被供出來出題,一時之間我也想不到啥好的題目。就來個低中高階等級的題目好了。
首先,先將資料表給準備好
CREATE TABLE `testdata` (
`id` int(11) NOT NULL,
`p1` int(11) NOT NULL,
`p2` int(11) NOT NULL,
`p3` int(11) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
ALTER TABLE `testdata`
ADD PRIMARY KEY (`id`);
ALTER TABLE `testdata`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT;
再來建資料的部份我就不統一了。
用如下看要建立幾筆就自行增加吧。不過我這邊先定位至少要20筆資料
INSERT INTO `testdata` (`p1`, `p2`, `p3`) VALUES (RAND()*9, RAND()*9, RAND()*9);
從題目看來,其實我就是準備了p1 p2 p3的欄位,其值都是0~9的範圍數字。
以上準備好後。我先出比較簡單的題目。
第一題:取得 0~9 總出現數量(這因該還沒什麼難度才對)
範例
1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0
------------- | -------------
0 | 10 | 5 | 0 | 15 | 5 | 7 | 10 | 19 | 0
第二題:同第一題,但要區分 p1 p2 p3的總數量(這因該只有加高一點點難度)
pp | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0
------------- | -------------
p1 | 0 | 10 | 5 | 0 | 15 | 5 | 7 | 10 | 19 | 0
p2 | 0 | 5 | 5 | 0 | 1 | 5 | 7 | 10 | 0 | 0
p3 | 5 | 10 | 5 | 0 | 15 | 5 | 7 | 6 | 19 | 0
第三題:這題會比較難解釋。不懂的話可以再問。
依id值當每一次出現的數字。我範例以10次為主。
求得0~9各自的數字。已多少次沒出現。
假設資料如下
id | p1 | p2 | p3
------------- | -------------
1 | 0 | 7 | 8
2 | 1 | 5 | 3
3 | 7 | 3 | 4
4 | 4 | 5 | 2
5 | 0 | 1 | 6
6 | 3 | 5 | 2
7 | 5 | 6 | 1
8 | 0 | 5 | 4
9 | 3 | 4 | 7
10 | 6 | 5 | 2
則依上面的資料求得的數據是
1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0
------------- | -------------
3 | 0 | 1 | 1 | 0 | 0 | 1 | 9 | 10 | 2
好啦!!!我出完題目了。這三題的難度各自不同。要用sql還是mysql隨意啦。只要是sql語法就行了。不考量效能因素。結果能對就好。
第一題我的解答如下
SELECT
sum(if(p1=1,1,0)+if(p2=1,1,0)+if(p3=1,1,0)) AS b1,
sum(if(p1=2,1,0)+if(p2=2,1,0)+if(p3=2,1,0)) AS b2,
sum(if(p1=3,1,0)+if(p2=3,1,0)+if(p3=3,1,0)) AS b3,
sum(if(p1=4,1,0)+if(p2=4,1,0)+if(p3=4,1,0)) AS b4,
sum(if(p1=5,1,0)+if(p2=5,1,0)+if(p3=5,1,0)) AS b5,
sum(if(p1=6,1,0)+if(p2=6,1,0)+if(p3=6,1,0)) AS b6,
sum(if(p1=7,1,0)+if(p2=7,1,0)+if(p3=7,1,0)) AS b7,
sum(if(p1=8,1,0)+if(p2=8,1,0)+if(p3=8,1,0)) AS b8,
sum(if(p1=9,1,0)+if(p2=9,1,0)+if(p3=9,1,0)) AS b9,
sum(if(p1=0,1,0)+if(p2=0,1,0)+if(p3=0,1,0)) AS b0
FROM `testdata`
這一題倒也沒什麼難度,就跳過不解釋了。
第二題解答
SELECT pp,
sum(if(bb=1,1,0)) AS b1,
sum(if(bb=2,1,0)) AS b2,
sum(if(bb=3,1,0)) AS b3,
sum(if(bb=4,1,0)) AS b4,
sum(if(bb=5,1,0)) AS b5,
sum(if(bb=6,1,0)) AS b6,
sum(if(bb=7,1,0)) AS b7,
sum(if(bb=8,1,0)) AS b8,
sum(if(bb=9,1,0)) AS b9,
sum(if(bb=0,1,0)) AS b0
FROM (
SELECT 'p1' AS pp,p1 AS bb FROM `testdata`
union all
SELECT 'p2' AS pp,p2 AS bb FROM `testdata`
union all
SELECT 'p3' AS pp,p3 AS bb FROM `testdata`
) AS pp
GROUP BY pp
這題解答 舜~ 的解答算是跟我一樣的方式了。簡單來說,只是先將p1、p2、p3拆開重組後。就可以用group處理了。
第三題解答
SELECT
max(sn)-max(b1) AS nonum1,
max(sn)-max(b2) AS nonum2,
max(sn)-max(b3) AS nonum3,
max(sn)-max(b4) AS nonum4,
max(sn)-max(b5) AS nonum5,
max(sn)-max(b6) AS nonum6,
max(sn)-max(b7) AS nonum7,
max(sn)-max(b8) AS nonum8,
max(sn)-max(b9) AS nonum9,
max(sn)-max(b0) AS nonum0
FROM
(
SELECT sn,
if(p1=1 OR p2=1 OR p3=1,sn,0) AS b1,
if(p1=2 OR p2=2 OR p3=2,sn,0) AS b2,
if(p1=3 OR p2=3 OR p3=3,sn,0) AS b3,
if(p1=4 OR p2=4 OR p3=4,sn,0) AS b4,
if(p1=5 OR p2=5 OR p3=5,sn,0) AS b5,
if(p1=6 OR p2=6 OR p3=6,sn,0) AS b6,
if(p1=7 OR p2=7 OR p3=7,sn,0) AS b7,
if(p1=8 OR p2=8 OR p3=8,sn,0) AS b8,
if(p1=9 OR p2=9 OR p3=9,sn,0) AS b9,
if(p1=0 OR p2=0 OR p3=0,sn,0) AS b0
FROM(
SELECT @sn:=@sn+1 AS sn,p1,p2,p3
FROM `testdata`,(SELECT @sn:=0) AS sn
) sortsn
) getmax
這題雖然 舜~ 算很接近解答。可惜的是並不完美。還是會有點小缺點存在。
但就結果論來講。還是對的。
我這是先重新編號重新序號處理。畢竟如果今天這個記錄是將近1萬筆的情況下。
但其實我們根本不需要一次取1萬筆。可以取最後面100筆就夠計算這一題了。
但這樣子如果用id來計算則會相差很遠。
所以用了sn先重新編號處理。再計算出各數字的最大位置。
最後才用最大值相扣就是答案了。
已邀請的邦友 {{ invite_list.length }}/5
mysql 5.6
第一題
select
sum(if(t.p=1,t.cnt,0)) '1'
,sum(if(t.p=2,t.cnt,0)) '2'
,sum(if(t.p=3,t.cnt,0)) '3'
,sum(if(t.p=4,t.cnt,0)) '4'
,sum(if(t.p=5,t.cnt,0)) '5'
,sum(if(t.p=6,t.cnt,0)) '6'
,sum(if(t.p=7,t.cnt,0)) '7'
,sum(if(t.p=8,t.cnt,0)) '8'
,sum(if(t.p=9,t.cnt,0)) '9'
,sum(if(t.p=0,t.cnt,0)) '0'
from(
select p,count(1) cnt
from(
select p1 p from testdata
union all
select p2 p from testdata
union all
select p3 p from testdata
) _p
group by p
) t
第二題
select
pp
,sum(if(p=1,1,0)) '1'
,sum(if(p=2,1,0)) '2'
,sum(if(p=3,1,0)) '3'
,sum(if(p=4,1,0)) '4'
,sum(if(p=5,1,0)) '5'
,sum(if(p=6,1,0)) '6'
,sum(if(p=7,1,0)) '7'
,sum(if(p=8,1,0)) '8'
,sum(if(p=9,1,0)) '9'
,sum(if(p=0,1,0)) '0'
from (
select 'p1'pp, p1 p from testdata
union all
select 'p2'pp, p2 p from testdata
union all
select 'p3'pp, p3 p from testdata
) t
group by pp
第三題
-- set @maxRowNum = 20; -- 偷吃步XD
set @maxRowNum = (select count(1) from testdata limit 1);
select
@maxRowNum-(select max(id) from testdata where p1=1 or p2=1 or p3=1) '1'
,@maxRowNum-(select max(id) from testdata where p1=2 or p2=2 or p3=2) '2'
,@maxRowNum-(select max(id) from testdata where p1=3 or p2=3 or p3=3) '3'
,@maxRowNum-(select max(id) from testdata where p1=4 or p2=4 or p3=4) '4'
,@maxRowNum-(select max(id) from testdata where p1=5 or p2=5 or p3=5) '5'
,@maxRowNum-(select max(id) from testdata where p1=6 or p2=6 or p3=6) '6'
,@maxRowNum-(select max(id) from testdata where p1=7 or p2=7 or p3=7) '7'
,@maxRowNum-(select max(id) from testdata where p1=8 or p2=8 or p3=8) '8'
,@maxRowNum-(select max(id) from testdata where p1=9 or p2=9 or p3=9) '9'
,@maxRowNum-(select max(id) from testdata where p1=0 or p2=0 or p3=0) '0';
有調整了,不過如果增加p4、p5...,數值不只0~9的話,sql就不知道怎麼處理了...
可能只能拉到後端處理?
我其實看不懂浩大的題旨,但既然您的解法浩大沒有說不對,我就拿來照抄,並微調一下,不管是 p4、p5、p6、p7....,數值 0-100 ,照幹。
with temp as (
select
id,
group_concat(p1,',',p2,',',p3) AS vStr
from testdata
group by id
)
select
x.cnt - (select max(id) from temp where instr(vStr,1)) AS '1',
x.cnt - (select max(id) from temp where instr(vStr,2)) AS '2',
x.cnt - (select max(id) from temp where instr(vStr,3)) AS '3',
x.cnt - (select max(id) from temp where instr(vStr,4)) AS '4',
x.cnt - (select max(id) from temp where instr(vStr,5)) AS '5',
x.cnt - (select max(id) from temp where instr(vStr,6)) AS '6',
x.cnt - (select max(id) from temp where instr(vStr,7)) AS '7',
x.cnt - (select max(id) from temp where instr(vStr,8)) AS '8',
x.cnt - (select max(id) from temp where instr(vStr,9)) AS '9',
x.cnt - (select max(id) from temp where instr(vStr,0)) AS '0'
from (select count(*) As cnt from temp) x;
@ckp6250 同三題再給你一個難點讓你思考。如果id不是數值,是日期的話呢??然後還得依序日期先排序好再往回算。
這樣難度會增加很多
太難了啦~
我是新手第 3 級耶,
有沒有幼幼班等級的題目?
至少第一題也該會吧。那又沒啥難度@@"
圖可愛XD
浩大恩准只要回答第一題就好,那我恭敬不如從命~
with temp AS (
SELECT group_concat(concat(p1,p2,p3)) AS vStr
FROM testdata
)
select
(s.nl - LENGTH( REPLACE(vStr,'1','') )) AS `1`,
(s.nl - LENGTH( REPLACE(vStr,'2','') )) AS `2`,
(s.nl - LENGTH( REPLACE(vStr,'3','') )) AS `3`,
(s.nl - LENGTH( REPLACE(vStr,'4','') )) AS `4`,
(s.nl - LENGTH( REPLACE(vStr,'5','') )) AS `5`,
(s.nl - LENGTH( REPLACE(vStr,'6','') )) AS `6`,
(s.nl - LENGTH( REPLACE(vStr,'7','') )) AS `7`,
(s.nl - LENGTH( REPLACE(vStr,'8','') )) AS `8`,
(s.nl - LENGTH( REPLACE(vStr,'9','') )) AS `9`,
(s.nl - LENGTH( REPLACE(vStr,'0','') )) AS `0`
from temp , (select LENGTH(vStr) AS nl from temp ) AS s;
這個站都不准多話,昨天講沒幾句,就到上限了;別的站都鼓勵會員多多發言,本站反其道而行。
這個哥哥你誤會了,因為在本站發言,對Google搜尋排名很有用的.
所以以前會有很多來打廣告的,往往會發很多,所以後來才調整成
現在的限制,這也是不得已的.
話說,小雨大你怎麼沒答題。
話說,
前兩題如果90度轉過來簡單很多...
通常這種題目我會用後端語言跑迴圈,
這直接寫SQL語法太痛苦了 XD
第三題我承認用後端處理會比較好沒錯。
不過前兩題可不一定喔。
用sql會反而比較好。
我意思是...
後端跑迴圈組出SQL語法...
我的看法稍有不同。
我認為只要牽涉到和『資料庫』有關的計算,sql 永遠比拉到後端要有效率的多。
我覺得沒衝突...sql script執行效率一定比拉到後端快,畢竟拉到後端就沒有索引加持了,但有限的開發時間內開發效率與後續維護拉到後端會比較快~~
我好像從來沒說過拉到後端做,
我只是說用後端語言組比較方便,
而且比較靈活.
嗯!尺有所短,寸有所長。
可能是我的 sql 比我的 php 熟練一點,才會喜歡在 sql 端解決。
你可以用程式寫在輸出sql碼到這啊。
這其實之前是我的面試題。第一題其實有陷阱的。
舜~ 其實並沒寫對。因為他中了我設下的陷阱
我覺得啊,這就是浩大的不是了。
浩大並沒有發佈【資料】及【正確答案】,我們寫了半天,也沒辦法檢驗是否正確,您看我的出題,資料固定,答案給出,各人不管用什麼語法,只要比對答案正確,那就過關了。
題目重出啦。
程式界裏,沒有所謂的正確答案,也沒有所謂的標準答案。
所以,雖然我會這樣說。但我也會認同他的答案。
畢竟,在跟客戶的對應上,並沒有客戶會好好的告訴你排法、資料。
只會跟你說我想要ooxx。
只要結果對就行了,無論未來會發生什麼事。
ckp6250
資料有啊
恩恩,
也是可以,
早上看LINE花太多時間了,
晚上再來貼吧.
我的意思不是要【正確答案】,而是【比對標準】。
一群資料,可以用千百種 sql 語法去跑,可是正確的【結果】,也只會有一個,把這個結果交給客戶,假如客戶說不對的話,那麼我們也只能請客戶告訴我們,他認為對的結果是什麼?我們再根據客戶要求的結果,去修正我們的做法。
不過呢,由各家不同的解題手法上,也學到不少東西,有些思路可能是以前自己沒想過的,這是最大的收獲。
結果我還是手癢了,
先來做第一題.
是我太弱嗎?
我寫出來的SQL怎麼這麼長...
SELECT (SELECT COUNT(1) FROM `testdata` WHERE `p1` = 0) + (SELECT COUNT(1) FROM `testdata` WHERE `p2` = 0) + (SELECT COUNT(1) FROM `testdata` WHERE `p3` = 0) AS `0` ,(SELECT COUNT(1) FROM `testdata` WHERE `p1` = 1) + (SELECT COUNT(1) FROM `testdata` WHERE `p2` = 1) + (SELECT COUNT(1) FROM `testdata` WHERE `p3` = 1) AS `1` ,(SELECT COUNT(1) FROM `testdata` WHERE `p1` = 2) + (SELECT COUNT(1) FROM `testdata` WHERE `p2` = 2) + (SELECT COUNT(1) FROM `testdata` WHERE `p3` = 2) AS `2` ,(SELECT COUNT(1) FROM `testdata` WHERE `p1` = 3) + (SELECT COUNT(1) FROM `testdata` WHERE `p2` = 3) + (SELECT COUNT(1) FROM `testdata` WHERE `p3` = 3) AS `3` ,(SELECT COUNT(1) FROM `testdata` WHERE `p1` = 4) + (SELECT COUNT(1) FROM `testdata` WHERE `p2` = 4) + (SELECT COUNT(1) FROM `testdata` WHERE `p3` = 4) AS `4` ,(SELECT COUNT(1) FROM `testdata` WHERE `p1` = 5) + (SELECT COUNT(1) FROM `testdata` WHERE `p2` = 5) + (SELECT COUNT(1) FROM `testdata` WHERE `p3` = 5) AS `5` ,(SELECT COUNT(1) FROM `testdata` WHERE `p1` = 6) + (SELECT COUNT(1) FROM `testdata` WHERE `p2` = 6) + (SELECT COUNT(1) FROM `testdata` WHERE `p3` = 6) AS `6` ,(SELECT COUNT(1) FROM `testdata` WHERE `p1` = 7) + (SELECT COUNT(1) FROM `testdata` WHERE `p2` = 7) + (SELECT COUNT(1) FROM `testdata` WHERE `p3` = 7) AS `7` ,(SELECT COUNT(1) FROM `testdata` WHERE `p1` = 8) + (SELECT COUNT(1) FROM `testdata` WHERE `p2` = 8) + (SELECT COUNT(1) FROM `testdata` WHERE `p3` = 8) AS `8` ,(SELECT COUNT(1) FROM `testdata` WHERE `p1` = 9) + (SELECT COUNT(1) FROM `testdata` WHERE `p2` = 9) + (SELECT COUNT(1) FROM `testdata` WHERE `p3` = 9) AS `9`
我的資料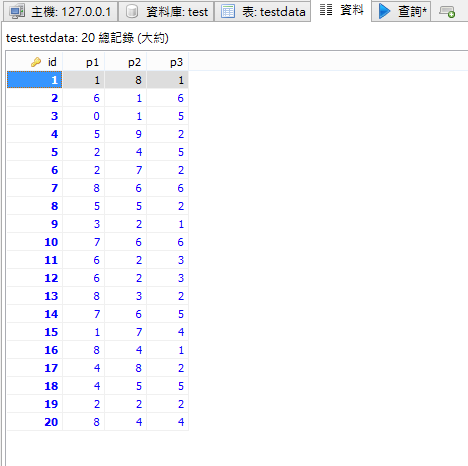
我的結果
不錯,小魚把第一題的第二種方法處理出來了。
第二題,
我真的被考倒了,
(我就是偏要用COUNT)
還去Google了一下.
SELECT title, COUNT(IF(`data` = 0, 1, NULL)) AS `0` ,COUNT(IF(`data` = 1, 1, NULL)) AS `1` ,COUNT(IF(`data` = 2, 1, NULL)) AS `2` ,COUNT(IF(`data` = 3, 1, NULL)) AS `3` ,COUNT(IF(`data` = 4, 1, NULL)) AS `4` ,COUNT(IF(`data` = 5, 1, NULL)) AS `5` ,COUNT(IF(`data` = 6, 1, NULL)) AS `6` ,COUNT(IF(`data` = 7, 1, NULL)) AS `7` ,COUNT(IF(`data` = 8, 1, NULL)) AS `8` ,COUNT(IF(`data` = 9, 1, NULL)) AS `9`FROM (SELECT 'p1' AS `title`, `p1` AS `data` FROM `testdata` UNION ALL SELECT 'p2' AS `title`, `p2` AS `data` FROM `testdata` UNION ALL SELECT 'p3' AS `title`, `p3` AS `data` FROM `testdata`) AS root GROUP BY `title`
結果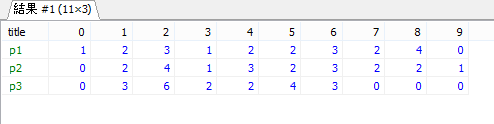
第三題的意思是要看ID?
所以ID一定是從頭開始並且連續?
第三題我用了存儲過程
CREATE DEFINER=`root`@`localhost` PROCEDURE `getMyValue`()
LANGUAGE SQL
NOT DETERMINISTIC
CONTAINS SQL
SQL SECURITY DEFINER
COMMENT ''
BEGIN
DECLARE maxval INT DEFAULT 0;
SET maxval = (SELECT IFNULL(MAX(id), 0) FROM `testdata`);
SELECT (maxval - (SELECT MAX(id) FROM `testdata` WHERE `p1` = 0 OR `p2` = 0 OR `p3` = 0)) AS `0` ,(maxval - (SELECT MAX(id) FROM `testdata` WHERE `p1` = 1 OR `p2` = 1 OR `p3` = 1)) AS `1` ,(maxval - (SELECT MAX(id) FROM `testdata` WHERE `p1` = 2 OR `p2` = 2 OR `p3` = 2)) AS `2` ,(maxval - (SELECT MAX(id) FROM `testdata` WHERE `p1` = 3 OR `p2` = 3 OR `p3` = 3)) AS `3` ,(maxval - (SELECT MAX(id) FROM `testdata` WHERE `p1` = 4 OR `p2` = 4 OR `p3` = 4)) AS `4` ,(maxval - (SELECT MAX(id) FROM `testdata` WHERE `p1` = 5 OR `p2` = 5 OR `p3` = 5)) AS `5` ,(maxval - (SELECT MAX(id) FROM `testdata` WHERE `p1` = 6 OR `p2` = 6 OR `p3` = 6)) AS `6` ,(maxval - (SELECT MAX(id) FROM `testdata` WHERE `p1` = 7 OR `p2` = 7 OR `p3` = 7)) AS `7` ,(maxval - (SELECT MAX(id) FROM `testdata` WHERE `p1` = 8 OR `p2` = 8 OR `p3` = 8)) AS `8` ,(maxval - (SELECT MAX(id) FROM `testdata` WHERE `p1` = 9 OR `p2` = 9 OR `p3` = 9)) AS `9`;
END
呼叫存儲過程
call getMyValue;
結果
只做第三題
create table it191213 (
id smallint not null primary key
, p1 smallint not null
, p2 smallint not null
, p3 smallint not null
);
insert into it191213 values
(1, 0, 7, 8),
(2, 1, 5, 3),
(3, 7, 3, 4),
(4, 4, 5, 2),
(5, 0, 1, 6),
(6, 3, 5, 2),
(7, 5, 6, 1),
(8, 0, 5, 4),
(9, 3, 4, 7),
(10, 6, 5, 2);
-----------
-- 使用 lateral join 來循環產生
select n
, maxid
from generate_series(0, 9) g(n)
join lateral
(select max(id) as maxid
from it191213
where p1 = n
or p2 = n
or p3 = n
) c on true;
+---+-------+
| n | maxid |
+---+-------+
| 0 | 8 |
| 1 | 7 |
| 2 | 10 |
| 3 | 9 |
| 4 | 9 |
| 5 | 10 |
| 6 | 10 |
| 7 | 9 |
| 8 | 1 |
| 9 | ¤ |
+---+-------+
(10 rows)
-- 接著繼續加工, 做轉向.還要注意到 null 變為 0, 還有取得最大id
with t1 as (
select n
, coalesce(maxid, 0) as newid
from generate_series(0, 9) g(n)
join lateral
(select max(id) as maxid
from it191213
where p1 = n
or p2 = n
or p3 = n
) c on true
), t2 as (
select max(id) as realmax
from it191213
)
select realmax - sum(newid) filter (where n = 1) as "1"
, realmax - sum(newid) filter (where n = 2) as "2"
, realmax - sum(newid) filter (where n = 3) as "3"
, realmax - sum(newid) filter (where n = 4) as "4"
, realmax - sum(newid) filter (where n = 5) as "5"
, realmax - sum(newid) filter (where n = 6) as "6"
, realmax - sum(newid) filter (where n = 7) as "7"
, realmax - sum(newid) filter (where n = 8) as "8"
, realmax - sum(newid) filter (where n = 9) as "9"
, realmax - sum(newid) filter (where n = 0) as "0"
from t1
, t2
group by realmax;
+---+---+---+---+---+---+---+---+----+---+
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0 |
+---+---+---+---+---+---+---+---+----+---+
| 3 | 0 | 1 | 1 | 0 | 0 | 1 | 9 | 10 | 2 |
+---+---+---+---+---+---+---+---+----+---+


 iThome鐵人賽
iThome鐵人賽