各位大大好,小弟是爬蟲新手,最近在用request抓取網頁的資料,但目前在抓取以下網站的資料(ex樹木編號、健康度、圖片等)時,request的結果沒有(樹木編號、健康度、圖片等)這些資料
https://www.culture.gov.taipei/frontsite/tree/treeProtectListAction.do?method=doReadDetail&treeId=1
我觀察是在這個地方顯示資料(ex樹木編號、健康度、圖片等)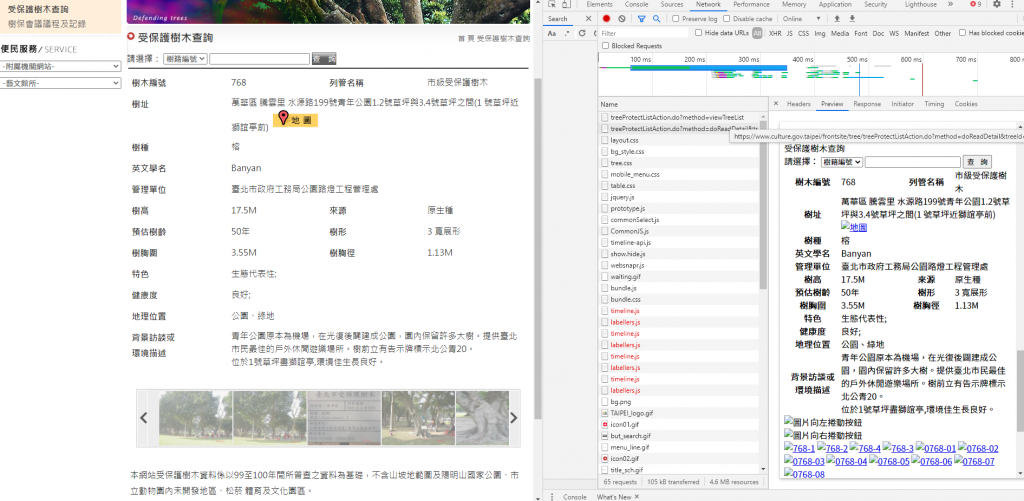
程式碼如下(我以為是cookie和User-Agent的問題,加上去也沒有改善)
url = 'http://www.culture.gov.taipei/frontsite/tree/treeProtectListAction.do?method=doReadDetail&subMenuId=34&siteId=MTA2&treeId=1'
headers = {
'Cookie': '_ga=GA1.2.158213246.1599196959; _gid=GA1.2.2075770048.1604891241; JSESSIONID=B9D11BC92021B9642FA1ECEAA2CA52C1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36'
}
r = requests.get(url,headers=headers)
print(r.text)
request的結果如下,沒有我要找的資料,連樹木編號上方"受保護樹木查詢"這個區塊的資料也沒有,request的結果只有網頁上方、左邊及下方的資料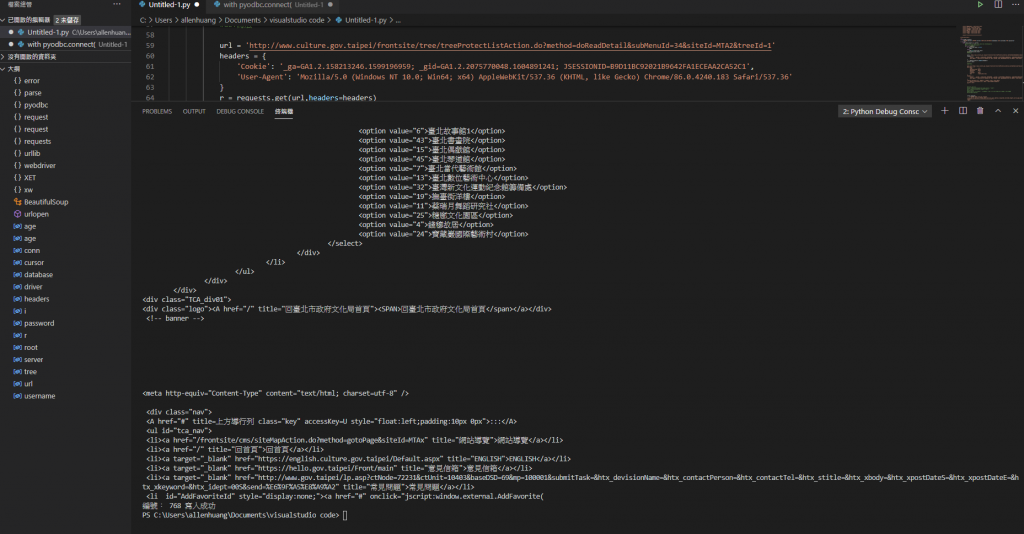
PS小弟第一次上來發問,如果有問題敘述不清楚的地方再請提出~
已邀請的邦友 {{ invite_list.length }}/5
沒有問題喔!
url = 'https://www.culture.gov.taipei/frontsite/tree/treeProtectListAction.do?method=doReadDetail&treeId=1'
# 引入 requests 模組
import requests
from bs4 import BeautifulSoup
# 使用 GET 方式下載普通網頁
r = requests.get(url)
# print(r.text)
soup = BeautifulSoup(r.text, 'html.parser')
ydivs = soup.findAll("table", {"class": "detail2_list02 tree_detail"})
print(ydivs[0].text)
用 requests 要自己解 xml
不如直接用 beautifulsoup 或是 pandas
比如
import pandas as pd
df = pd.read_html("https://www.culture.gov.taipei/frontsite/tree/treeProtectListAction.do?method=doReadDetail&subMenuId=34&siteId=MTA2&treeId=1")
