https://ithelp.ithome.com.tw/questions/10199175
這次的問題是上一篇的延伸
在那之後我有把完整程式碼補完整
import pandas as pd
import numpy as np
df = pd.read_excel('C:\\Users\\user\\20200102.xlsx', header=0, index_col=None)
df = pd.DataFrame(df)
A = np.array(df[:300]['Date'])
B = np.array(df[:300]['Time'])
C = np.array(df[:300]['Open'])
D = np.array(df[:300]['High'])
E = np.array(df[:300]['Low'])
F = np.array(df[:300]['Close'])
G = np.array(df[:300]['Volume'])
H1,H2= [] ,[]
for i in range(0, 300) :
for x in range(i , 300) :
if df.at[x, 'High'] - df.at[i, 'Open'] >=20 :
H1.append(B[x])
H2.append(20)
break
elif df.at[i, 'Open'] - df.at[x, 'Low'] >=20 :
H1.append(B[x])
H2.append(-20)
break
data_dist = {
"Date":A,
"Time":B,
"Open":C,
"High":D, "Low":E,"Close":F,"Volume":G,
"損益時間20 20":H1,"損益20 20":H2}
data_df = pd.DataFrame.from_dict(data_dist, orient='index')
data_df1 = data_df.T
print(data_df1)
#data_df1.to_csv('20200102+-全.csv', encoding='utf_8_sig')
這次的問題是我想直接統計一年但結果怪怪的我想要的是今天統計完統計隔天的今天和隔天彼此不相關也就是執行把上面程式碼執行好幾次但我迴圈執行出來的東西跟我想要的不一樣
第一天後半部接近13:45分後第二天之後結果都是錯的
https://imgur.com/rrkHadf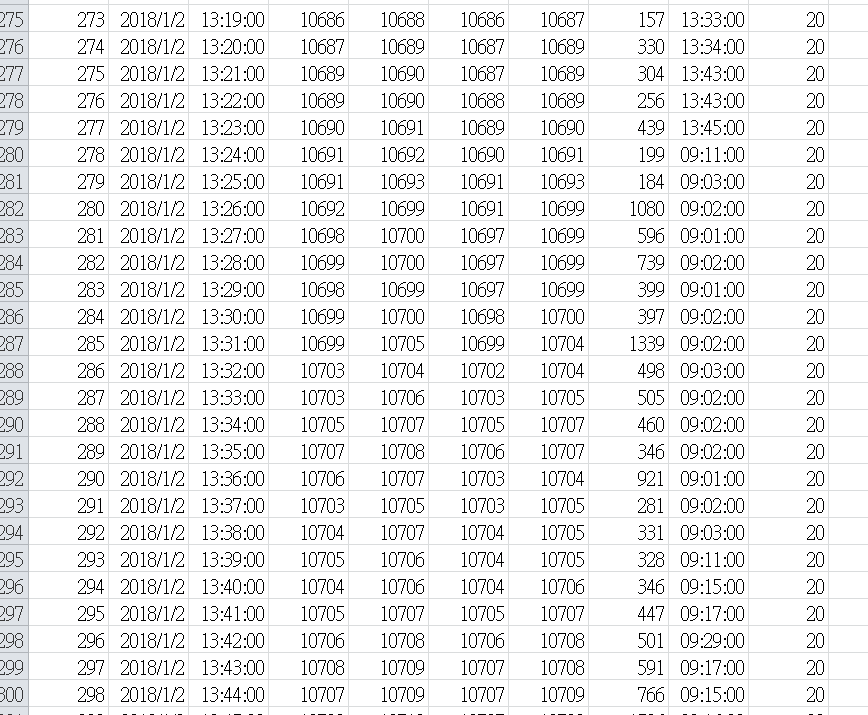
H1.append(B[x])
H2.append(20)
這部分寫入問題
不知道怎麼寫到正確的地方的地方
我自己再努力想想
EXCEL檔案
https://drive.google.com/file/d/1wWD5_bZuSfb23uqCcJoKSKB54uk39TcC/view?usp=sharing
import pandas as pd
import numpy as np
df = pd.read_excel('E:\\future\\2018.xlsx', header=0, index_col=None)
df = pd.DataFrame(df)
A = np.array(df[:70500]['Date'])
B = np.array(df[:70500]['Time'])
C = np.array(df[:70500]['Open'])
D = np.array(df[:70500]['High'])
E = np.array(df[:70500]['Low'])
F = np.array(df[:70500]['Close'])
G = np.array(df[:70500]['Volume'])
H1,H2= [] ,[]
for d in range (0,235):
for i in range(0+d*300, 300+d*300) :
for x in range(i , 300+d*300 ) :
if df.at[x, 'High'] - df.at[i, 'Open'] >=20 :
H1.append(B[x])
H2.append(20)
break
elif df.at[i, 'Open'] - df.at[x, 'Low'] >=20 :
H1.append(B[x])
H2.append(-20)
break
data_dist = {
"Date":A,
"Time":B,
"Open":C,
"High":D, "Low":E,"Close":F,"Volume":G,
"損益時間20 20":H1,"損益20 20":H2}
data_df = pd.DataFrame.from_dict(data_dist, orient='index')
data_df1 = data_df.T
print(data_df1)
#data_df1.to_csv('2018+-全.csv', encoding='utf_8_sig')
程式碼為下方
自己搞錯重點很抱歉
import pandas as pd
import numpy as np
df = pd.read_excel('E:\\future\\2018.xlsx', header=0, index_col=None)
df = pd.DataFrame(df)
A = np.array(df[:70500]['Date'])
B = np.array(df[:70500]['Time'])
C = np.array(df[:70500]['Open'])
D = np.array(df[:70500]['High'])
E = np.array(df[:70500]['Low'])
F = np.array(df[:70500]['Close'])
G = np.array(df[:70500]['Volume'])
H1,H2= [] ,[]
data_dist = {
"Date":A,
"Time":B,
"Open":C,
"High":D, "Low":E,"Close":F,"Volume":G,
"損益時間20 20":H1,"損益20 20":H2}
data_df = pd.DataFrame.from_dict(data_dist, orient='index')
data_df1 = data_df.T
print(data_df1)
rowmax = 300
for d in range(0,235):
for i in range(0+d*300, 300+d*300):
for x in range(i , 300+d*300 ):
if data_df1.at[x, 'High'] - data_df1.at[i, 'Open'] >=20 :
data_df1.at[i, '損益時間20 20'] = B[x]
data_df1.at[i,'損益20 20'] = 20
break
elif data_df1.at[i, 'Open'] - data_df1.at[x, 'Low'] >=20 :
data_df1.at[i, '損益時間20 20'] = B[x]
data_df1.at[i,'損益20 20'] = -20
break
print(data_df1)
data_df1.to_csv('2018+-全12.csv', encoding='utf_8_sig')
已邀請的邦友 {{ invite_list.length }}/5
rowmax = 300
for d in range(0,235):
for i in range(d*rowmax,(d+1)*rowmax-1):
for x in range(i+1,(d+1)*rowmax):
更新
import pandas as pd
import numpy as np
# df = pd.read_excel('C:\\Users\\user\\20200102.xlsx', header=0, index_col=None)
df = pd.read_csv('./20200102.csv')
df = pd.DataFrame(df)
A = np.array(df[:70500]['Date'])
B = np.array(df[:70500]['Time'])
C = np.array(df[:70500]['Open'])
D = np.array(df[:70500]['High'])
E = np.array(df[:70500]['Low'])
F = np.array(df[:70500]['Close'])
G = np.array(df[:70500]['Volume'])
H = np.array(df[:70500]['ActDate'])
I = np.array(df[:70500]['ActTime'])
J = np.array(df[:70500]['Value'])
rowmax = 30
for d in range(0,2):
for i in range(d*rowmax,(d+1)*rowmax-1):
for x in range(i+1,(d+1)*rowmax):
if df.at[x, 'High'] - df.at[i, 'Open'] >=20 :
H[i]=df.at[x, 'Date']
I[i]=df.at[x, 'Time']
J[i]=20
break
elif df.at[i, 'Open'] - df.at[x, 'Low'] >=20 :
H[i]=df.at[x, 'Date']
I[i]=df.at[x, 'Time']
J[i]=-20
break
data_dist = {
"Date":A,
"Time":B,
"Open":C,
"High":D,
"Low":E,
"Close":F,
"Volume":G,
"ActDate":H,
"ActTime":I,
"Value":J
}
data_df = pd.DataFrame.from_dict(data_dist, orient='index')
data_df1 = data_df.T
print(data_df1)
#data_df1.to_csv('20200102+-全.csv', encoding='utf_8_sig')
感謝您的回答
我把它套進我程式碼
出現下方錯誤
嘗試google debug
說是縮進問題
File "<ipython-input-5-4691a8a2fb5e>", line 19
for i in range(d*rowmax, (d+1)*rowmax - 2) :
^
IndentationError: expected an indented block
應該就是前後的空格不同吧
前面可能是空4格
這個直接貼上可能只有空2格
https://repl.it/repls/MisguidedDimgreyMemwatch#main.py
可以執行不過因為是 3 個迴圈會跑比較久
抱歉
我知道問題出在哪了
剛剛仔細看
迴圈+判定都沒問題
第一天後面數據
其實沒跑掉
只是剛好出來的時間序列剛好比較特別
我以為數據是錯的
問題是出在這
H1.append(B[x])
H2.append(20)
這部分這樣寫會是一直接者寫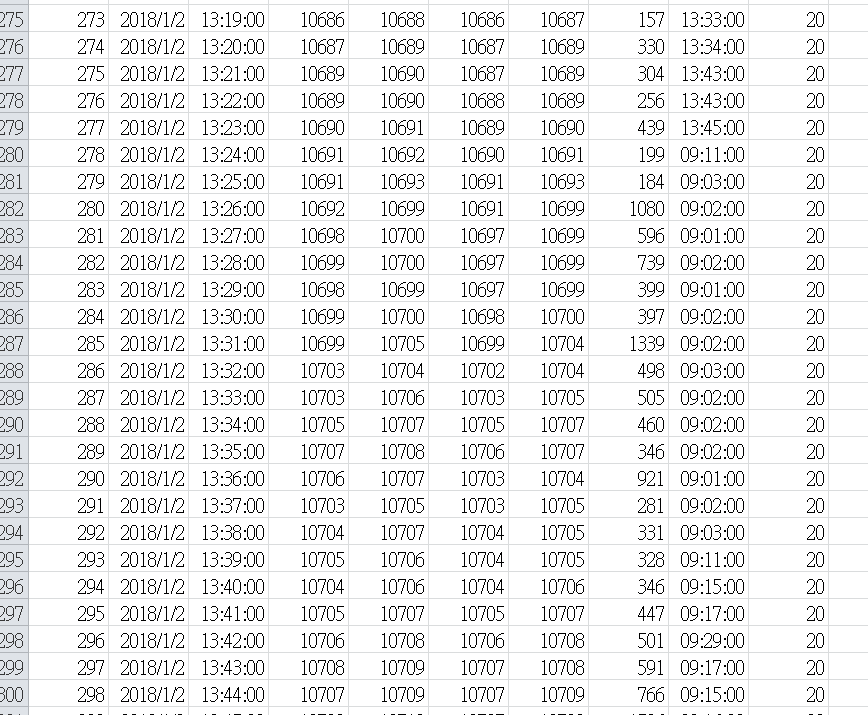
所以跟迴圈判斷式沒關係
是我寫入EXCEL
還有我陣列和程式碼問題
真的很抱歉
先入為主的搞錯問題出在哪
listennn08
不好意思想請教您一下
因為我的程式碼關於pandas numpy DataFrame
是照者這篇https://ithelp.ithome.com.tw/questions/10198832
您回答的那篇當模板
慢慢查資料慢慢改的
這次程式碼靠rogeryao指導我迴圈和判定
(學習了許多感謝rogeryao大大)
算是完成了這次的數據處裡
這樣算大數據處理嘛!?
想請教的是我下方程式碼關於pandas numpy DataFrame
有什麼地方需要改進的?
感謝
import pandas as pd
import numpy as np
df = pd.read_excel('E:\\future\\2018.xlsx', header=0, index_col=None)
df = pd.DataFrame(df)
A = np.array(df[:70500]['Date'])
B = np.array(df[:70500]['Time'])
C = np.array(df[:70500]['Open'])
D = np.array(df[:70500]['High'])
E = np.array(df[:70500]['Low'])
F = np.array(df[:70500]['Close'])
G = np.array(df[:70500]['Volume'])
H1,H2= [] ,[]
data_dist = {
"Date":A,
"Time":B,
"Open":C,
"High":D, "Low":E,"Close":F,"Volume":G,
"損益時間20 20":H1,"損益20 20":H2}
data_df = pd.DataFrame.from_dict(data_dist, orient='index')
data_df1 = data_df.T
print(data_df1)
rowmax = 300
for d in range(0,235):
for i in range(0+d*300, 300+d*300):
for x in range(i , 300+d*300 ):
if data_df1.at[x, 'High'] - data_df1.at[i, 'Open'] >=20 :
data_df1.at[i, '損益時間20 20'] = B[x]
data_df1.at[i,'損益20 20'] = 20
break
elif data_df1.at[i, 'Open'] - data_df1.at[x, 'Low'] >=20 :
data_df1.at[i, '損益時間20 20'] = B[x]
data_df1.at[i,'損益20 20'] = -20
break
print(data_df1)
data_df1.to_csv('2018+-全12.csv', encoding='utf_8_sig')
rogeryao
我訊息次數沒了
這邊回復一下
輸出
rowmax = 5
for d in range(0,2):
for i in range(d*rowmax,(d+1)*rowmax-1):
for x in range(i+1,(d+1)*rowmax):
print(d,i,x)
結果
0 0 1
0 0 2
0 0 3
0 0 4
0 1 2
0 1 3
0 1 4
0 2 3
0 2 4
0 3 4
1 5 6
1 5 7
1 5 8
1 5 9
1 6 7
1 6 8
1 6 9
1 7 8
1 7 9
1 8 9
輸出
for d in range(0,2):
for i in range(d*rowmax,(d+1)*rowmax):
for x in range(i,(d+1)*rowmax):
print(d,i,x)
結果
0 0 0
0 0 1
0 0 2
0 0 3
0 0 4
0 1 1
0 1 2
0 1 3
0 1 4
0 2 2
0 2 3
0 2 4
0 3 3
0 3 4
0 4 4
1 5 5
1 5 6
1 5 7
1 5 8
1 5 9
1 6 6
1 6 7
1 6 8
1 6 9
1 7 7
1 7 8
1 7 9
1 8 8
1 8 9
1 9 9
當分鐘也判定進去
我覺得把+1 -1拿掉才正常
如果加上+1 -1
當分鐘沒判定到
最後一分鐘也沒判定
就依實際數據測試看看,跑出來的結果合不合理
https://ithelp.ithome.com.tw/questions/10199175
這篇有寫
四個發生情形
第一個就是A[0]來說A[0]+20 <= B
A[0]-20 >= C
看哪個較早
第三種情形發生True位子一樣
通常發生在1分鐘上下波動較大
這樣停利還是停損
要看每秒的成交明細
才能知道哪個情形發生
但這種情形不常發生
第四種就是全都是False
通常在接近收盤時會大機率發生
紀錄open最先紀錄
high low是期間
close 是收盤最尾巴紀錄
這也是畫K線圖所需要資料
確實是有機率發生當分鐘同時發生停利停損
rogeryao
好的
我有稍微比對過
基本上一樣
第一分鐘如果有停利或停損
才有差
最後一分鐘基本上沒差
