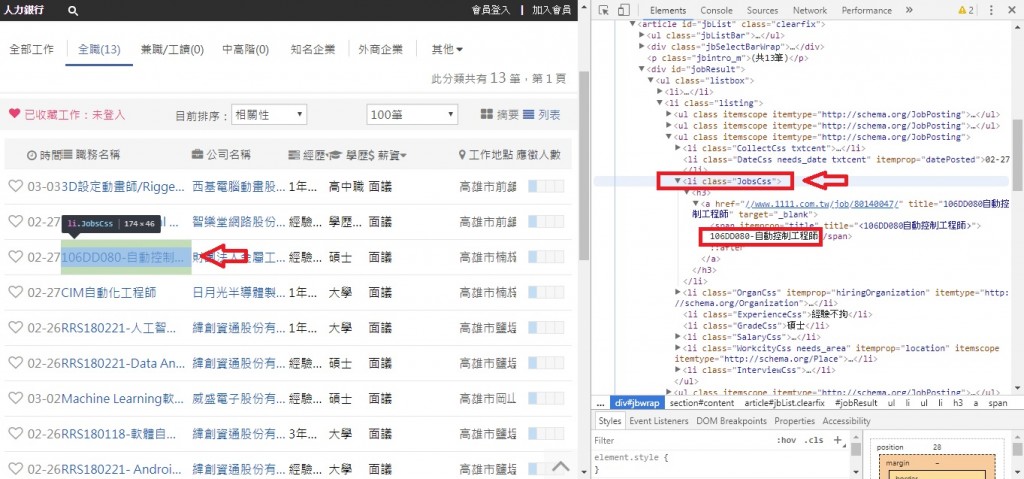
網頁截圖:
已邀請的邦友 {{ invite_list.length }}/5
回答:
初步調查發現:
問題點在
瀏覽器去瀏覽會有 jobscss 的class
但是用程式去抓只有 jbInfoin的class
應該出在1111 server那邊有特別判斷甚麼
解決方法:
我這邊使用
先抓 class = jobscss 的 div -> 抓底下h3 dom -> 抓底下a dom
取得title屬性跟href屬性就可以
問題:
是用啥程式抓網頁碼的嗎?
回答:
我是用C#寫的
想了解可以看我寫的文章 【C#】爬蟲抓IT邦問題 #1 : 爬網頁並篩選資料 - iT 邦幫忙::一起幫忙解決難題,拯救 IT 人的一天
問題:
不過小弟不解為何會發生使用瀏覽器看到的原始碼標籤Class會出現不童的狀況??
回答:
應該是1111的server有做特別判斷
舉例:
我在server那邊,可以用程式碼抓
Request裡面的header,User-Agent的內容為網頁瀏覽器chrome or IE or Null
做個別的網頁渲染處理
感謝暐翰大大的指引,確實將div標籤的class改為jbInfoin後就可以抓取到資訊了。
小弟可以請教一下暐翰大大是用啥程式抓網頁碼的嗎?
不過小弟不解為何會發生使用瀏覽器看到的原始碼標籤Class會出現不童的狀況??
maven
我在上面文章,回復你新的問題 :)
假如有幫到你,麻煩評個最佳答案
想升級等級,要不然一天只能回答兩個問題 :(
好的感謝您



