各位大大好,因為最近在學Python用來爬蟲,使用的套件是requests,目前學著用requests去取網頁中get及post的資料,但是目前在爬蝦皮的商品頁面資料遇到問題,想說是不是有搞錯或沒注意到的地方,麻煩各位大大解答。
想爬的頁面是在賣家的主頁去爬該賣場所有的商品資料,包含庫存、價格等,舉例如下頁面(把賣場名字遮起來是怕侵權或感覺像是打廣告,然後紅色框起來的部分就是我想爬的資料):
https://shopee.tw/shop/3625341/search/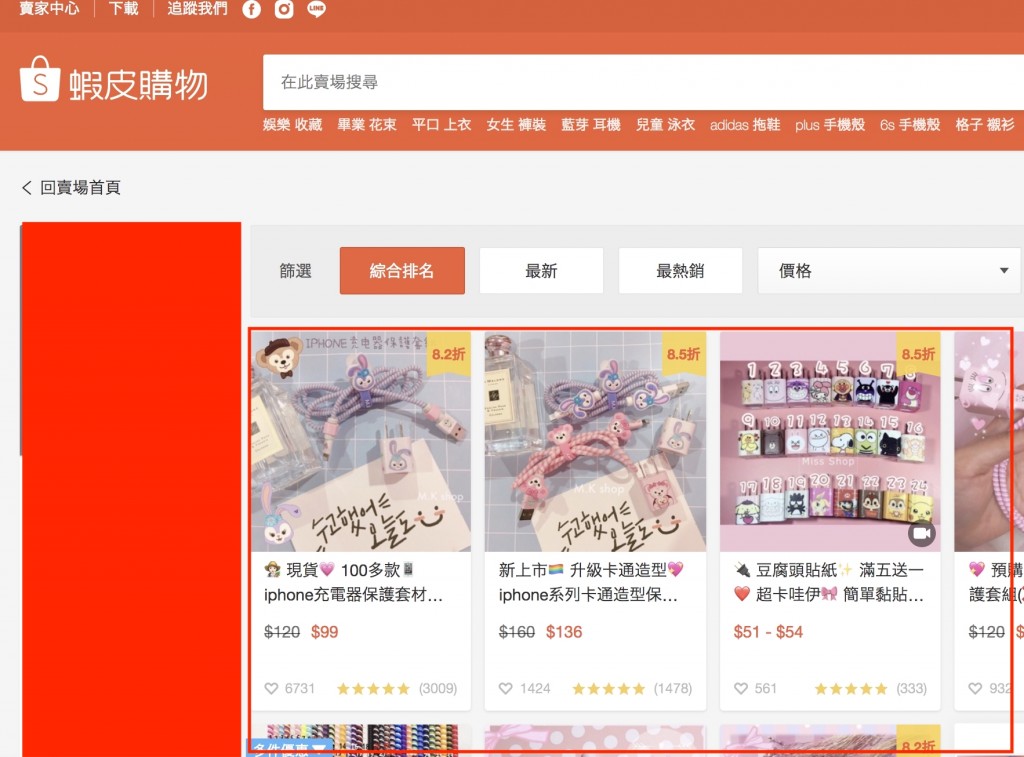
我目前的做法是,從開發人員工具裡觀察他的request,於是看到了一個get中有回傳產品的所有資料,以下圖片畫紅線的地方是產品名稱及庫存數量: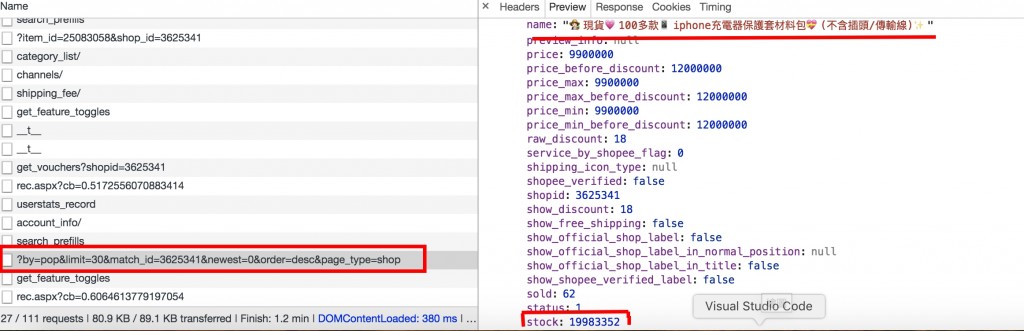
透過Headers去觀察它是使用get去請求這個資料: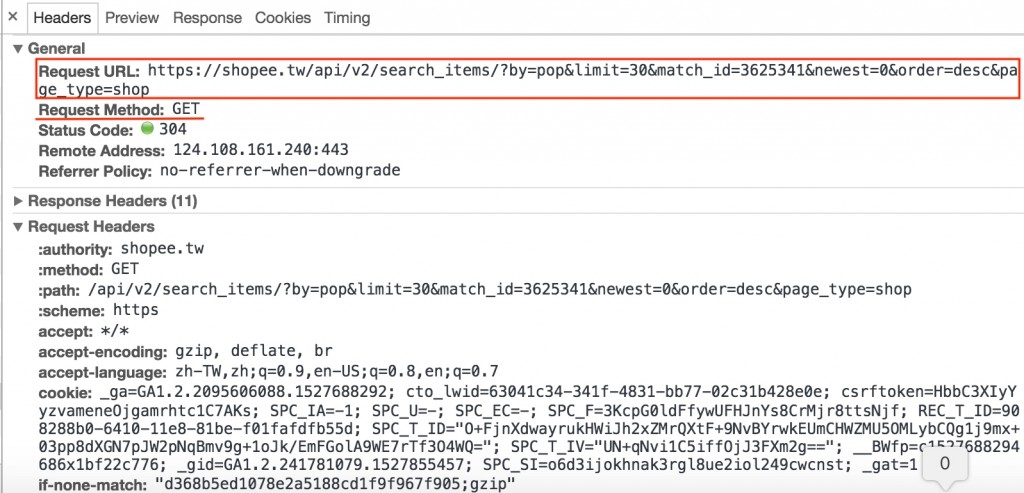
但是在我使用Python的requests的get去請求的時候,跑出來的不是在Preview中的JSON資料,而是目前頁面的HTML,當然在那個HTML中也沒有產品的資料 ,程式碼以下附上:
,程式碼以下附上:
import requests
res = requests.get("https://shopee.tw/api/v2/search_items/?by=pop&limit=30&match_id=3625341&newest=0&order=desc&page_type=shop")
print(res.text)
結果用圖片奉上:
其實結果的圖片也看不出什麼,但是就是一些JavaScript和少許HTML,請問版上大大有方法能夠告訴我是漏了什麼,也可以稍微給個方向讓我嘗試!麻煩大家了!
PS.如果文中有令人惹議的圖片請留言告訴我,我會再把圖片拿掉!謝謝!
已邀請的邦友 {{ invite_list.length }}/5
1.requests送出的UA(python-requests/2.18.4),蝦皮擋掉了,會導向蝦皮的新手教學頁面。
2.解法也很簡單,就把UA改掉就行。
import requests
headers = {'user-agent': 'Mozilla/5.0 (Macintosh Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'}
res = requests.get("https://shopee.tw/api/v2/search_items/?by=pop&limit=30&match_id=3625341&newest=0&order=desc&page_type=shop", headers=headers)
print(res.request.headers) # 看requests送出的header
print(res.text)
就user-agent啊,瀏覽器在送出request的時候會送出header告訴server一些資訊,包含瀏覽器是什麼,UA就是瀏覽器的識別字串。
通常不用登入、用get傳參數,還會發生問題的,就送假UA去試試看。
除了IE,現在主流瀏覽器的開發者模式都能很簡單的看到header,爬不到就是看header和偷用cookies。
好的!謝謝大大補充說明
如果之後有問題再發問,還要麻煩你了
請問大神 我用這個連結下載https://shopee.tw/api/v2/search_items/?by=relevancy&limit=20&match_id=15226905&newest=0&order=desc&page_type=shop'
但是發現下載下來的資料某些欄位會被截斷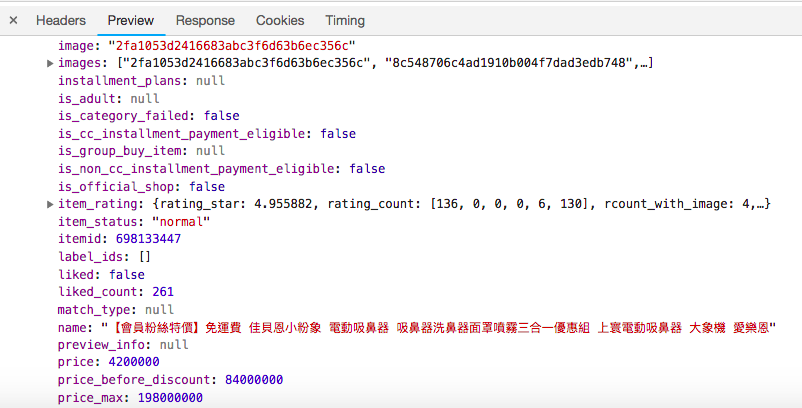
比如我用瀏覽器看到的是 "image": "2fa1053d2416683abc3f6d63b6ec356c"
但是requests下來的 "2fa1053d2416683abc3f6d63b6e" 少了c356c
瀏覽器看到的 "name: "【會員粉絲特價】免運費 佳貝恩小粉象 電動吸鼻器 吸鼻器洗鼻器面罩噴霧三合一優惠組 上寰電動吸鼻器 大象機 愛樂恩"
requests下來的下來的是【會員粉絲特價】免運費 佳貝恩小粉象 電動吸鼻器 吸鼻器洗鼻器面罩噴霧三合一優惠組 上寰電動吸鼻器 大象" 少了 "機 愛樂恩"
還有價錢相關的也都requests不下來 請問我可以怎麼做呢?
我是python爬蟲初學者,這個線上教學我看了之後很有幫助,應該可以解決你的問題!
https://www.udemy.com/course/python-crawler/?referralCode=A4F2B9D20A2C35D5001D

