尋找字串 找到最長重複的字串,我有使用suffix_trees 跟網路上的一些code
'hellowdfbvsfbsdbsdhellowscssdthavcscsdrssbhellowmf'
答案是hellow
但並不是我要的答案請問有比較適合的方法例如from suffix_trees import STrees 的Python也適用的演算法嗎?
可以指點我一下嗎 拜託了!!
已邀請的邦友 {{ invite_list.length }}/5
蠻有趣的,研究了好一陣子,寫了一個擴充方法,給您看看是不是您需要的。
首先 Google 了 suffix-trees,發現這是個後綴樹演算法的實作,
後綴樹!!! 沒聽過的新名詞,這勾起了小弟我的興趣,
繼續 Google 找到了這篇文章 后缀树,
且在最後 后缀树的应用 找到了大大的需求。
詳細原理文章內寫得很清楚,有興趣的大大可以點進去看看。
了解原理後就可以進入程式碼的部分,
看完 suffix_trees 的原始碼,發現並沒有查詢 最長重複子字串 的功能,
不過有個類似的方法 lcs(),可以查詢多個字串的最長共用部分,
既然有現成的,那就以此為基礎修改成我們想要的。
我將這個擴充方法獨立一個檔案 suffix_trees_ex.py,主程式需要再 import 就好。
程式碼:
class STreeEx():
def __init__(self, sTree):
# 傳入原套件後綴樹
self.sTree = sTree
def lrs(self):
# 最深非葉節點
deepestNode = self._find_lrs(self.sTree.root)
start = deepestNode.idx
end = deepestNode.idx + deepestNode.depth
return self.sTree.word[start:end]
def _find_lrs(self, node):
nodes = [self._find_lrs(n)
for (n,_) in node.transition_links
# 排除葉節點
if n.transition_links != []]
if nodes == []:
return node
deepestNode = max(nodes, key=lambda n: n.depth)
return deepestNode
主程式:
from suffix_trees import STree
from suffix_trees_ex import STreeEx
st = STree.STree("156752894567528944226695310752654423684")
st = STreeEx(st)
print(st.lrs()) # 56752894
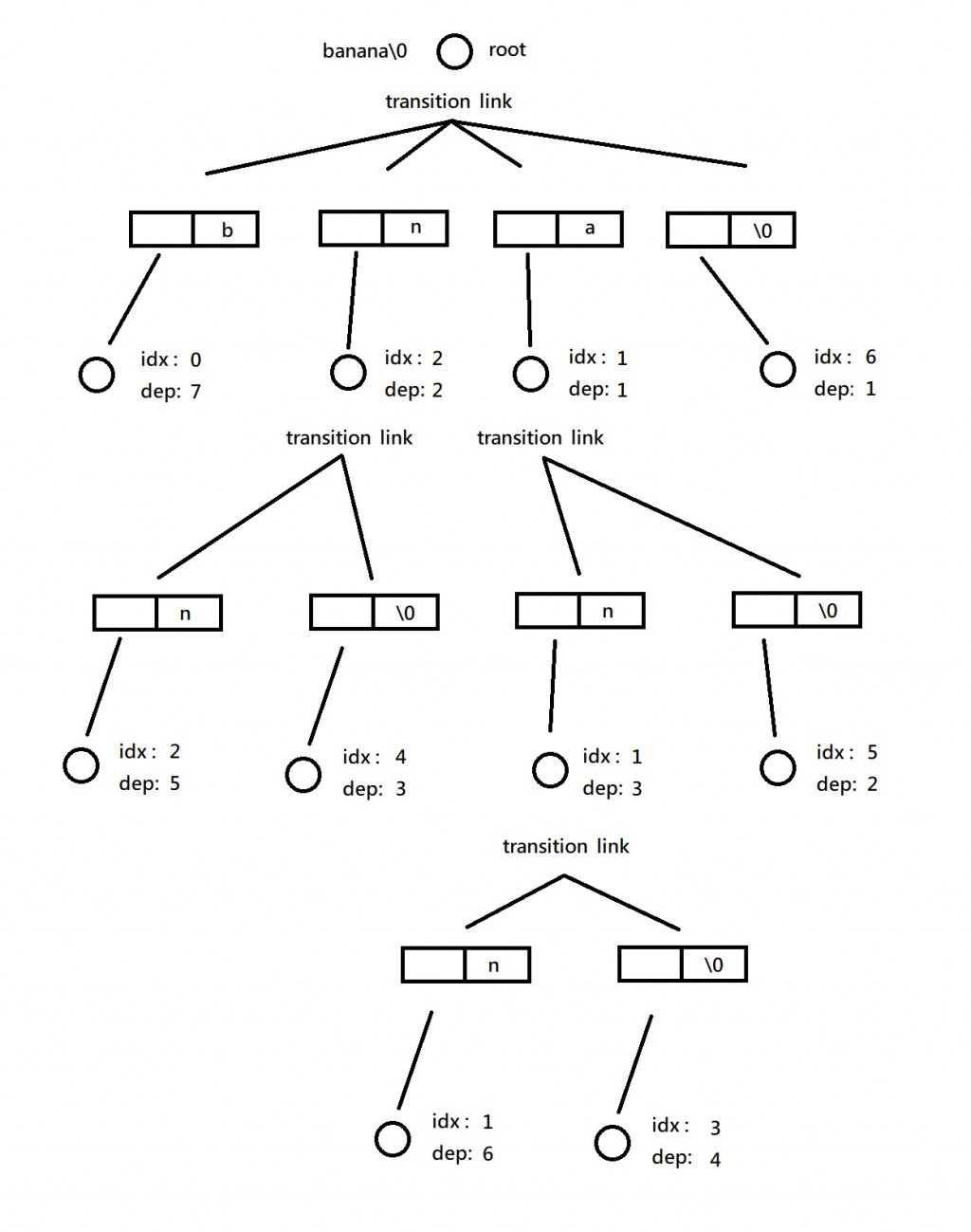
最後附上一張小弟研究 suffix_trees 內部結構時畫的圖,和上面文章的 Compressed Trie 比對會更清楚。


 iThome鐵人賽
iThome鐵人賽