先上code
import scrapy
from bs4 import BeautifulSoup
from apple.items import AppleItem
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class AppleCrawler(CrawlSpider):
name = 'apple'
start_urls = ['https://www.abc.com.tw/apple-page-1.html?a=1&i=1,&j=80&k=1&max=999999']
rules = [
Rule(LinkExtractor(allow=('...(求助點)...')), callback='parse_link', follow=True)
]
def parse_link(self, response):
res = BeautifulSoup(response.body)
for news in res.select('.title'):
yield scrapy.Request(news.select('a')[0]['href'], self.parse_detail)
def parse_detail(self,response):
res = BeautifulSoup(response.body)
......
return appleitem
問題就在翻頁功能卡住
https://www.abc.com.tw/apple-page-1.html?a=1&i=1,&j=80&k=1&max=999999
https://www.abc.com.tw/apple-page-2.html?a=1&i=1,&j=80&k=1&max=999999
https://www.abc.com.tw/apple-page-3.html?a=1&i=1,&j=80&k=1&max=999999
魯妹我試了好幾次regexp寫法一直失敗QQ
/apple-page-[1-3]$\.html\\*
/apple-page-[1-3]$\.html\?\*
問號後面的參數value可能有 ","
另外
function若命名為parse
在LinkExtractor裡的callback呼叫會有衝突問題
但我只要把第一個def之後的function改叫parse以外的名字 (code裡是parse_link)
整個爬蟲都不能work了...
想請問這部分究竟要怎麼去修改...
謝謝各位對新手的包容
已邀請的邦友 {{ invite_list.length }}/5
推薦一個測試 regex 的網站,可以很即時的驗證正規式是否正確
https://regex101.com
然後正規式的部分,如果您的網址是存在於 <a href="xxx">,
那正規式可以這樣下
'https:\/\/xxx\/xxxxx-page-[1-3]+\.html\?[^"]*'
程式的部分我自己做了一次,有遇到下面兩個問題
然後您可以貼一下您的錯誤訊息
最後附上程式給大大參考:
crawler.py
class AppleCrawler(CrawlSpider):
start_urls = ['https://ithelp.ithome.com.tw/users/20106865/articles']
rules = [
Rule(LinkExtractor(allow=('https:\/\/ithelp.ithome.com.tw\/users\/20106865\/articles\?page=[3-4]+?')), callback='parse_link', follow=False)
]
name = 'apple'
def parse_link(self, response):
res = BeautifulSoup(response.body)
for title in res.select('.qa-list__title'):
print (title.select('a')[0]['href'].strip())
yield scrapy.Request(title.select('a')[0]['href'].strip(), self.parse_detail)
def parse_detail(self, response):
res = BeautifulSoup(response.body)
appleitem = AppleItem()
appleitem['title'] = res.select('.qa-header__title')[0].text.strip()
return appleitem
pipelines.py
import json
class ApplePipeline(object):
def open_spider(self, spider):
self.file = open('a.txt', 'w', encoding='utf8')
def close_spider(self, spider):
self.file.close()
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
print(line)
self.file.write(line)
return item
items.py
class AppleItem(scrapy.Item):
title = scrapy.Field()
爬到的結果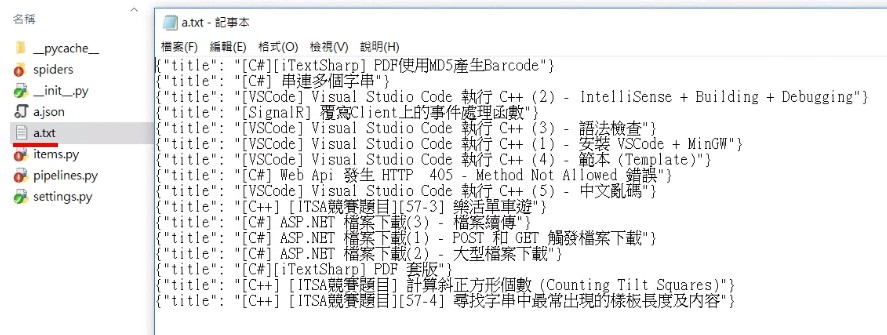
!!! 謝謝這位大大的回答!!
這裡再貼上錯誤訊息,但其實我沒看到錯誤訊息
純粹就是 def parse 可以 改成 def parse_link 就不行
因此無法google (淚)
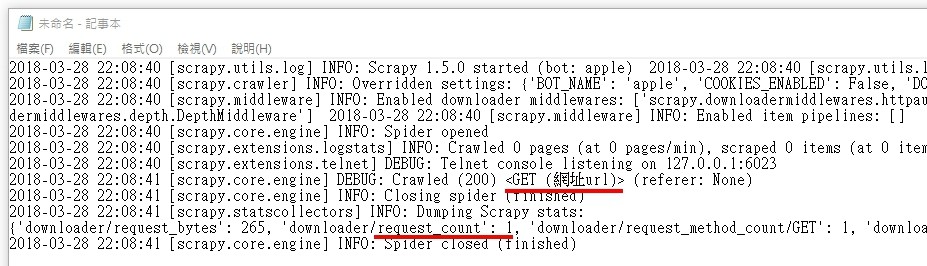
2018-03-28 22:08:40 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: apple) 2018-03-28 22:08:40 [scrapy.utils.log] INFO: Versions: lxml 4.1.1.0, libxml2 2.9.7, cssselect 1.0.3, parsel 1.4.0, w3lib 1.19.0, Twisted 17.9.0, Python 3.6.4 |Anaconda, Inc.| (default, Jan 16 2018, 10:22:32) [MSC v.1900 64 bit (AMD64)], pyOpenSSL 17.5.0 (OpenSSL 1.0.2n 7 Dec 2017), cryptography 2.1.4, Platform Windows-10-10.0.16299-SP0
2018-03-28 22:08:40 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'apple', 'COOKIES_ENABLED': False, 'DOWNLOAD_DELAY': 2, 'NEWSPIDER_MODULE': 'apple.spiders', 'SPIDER_MODULES': ['apple.spiders']} 2018-03-28 22:08:40 [scrapy.middleware] INFO: Enabled extensions: ['scrapy.extensions.corestats.CoreStats', 'scrapy.extensions.telnet.TelnetConsole', 'scrapy.extensions.logstats.LogStats']
2018-03-28 22:08:40 [scrapy.middleware] INFO: Enabled downloader middlewares: ['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware', 'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware', 'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware', 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware', 'scrapy.downloadermiddlewares.retry.RetryMiddleware', 'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware', 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware', 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware', 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware', 'scrapy.downloadermiddlewares.stats.DownloaderStats'] 2018-03-28 22:08:40 [scrapy.middleware] INFO: Enabled spider middlewares: ['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware', 'scrapy.spidermiddlewares.offsite.OffsiteMiddleware', 'scrapy.spidermiddlewares.referer.RefererMiddleware', 'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware', 'scrapy.spidermiddlewares.depth.DepthMiddleware'] 2018-03-28 22:08:40 [scrapy.middleware] INFO: Enabled item pipelines: []
2018-03-28 22:08:40 [scrapy.core.engine] INFO: Spider opened 2018-03-28 22:08:40 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min) 2018-03-28 22:08:40 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-03-28 22:08:41 [scrapy.core.engine] DEBUG: Crawled (200) <GET (網址url)> (referer: None) 2018-03-28 22:08:41 [scrapy.core.engine] INFO: Closing spider (finished) 2018-03-28 22:08:41 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 265, 'downloader/request_count': 1, 'downloader/request_method_count/GET': 1, 'downloader/response_bytes': 21641, 'downloader/response_count': 1, 'downloader/response_status_count/200': 1, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2018, 3, 28, 14, 8, 41, 548750), 'log_count/DEBUG': 2, 'log_count/INFO': 7, 'response_received_count': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2018, 3, 28, 14, 8, 40, 883800)} 2018-03-28 22:08:41 [scrapy.core.engine] INFO: Spider closed (finished)