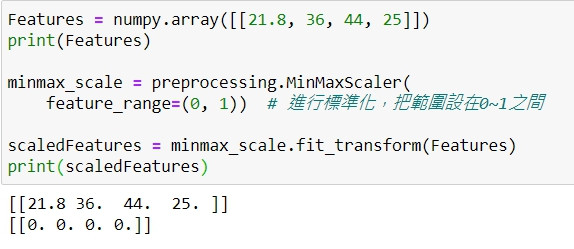
如圖,我想進行標準化,但進行完之後卻全部都變成0,想請問這是為什麼?
還是機器學習新手,所以某些問題還不是很了解請見諒。
已邀請的邦友 {{ invite_list.length }}/5
咦?
因為你只有輸入一個四維的資料,你要做的應該是下方這個圖的效果。
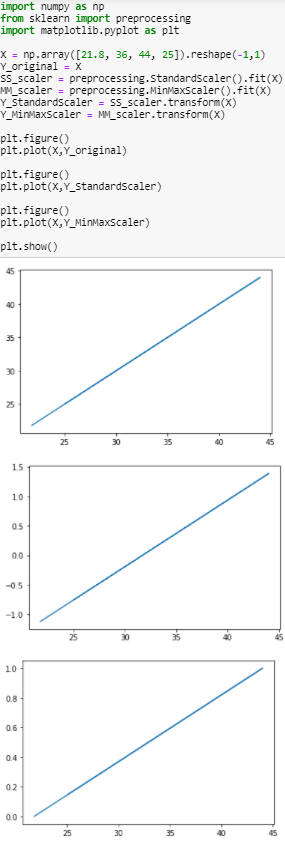
您好,因為我想讓使用者輸入一組特徵,然後用我之前儲存的模型進行預測,所以輸入的特徵我讓他先標準化,但不知為什麼跑出來會都是0
1.請問如果只有輸入一筆資料的話就無法進行標準化嗎?
2.請問您圖一的數值是經過標準化後跑出來的數值嗎? 想請問是如何做出來的?
3.請問為什麼要reshape(-1,1)?
更新了~
因為你只有輸入一個四維的資料
解決方法:預測不用標準化喔!!!
真的嗎,因為我之前都只有用原始的資料拆分成訓練跟測試,然後都有先預處理標準化,之後再拿測試資料去預測看看,所以我以為另外輸入一筆新的資料進去預測的話,也要先進行預處理標準化
1.所以我只要讓使用者輸入完資料後,拿那筆資料直接利用predict進行預測這樣就可以了嗎?
沒記錯的話,是的。待會給你正式的答案(要翻一下一年前的code)
好的,那我先不進行標準化試試看,那就麻煩您了
恩~看來是我記錯了,要用舊的標準化方法對新的資料作標準化。詳細參考這篇文章。所以說你要用舊的(訓練時)scaler進行標準化再丟到模型裡進行預測。
看完那篇參考文章後,如果需要對新資料進行標準化的話,就要把新資料+舊資料一起進行標準化之後,再把新資料從中拉出來使用原本儲存的模型進行預測這樣嗎?
用之前標準化訓練資料的scaler來標準化預測資料。
可是我這樣只有一筆新輸入的資料,這樣的話不是就無法進行標準化嗎?
等我寫個簡單的範例
from sklearn.datasets import load_breast_cancer
from sklearn import preprocessing
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
cancer = load_breast_cancer()
X = cancer.data
y = cancer.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
#為測試集建立標準化函數
scaler = preprocessing.StandardScaler().fit(X_train)
X_train = scaler.transform(X_train)
model = SVC(kernel='rbf')
model.fit(X_train, y_train)
#使用剛的標準化函數
X_test = scaler.transform(X_test)
y_pred = model.predict(X_test)
那如果我使用"model.save"儲存模型之後,在load模型出來使用,這樣我之前標準化的函數還可以使用嗎?
data 要改寫一下格式,因為原寫法代表4個特徵,只有一筆資料,因此,轉換後均為0。
from sklearn.preprocessing import MinMaxScaler
data = [[21.8], [44], [36], [25]]
scaler = MinMaxScaler()
print(scaler.fit_transform(data))

 iThome鐵人賽
iThome鐵人賽