目前在用python學爬蟲, 其中一個題目是要爬這個網址
https://www.zhihu.com/explore
但用 requests.get() 都會跑出 400 Bad Request 的資料
像這樣
<html>
<head><title>400 Bad Request</title></head>
<body bgcolor="white">
<center><h1>400 Bad Request</h1></center>
<hr><center>openresty</center>
</body>
</html>
搜了網址發現一進去就會跳出要我們登入的彈出視窗, 因此猜測是因為這樣而出現錯誤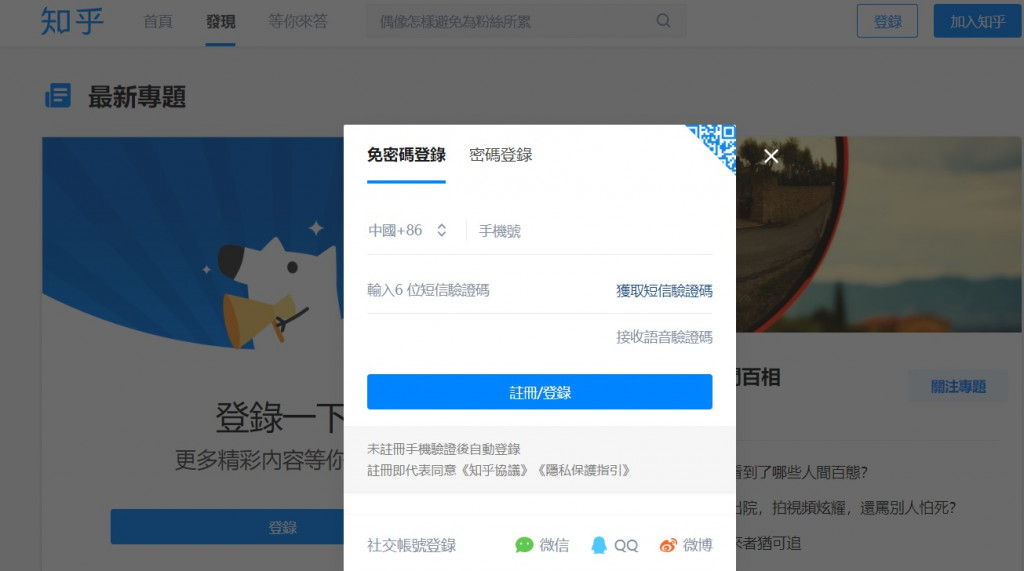
求解~
已邀請的邦友 {{ invite_list.length }}/5
因此猜測是因為這樣而出現錯誤
逼逼 猜錯了
在 header 補上你的 user-agent
code
import requests
url = "https://www.zhihu.com/explore"
headers= {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36"
}
response = requests.get(url, headers=headers)
print(response.text)
碰到需要登入的網頁,通常你瀏覽到某些頁面,系統會幫你redirect到登入頁,用爬蟲抓,可能會得到 response code=302 的空頁,一個較簡單的解決方法是,自己主動爬到登入頁,驗證過,再爬你要的網頁。
這類的網頁使用 selenium ,模擬人的輸入,比較會成功。
程式碼可參考:
https://github.com/bnorquist/auto_login/blob/master/scripts/login.py#L7

 iThome鐵人賽
iThome鐵人賽