各位前輩好,不好意思,又上來請教問題了~
先前情提要一下:連結
資料分類條件如下圖:
資料分佈情況與判斷條件如下圖: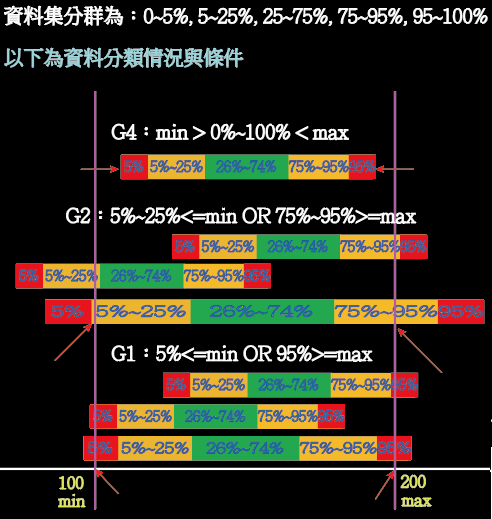
之前前輩指點的SQL處理語法如下:
SELECT Xtype,X1,X2,X3,
CASE
WHEN X3 <> 0 THEN 'X3'
WHEN X3 = 0 AND X1 <> 0 THEN 'X1'
WHEN X3 = 0 AND X1 = 0 AND X2 <> 0 THEN 'X2'
WHEN X3 = 0 AND X1 = 0 AND X2 = 0 THEN NULL
END AS XGROUP_NEW
FROM (
SELECT Xtype,
SUM(CASE WHEN XGROUP='X1' THEN TempValue ELSE 0 END) AS 'X1',
SUM(CASE WHEN XGROUP='X2' THEN TempValue ELSE 0 END) AS 'X2',
SUM(CASE WHEN XGROUP='X3' THEN TempValue ELSE 0 END) AS 'X3'
FROM (
SELECT Xtype,1 AS TempValue,
CASE
WHEN Xvalue <= Xmin
THEN 'X1'
WHEN Xvalue >= Xmax
THEN 'X3'
WHEN Xvalue > Xmin AND Xvalue < Xmax
THEN 'X2'
END AS XGROUP
FROM TypeGroupTest) AS TempA
GROUP BY Xtype
) AS TempB
ORDER BY Xtype
需求說明:
現在要將資料依各百分比分群後,再依照各群組資料分佈狀況下去分類,百分比分群共分為:0~5%, 5~25%, 25~75%, 75~95%, 95~100%,5個群組。
依5個群組的每筆資料下去觀察是否有在min, max條件之內,若沒有則依圖1分類條件進行分類,將資料分別歸類至G1~G4的類別:
G1:5%<=min OR 95%>=max
G2:5%~25%<=min OR 75%~95%>=max
G4:min > 0%~100% < max
G3:若資料集沒有設定min或max(min=0 OR max=0)則分類為G3
分類優先次序:G3 > G2 > G1 > G4
這邊有想到一個擬人化或故事化的方式來說明,不再只是一組冷冰冰的數字及條件,我想這樣應該會清楚很多~
首先為了簡化說明,我就只針對左邊min及50%以下竹旳資料做說明,另外一邊max或50%以上就只是反向而己,邏輯都一樣,就不多做說明,以免搞的太複雜
為了讓資料更真實,我又擴增了範例資料量~
範例資料裡的每一組資料集合(G1Data ~ G4Data)我們將它比喻為是每一個班級,而每一個班級裡都存在著不同總數量的學生(G1=30,G2=35,G3=10,G4=25),班級裡的每一個學生都會有自己的分數(XValue),資料集會依學生的分數遞增排序
現在學校想要將各個班級做分類,所以定下了一些分類條件(min, max),
分類條件為:
1.若班級裡學生的分數全部都落在min~max之間,則將它分類為正常班(G4)
2.若班級裡前5%學生裡任何一位學生的分數小於min,則將它分類為加強班(G1)
3.若班級裡在5%~25%的學生裡任何一位學生的分數小於min,則將它分類為觀察班(G2)
4.若班級裡沒有設定(min=0 or max=0)條件的,則將它分類為等待定義班(G3)
不知道要如何動態的計算各資料集的百分比分群,然後依序觀察條件值將資料分類呢?
感謝版上各位先進大大每次的指點分享~大感謝~
已邀請的邦友 {{ invite_list.length }}/5
SELECT Xtype,G1,G2,G3,G4,
CASE WHEN G3 <> 0 THEN 'G3'
WHEN G3 = 0 AND G2 <> 0 THEN 'G2'
WHEN G3 = 0 AND G2 = 0 AND G1 <> 0 THEN 'G1'
WHEN G3 = 0 AND G1 = 0 AND G2 = 0 AND G4 <> 0 THEN 'G4'
END AS XGROUP_NEW
FROM (
SELECT Xtype,
SUM(CASE WHEN Xmin=0 OR Xmax=0 THEN 1 ELSE 0 END) AS 'G3',
SUM(CASE WHEN XvalueTypeMin>Xmin AND XvalueTypeMax<Xmax THEN 1 ELSE 0 END) AS 'G4',
SUM((CASE WHEN Group1='S1' AND Xvalue <=Xmin THEN 1 ELSE 0 END) + (CASE WHEN Group1='S5' AND Xvalue >=Xmax THEN 1 ELSE 0 END)) AS 'G1',
SUM((CASE WHEN Group1='S2' AND Xvalue <=Xmin THEN 1 ELSE 0 END) + (CASE WHEN Group1='S4' AND Xvalue >=Xmax THEN 1 ELSE 0 END)) AS 'G2'
FROM (
SELECT *,
CASE WHEN (Percentage>0 AND Percentage<=5) THEN 'S1'
WHEN (Percentage>5 AND Percentage<=25) THEN 'S2'
WHEN (Percentage>25 AND Percentage<=75) THEN 'S3'
WHEN (Percentage>75 AND Percentage<=95) THEN 'S4'
WHEN (Percentage>95 AND Percentage<=100) THEN 'S5' END AS Group1,
MIN(Xvalue) OVER(PARTITION BY Xtype) AS XvalueTypeMin,
MAX(Xvalue) OVER(PARTITION BY Xtype) AS XvalueTypeMax
FROM (
SELECT Xtype,Xvalue,ISNULL(Xmin,0) AS Xmin,ISNULL(Xmax,0) AS Xmax,ROW_NUMBER() OVER(PARTITION BY Xtype ORDER BY Xvalue) AS RowNum,
100.00*ROW_NUMBER() OVER(PARTITION BY Xtype ORDER BY Xvalue)/COUNT(1) OVER(PARTITION BY Xtype) AS Percentage
FROM TypeGroupTest
) AS TEMPA
) AS TEMPB
GROUP BY Xtype
) AS TEMPC
ORDER BY Xtype
基本上主要的問題在於每 5% 的分開. 之後直接就是口語敘述直接轉成 SQL. (我的測試環境 Copy & Paste 不能工作, 所以用截圖替代)
首先生成數據, 隨便四個班級, 每個班不同人數, 亂數分數 (以下用 Oracle 為範例, 每個 RDBMS 都有類似的功能)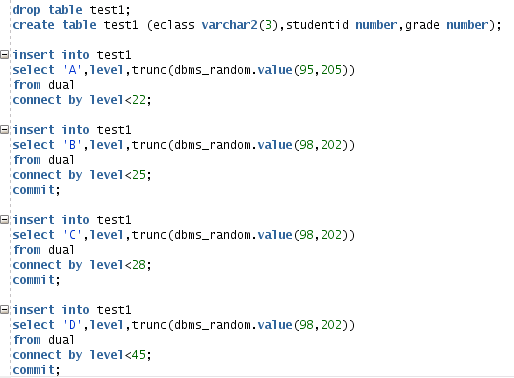
看一下數據長哪樣 (順便 5% 分類)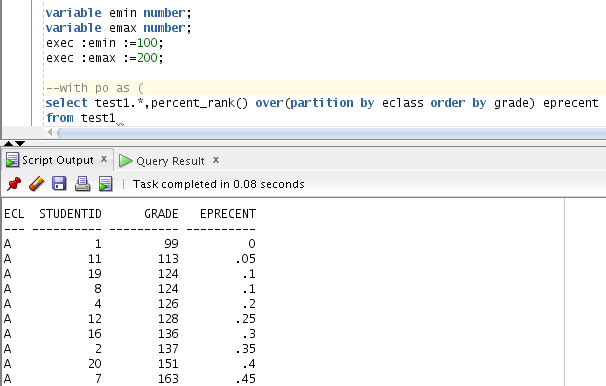
開始分類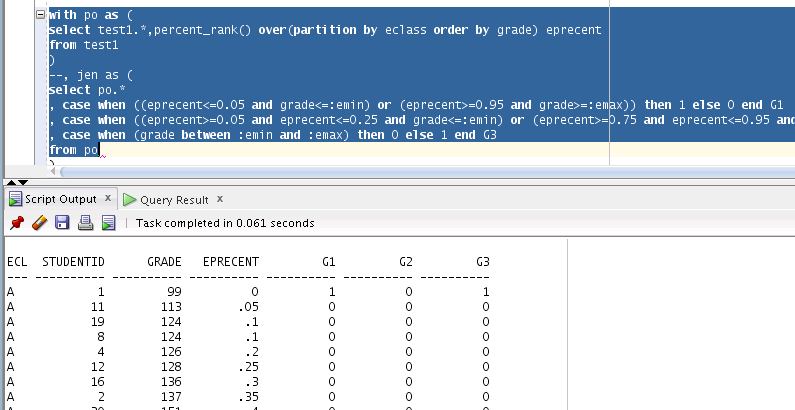
班級總結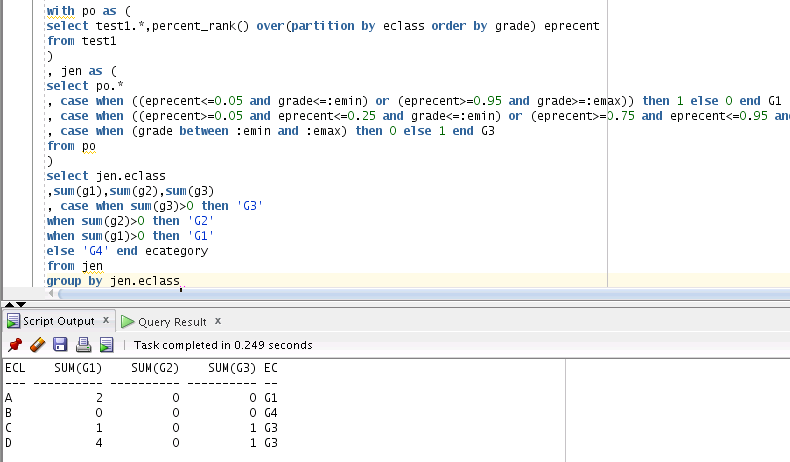
(注意除了一開始生成的測試數據, 下面三張圖片都是同一個 SQL. 只是我展示不同的片段)
