如題,我使用 Excel 2013版本,
目前嘗試的作法是開啟 excel的反覆運算功能,使用函數
=IF(COUNTIF($A$1:$J$1000000,A1)>1,RANDBETWEEN(0,10000000)/10000000,A1) ,填滿工作表欄位 A1:J1000000,共一千萬個儲存格範圍。
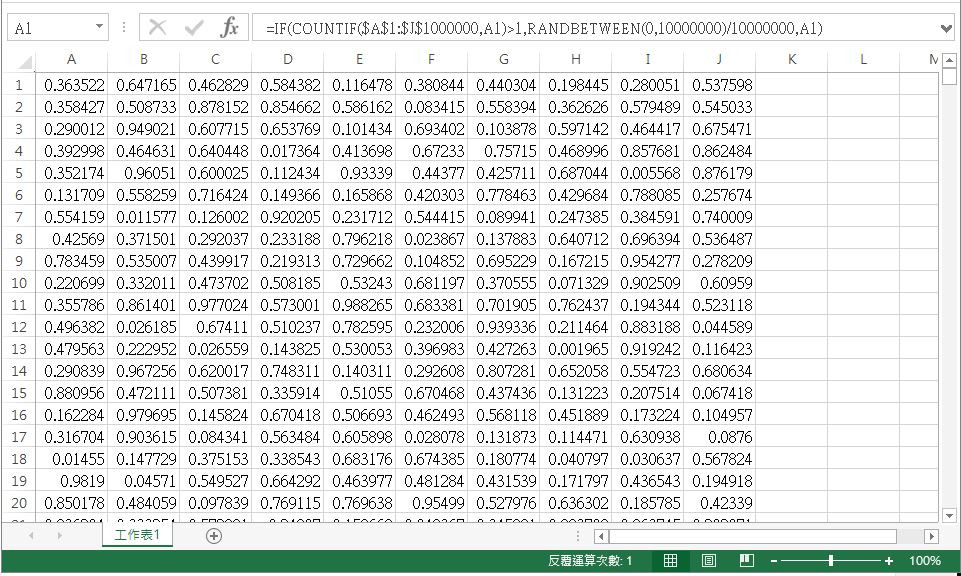
如圖,用前述方式已經跑了超過12小時仍無結果,
想請問各位大神,excel有沒有其它比較有效率的方式,
例如:使用 Excel VBA?可以產生一千萬個介於0~1之間的不重複亂數?
感謝大家的幫忙!祝平安喜樂。
已邀請的邦友 {{ invite_list.length }}/5
有時間限制嗎?
Excel我猜可能沒辦法太快,
先產生1~10,000,000的數字、亂數排序,
然後除以10,000,001
我比較好奇excel不會一直崩潰嗎
小魚 感謝回答。
您提到的作法是不是就像我目前用的方式?=IF(COUNTIF($A$1:$J$1000000,A1)>1,RANDBETWEEN(0,10000000)/10000000,A1)
我是有預期應該不會太快,畢竟運算速度還是得看硬體效能。
但擺著超過12小時實在難耐,所以想問問有沒有方法?或者使用VBA的方式?可以更有效率產生需要的結果。
dragonH Excel是還沒崩潰,但鼠標就是一直轉圈圈超過12小時,轉到都快吐了還沒個結果...
1千萬筆本來就不小,
可以想像時間也要花不少,
不過如果不是用Excel VBA,
你要怎麼處理 不重複的資料 呢?
之前有人問的問題
亂數不重複
基本上是差不多的概念,
只要記憶體不爆掉,
總是跑得完的.
小魚 我不懂 excel vba的 code要如何寫?才能達成這目的。
我現在是開啟 excel的反覆運算功能,用 COUNTIF函數檢查每個儲存格內 RANDBETWEEN函數產生的亂數,在 A1:J1000000範圍內有沒有重複?
再搭配 IF函數,若亂數有重複就重新產生亂數,若無則保留原本的數值。在每個儲存格如此反覆運算最多100次。
我做了一個範例,
不會很難研究看看吧,
Private Sub test()
Dim mybag As New Collection ' 宣告一個放球的袋子,類型是Collection集合
totalRow = 9 '列數
totalNum = 72 '總數
For i = 1 To totalNum
mybag.Add (i / (totalNum + 1)) ' 依序放入1到49的號碼球
Next
For i = 1 To totalNum
R = Int(mybag.count * Rnd()) + 1 ' R 就是包包裡的球數*0~1之間的隨機數,集合跟陣列一樣,元素從1開始
Row = ((i - 1) Mod totalRow) + 1
Column = Int((i - 1) / totalRow) + 1
Cells(Row, Column).Value = mybag.Item(R) ' 按c值在相對的列上填入球號
mybag.Remove (R) ' 抽到的球就不要放回袋子(集合)裡了,直接拿掉
Next
End Sub
這是執行結果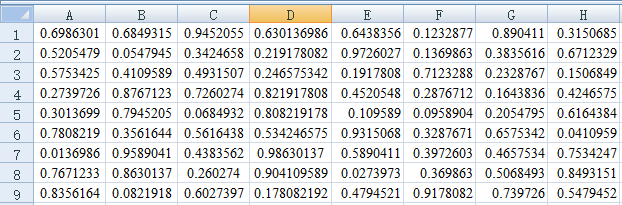
1千萬筆你就自己慢慢跑,
不奉陪了
就是因為檢查所以會花很多時間,
用抽撲克牌的方式就不需要檢查.
小魚好的,那我先關掉那個到現在還沒結果的工作進度了...
我試試看要怎麼改寫這段 vba的內容,感謝。
其實你只要改寫兩個地方,
不過你還是先研究清楚邏輯吧,
另外Excel VBA也可以 下中斷點(F9) 跟 逐步執行(F8) 來Debug.
小魚的方式好聰明啊!學起來
小魚我依照您提供的範例,改寫編碼如後,請問這樣正確嗎?
Private Sub test()
Dim mybag As New Collection ' 宣告一個放球的袋子,類型是Collection集合
totalRow = 1000000 '列數
totalNum = 10000000 '總數
For i = 1 To totalNum
mybag.Add (i / (totalNum + 1)) ' 依序放入(1到10000000的號碼球/號碼+1)
Next
For i = 1 To totalNum
R = Int(mybag.count * Rnd()) + 1 ' R 就是包包裡的球數*0~1之間的隨機數,集合跟陣列一樣,元素從1開始
Row = ((i - 1) Mod totalRow) + 1
Column = Int((i - 1) / totalRow) + 1
Cells(Row, Column).Value = mybag.Item(R) ' 按c值在相對的列上填入球號
mybag.Remove (R) ' 抽到的球就不要放回袋子(集合)裡了,直接拿掉
Next
End Sub
另外,請問您提到的中斷點(F9)和逐步執行(F8),該如何寫入在 Excel vba的編碼內?
看起來應該是吧,
主要是改totalRow和totalNum,
其他就會自己處理了.
中斷點(F9)和逐步執行(F8)不是寫在Code裡面的,
是你在找問題的一些技巧,
你可以上網查查應該會有一些資料,
小魚好的,感謝回答。我正在嘗試用 Excel vab執行前述代碼,省去反覆檢查的功夫應該可以比較快完成,再來看看多久可以跑完...
小魚用抽撲克牌方式好聰明,不稱讚一下也不成。
10,000,000 = 250 x 40,000
A..IP = 250 Column
1..40000 = 40000 Row
A1..IP40000
公式只要寫 =RAND() 就好
海綿寶寶 抱歉,我看不懂您回應的內容,可以請您淺白點具體說明作法嗎?感謝。
你原本的寫法不太可能會不重複吧...
然後這個用excel做也太沒效率了,10000000次連要我用python寫(不用numpy/pandas)我覺得都會花很久。
golang,應該不用10分鐘吧:
package main
import (
. "fmt"
"math/rand"
"os"
"path"
"path/filepath"
"strconv"
"time"
"github.com/360EntSecGroup-Skylar/excelize"
)
func main() {
ex, err := os.Executable()
if err != nil {
panic(err)
}
exPath := filepath.Dir(ex)
book := path.Join(exPath, "Book1.xlsx")
f := excelize.NewFile()
f.SetActiveSheet(1)
columns := [10]string{
"A",
"B",
"C",
"D",
"E",
"F",
"G",
"H",
"I",
"J"}
rand.Seed(time.Now().UnixNano())
p := rand.Perm(10000000)
for i := 1; i <= 1000000; i++ {
_p := p[i*10-10 : i*10]
for index, elm := range columns {
cell := elm + strconv.Itoa(i)
value := float64(_p[index]) / float64(10000000)
Println(cell, value)
f.SetCellValue("Sheet1", cell, value)
}
}
Println(book)
err = f.SaveAs(book)
if err != nil {
Println(err)
}
}
https://drive.google.com/file/d/1iPOh_HqrH3Ysu2NzqE_1fwOhsDScg-wu/view?usp=sharing
我是順便試跨平台編譯,在mac上編的,能不能跑我不知道。
froce感謝回答!
我在 Win7 64bit + Excel 2013 64Bit的系統平台上執行程式,自 CMD視窗開啟到結束,大約需時 18分鐘,之後會產生一個大小為 0KB的 BOOK1.xlsx,且檔案無法由 Excel開啟,錯誤訊息如圖。

更改副檔名為 .xls後可開啟檔案。可惜內容為空白表格,否則這速度真是神快啊...
有更新執行檔了,試試看。
原本的在mac上可以跑,在windows下則會因為路徑關係造成問題。
然後我的office 2013 32bit可以跑。
報告 froce,我使用更新後的執行檔試了 2次,最後停留狀態如圖:
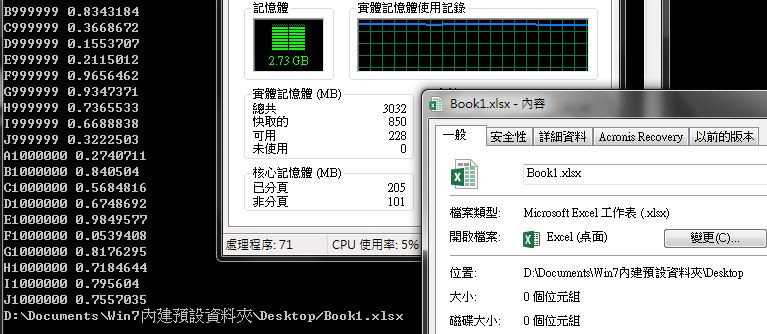
不曉得是不是因為記憶體不足,所以導致問題?
目前用另一台實體記憶體 16GB,使用 Office 2016 64bit的電腦在試;也找一台電腦重新安裝 Office 2013 32bit版本,再試試看。
froce有結果了!
前面的情況應該是硬體效能不足導致。
使用 Win7 64 bit + Office 2016 64 bit的電腦跑出結果如圖:
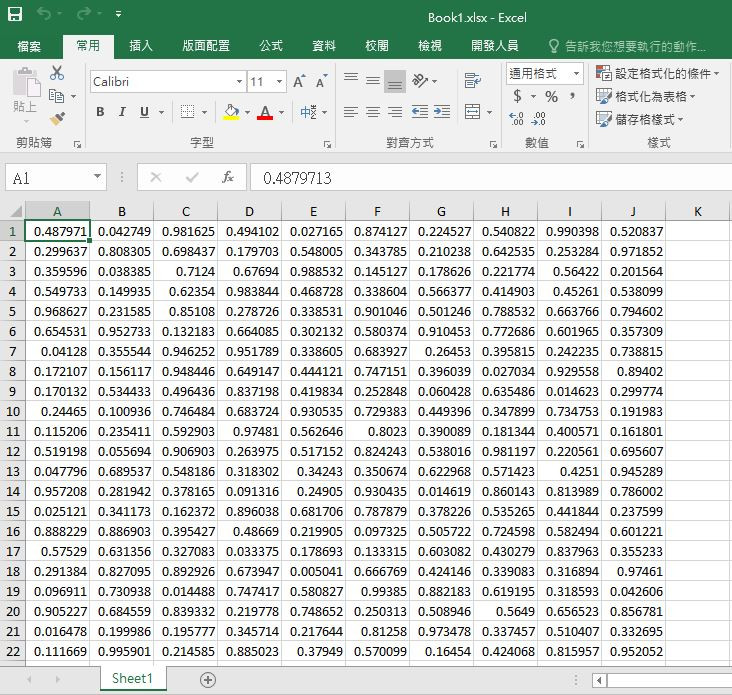
真的是一千萬個亂數啊!
這是目前得到最有效率的做法了!
真是太感謝您了!
我的記憶體都12G以上,不過因為這樣寫會在記憶體裡先建個xslx,然後都寫在記憶體裡,的確蠻吃記憶體的,在我的機器(win7 x64)吃到4.7G,難怪原本編32 bit的會有問題。
真的不行的話就找時間幫你改寫CSV版的好了。
froce 若您空檔時間有餘裕,也願意幫忙,改寫成 CSV版能減輕執行運算的硬體需求,當然再好不過了,感謝勞力!
package main
import (
"encoding/csv"
. "fmt"
"math/rand"
"os"
"path"
"path/filepath"
"strconv"
"time"
)
func main() {
start := time.Now().UnixNano()
ex, err1 := os.Executable()
if err1 != nil {
panic(err1)
}
exPath := filepath.Dir(ex)
sheet := path.Join(exPath, "Book1.csv")
csvFile, err2 := os.Create(sheet)
if err2 != nil {
panic(err2)
}
defer csvFile.Close()
csvWriter := csv.NewWriter(csvFile)
rand.Seed(time.Now().UnixNano())
p := rand.Perm(10000000)
rp := [][]string{}
for i := 0; i < 1000000; i++ {
_p := make([]string, 10, 10)
for index, elm := range p[i*10 : (i+1)*10] {
value := strconv.FormatFloat(float64(elm)/float64(10000000), 'f', -1, 64)
_p[index] = value
}
rp = append(rp, _p)
}
err3 := csvWriter.WriteAll(rp)
if err3 != nil {
panic(err3)
} else {
csvWriter.Flush()
}
end := time.Now().UnixNano()
Println("花費時間:", float64(end-start)/float64(1000000000), "秒")
}
https://drive.google.com/file/d/1as9vj6j3d-T4qL4B__CoP5WzVmgof6Og/view?usp=sharing
CSV版記憶體佔用不到1G...
python:
import csv
import random as rn
import time
start = time.time()
_ = [str(i/10000000) for i in range(10000000)]
rn.shuffle(_)
with open("./test.csv", "w", encoding="utf8") as csvfile:
writer = csv.writer(csvfile)
for i in range(1000000):
writer.writerow(_[i*10:(i+1)*10])
end = time.time()
print("花費時間:", end-start, "秒")
我錯怪python了...還蠻快的。Orz
不輸出中間結果(print)大概18秒,golang 4秒。
記憶體倒是都吃差不多,700MB左右。
froce 我滿懷感激地收下 randomToCSV.exe檔案,感謝大力相助!
你是運氣好剛好遇到我最近想好好的來學GO,要不然我也懶得寫。XD
然後寫了python版才覺得python真的很好用,除了慢和沒有編譯後執行檔以外,寫code的限制少很多,開發更是快到不行。python版的我開始寫不到10分鐘就寫完了。
GO得一直轉型,限制也多,重點是沒有map、filter這類的語意式函式,讓歷遍只能寫迴圈去做。
不過GO的好處就是跨平台編譯簡單、不用顧lib的相依性、執行速度快、還有還沒學到的非同步編程。
我用 C# 跑,用EPPLUS產生EXCEL檔
1、不考慮亂數重覆的前題,以下程式產生不到2分鐘
(i5-3470處理器、8GB DDR3,SSD、Windows10)
using OfficeOpenXml; //EPPLUS
using System;
using System.Diagnostics;
using System.IO;
namespace bigRandom
{
class Program
{
static void Main(string[] args)
{
if (File.Exists("export.xlsx")) File.Delete("export.xlsx");
ExcelPackage excel = new ExcelPackage(new System.IO.FileInfo("export.xlsx"));
ExcelWorksheet ews = excel.Workbook.Worksheets.Add("輸出結果");
int QRow = 1;
int QCol = 1;
int xx = 1;
for(int i = 0;i<10000000;i++)
{
Random Rng = new Random(Guid.NewGuid().GetHashCode());
int x = Rng.Next(0, 1000000000); //產生亂數
ews.Cells[QRow, QCol].Value = (double)x / 1000000000;
QCol++; //從A跑到J
if (QCol > 10) //如果下一行超過 J
{
QCol = 1;//回到A
QRow++; //換行
}
}
excel.Save();
if (File.Exists("export.xlsx")) Process.Start("export.xlsx");
}
}
}
2、考慮不可重覆.................
我用LINUX + PYTHON + LIST及C# + LIST作抽球實驗,效能真的都很差,每跑10000組隨機抽球就需時1分鐘以上,跑完1000萬組,一天一定跑不掉
如果有興趣實驗效能的話,還是留下程式給各位玩玩,多了一個LIST,此例效能實在不好,執行完需時3+小時
using OfficeOpenXml;
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.IO;
namespace bigRandom
{
class Program
{
static void Main(string[] args)
{
if (File.Exists("export.xlsx")) File.Delete("export.xlsx");
ExcelPackage excel = new ExcelPackage(new System.IO.FileInfo("export.xlsx"));
ExcelWorksheet ews = excel.Workbook.Worksheets.Add("輸出結果");
List<int> ballbag = new List<int>();// 球袋
for (int b = 1; b < 10000000; b++)
ballbag.Add(b); //產生1000萬個號碼球並放入球袋裡
int QRow = 1;
int QCol = 1;
while (ballbag.Count > 0) // 一直跑到球袋抽空為止
{
Random Rng = new Random(Guid.NewGuid().GetHashCode());
int x = Rng.Next(0,ballbag.Count); //從袋中取出號碼球
ews.Cells[QRow, QCol].Value = (double)ballbag[x] / 100000000; // 抽出的球所代表的數值除以1000萬01
ballbag.RemoveAt(x);
QCol++; //從A跑到J
if (QCol > 10) //如果下一行超過J,則換行
{
QCol = 1; //
QRow++;
}
}
excel.Save();
if (File.Exists("export.xlsx")) Process.Start("export.xlsx");
}
}
}
python慢是一定的,只是沒想到C#也要弄到3小時...
不過python用了numpy和pandas的話大概不一定會很久,因為底層是C。
都是慢在LIST的REMOVE操作上......
C#沒有直接對list做shuffle的函式嗎?
有耶,但不知道效能是不是一樣糟而已
private static Random rng = new Random();
public static void Shuffle<T>(this IList<T> list)
{
int n = list.Count;
while (n > 1) {
n--;
int k = rng.Next(n + 1);
T value = list[k];
list[k] = list[n];
list[n] = value;
}
}
//用法:
List<Product> products = GetProducts();
products.Shuffle();
我自已用php來寫。因為有卡到記憶體用量問題。(說真的,一千萬筆就算只有一個字元,也需要暫用到10m的用量。但字元數一組最多也需要約8個字元。少說要用到100mb的用量左右。
1.所以我用如下的先各自生成100萬筆的數據10組。每組的數值範圍不同。
如第一組是1~100萬。第二組是100萬零1起~200萬。每組產生的值先各自存到不同的文件上。共10個文件。
2.再產生資料前會先亂數處理後再儲存。
其實我的想法跟分層抽樣的做法也是一樣的。如果不是因為「Allowed memory size」的問題
其實是能直接用如下的方式就可以處理了
for ($i = 1; $i <= 10000000; $i++) {
$a[] = $i;
}
shuffle($a);
運行不需要1秒。我有試著做寫檔約在10秒有右。
不過這樣做很消耗記憶體。我是將變數容量一直開到2G才可以跑的。
我後續試著寫成CSV的資料。是可以在10秒內完成寫檔。
我後續有試著改成不調整記憶容量的做法。用50萬一組做一個分層寫入20個檔案。
感覺反而變快了。運行時間約5秒就可以完成。
只是在試著各自20個文件讀取後再插入CSV檔。又會報「Allowed memory size」的錯誤。
所以作罷

 iThome鐵人賽
iThome鐵人賽