小弟Python新手,請各位先進指導。
感謝!!
問題:
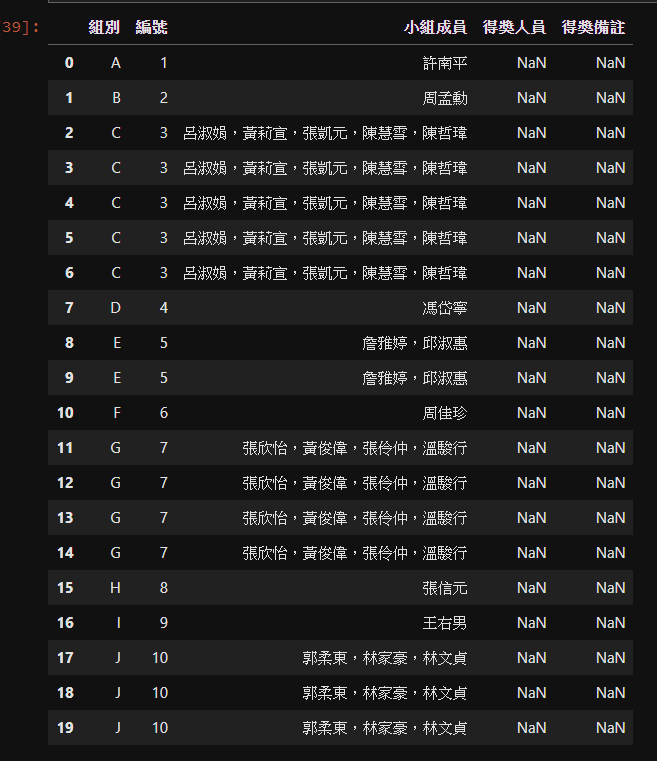
得獎專題共10組,每組可能1-5人。原始資料的示意如下: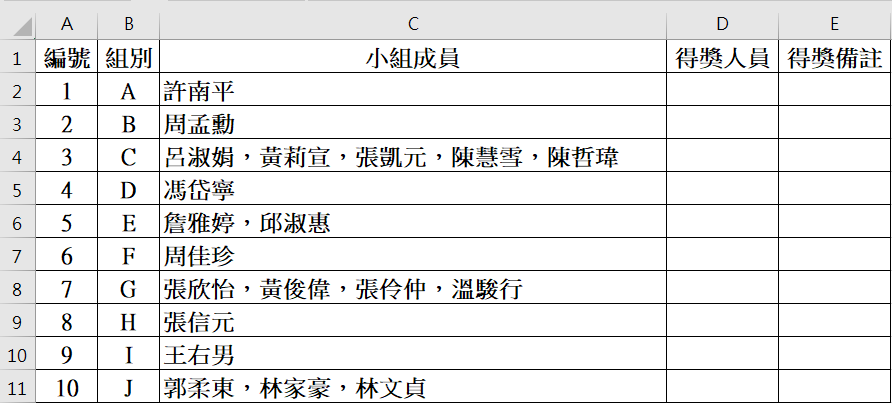
預期的解決方式:
將小組成員切割成個別的得獎人,並在備註中註明與其他人合作。
如小組成員只有1人,則備註為空白。預期程式處理結果如下: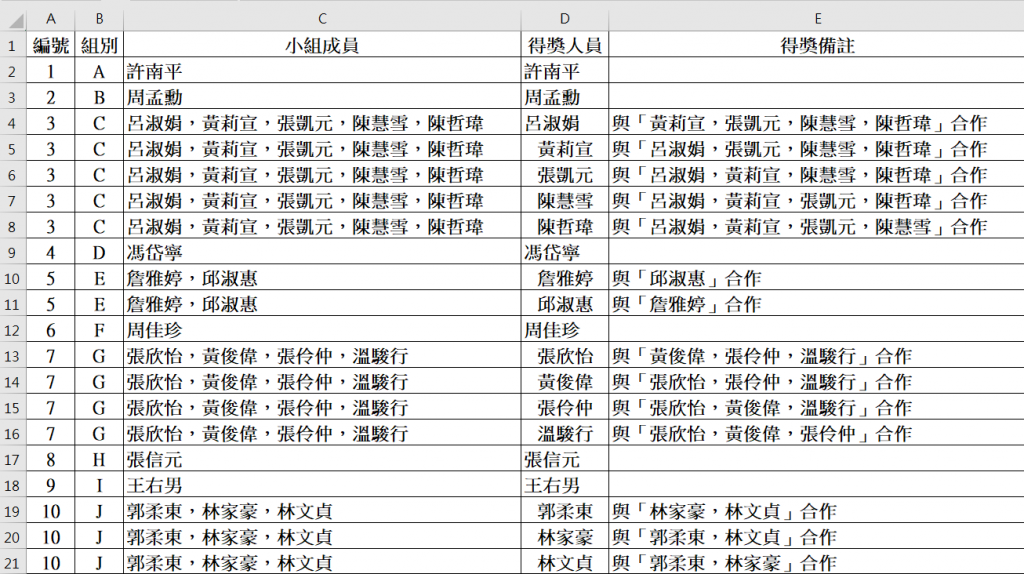
抱歉,新手剛來,不了解守則。
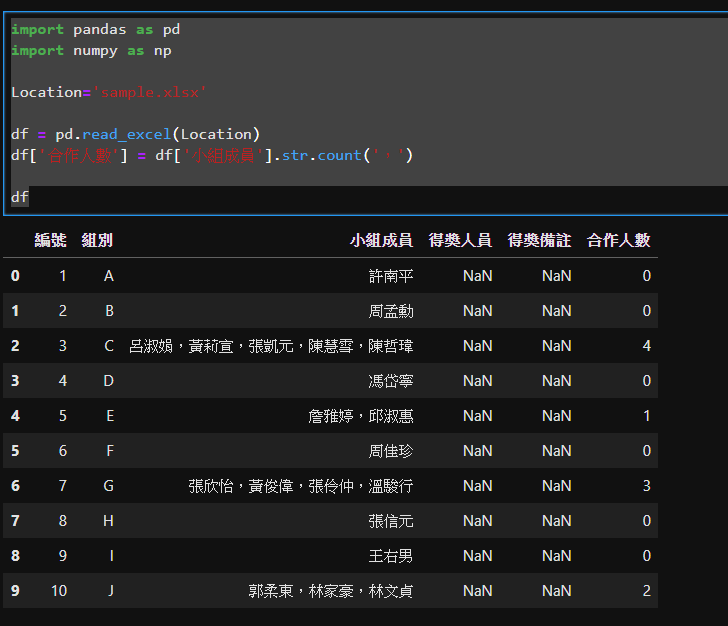
自己寫了一段代碼,想法是先計算「,」的次數算出合作人數。
如果合作人數不是0,就複製那一列的合作人數的次數,
複製完了後,再切割小組成員,搬到得獎人員處。
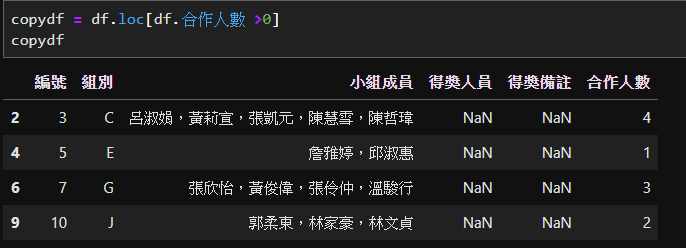
目前就已經卡在如何依照合作人數複製列了。
import pandas as pd
import numpy as np
Location='sample.xlsx'
df = pd.read_excel(Location)
df['合作人數'] = df['小組成員'].str.count(',')
df
lens = df.小組成員.str.split(',').str.len()
df.set_index('組別').reindex(df.組別.repeat(lens)).reset_index()
感謝ccutmis前輩無私的解答!!
我把問題放在國外的網站,得到我無法想像的code。
真是令人汗顏。
已邀請的邦友 {{ invite_list.length }}/5
import pandas as pd
import numpy as np
def memberWithoutMe(member,me):
tmpStr = '與「'
count = 0
for i in member:
if i != me:
if count>0:
tmpStr = tmpStr + ","
tmpStr = tmpStr + i
count=count+1
tmpStr = tmpStr + '」合作'
return tmpStr
Location='sample.xlsx'
df = pd.read_excel(Location)
new_sample0=df[~df['小組成員'].str.contains(",")]
#小組成員只有一人的先撈出來並處理nan及得獎人員欄位
new_sample0=new_sample0.replace(np.nan, '', regex=True)
new_sample0['得獎人員']=new_sample0['小組成員']
df_hasMembers = df[df['小組成員'].str.count(',')>0]
#小組成員不只一人的撈出來跑廻圈處理,以下是廻圈範例:
tmp=[]
for index, row in df_hasMembers.iterrows():
tmpSN=row['編號']
tmpGrp=row['組別']
tmpMember=str(row['小組成員']).split(",")
for i in tmpMember:
tmp.append({
'編號':tmpSN, '組別':tmpGrp,
'小組成員':row['小組成員'],
'得獎人員':i,
'得獎備註':memberWithoutMe(tmpMember,i)
})
result=new_sample0.append(pd.DataFrame(tmp))
print(result.sort_values(by=['組別','編號']))
我略懂python,對於pandas的了解都是google來的,所以我想肯定是有直接用pandas能處理字串分割重組填充列這些函式,不過因為這部份我了解不夠,就先用自己熟悉的土砲作法:取得每列的值作處理並存入暫存的list,全部處理完後把list轉成pd,總之是完成了。
