目前在抓取ETtoday新聞裡面完整的內容
是使用BeautifulSoup和scrapy來抓取
在抓取時遇到一個問題,就是目標tag中,第一個tag底下的內容是不需要的
舉例來說,新聞內容都放在<div> class="story"底下的<p>裡面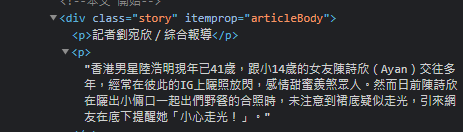
第一個<p>的內容都是 "記者XXX / XX報導" ,不是新聞內容所以不需要
想請問有沒有方法可以抓取第二個<p>(含)以後的資料?
程式碼:
import scrapy
import json
from bs4 import BeautifulSoup
class EttodayCrawler(scrapy.Spider):
name = 'ettoday'
start_urls = (['https://star.ettoday.net/news/1966296'])
def parse(self, response):
res = BeautifulSoup(response.body)
section = ""
for tag in res.select('div.story p'):
# 看底下有沒有其他 tag
children = tag.findChild()
# 沒有的話才是想要的
if children == None:
section += tag.get_text()
section += "\n"
article = {'content': section}
jsondata = json.dumps(article, ensure_ascii=False)
print(jsondata)
已邀請的邦友 {{ invite_list.length }}/5
css 解法
res.select('div.story p:not(:first-of-type)')

如果 css 你不熟,那就用 if,這方法應該最基本最萬能
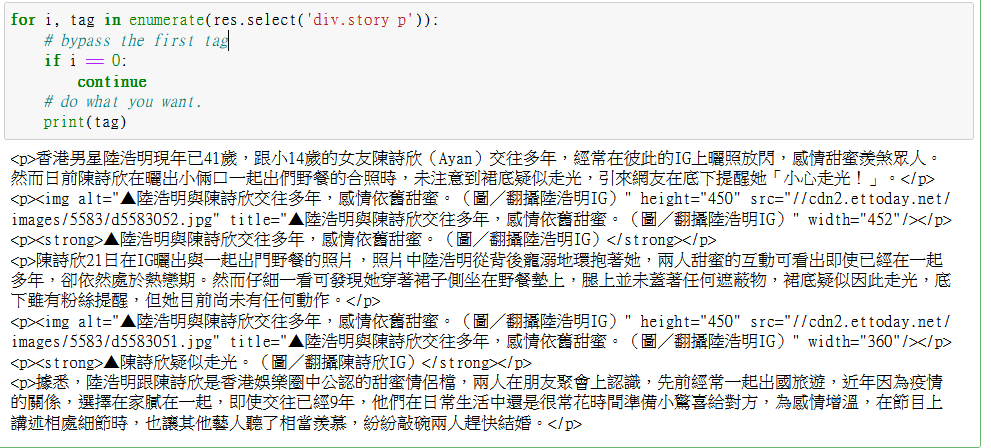
for i, tag in enumerate(res.select('div.story p')):
# bypass the first tag
if i == 0:
continue
# do what you want.
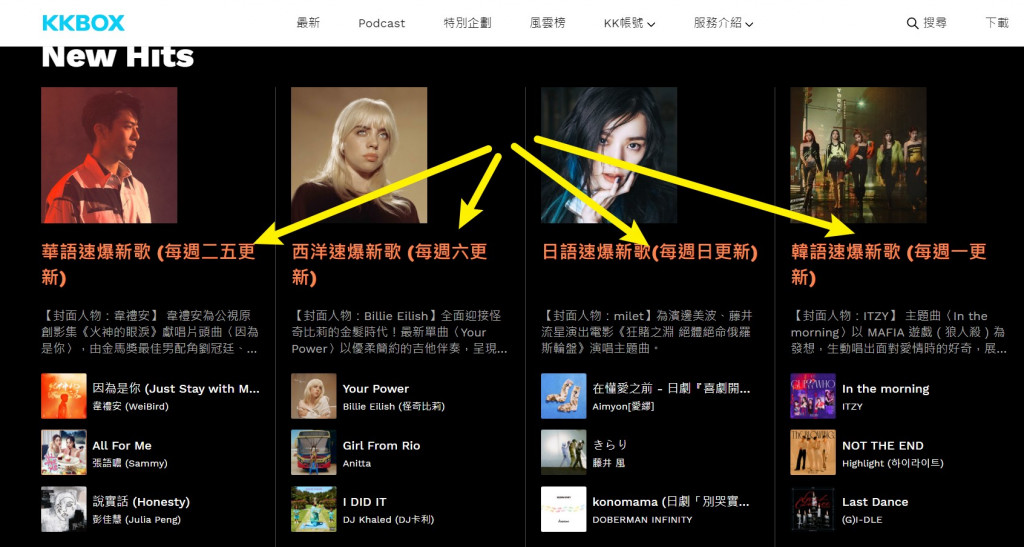
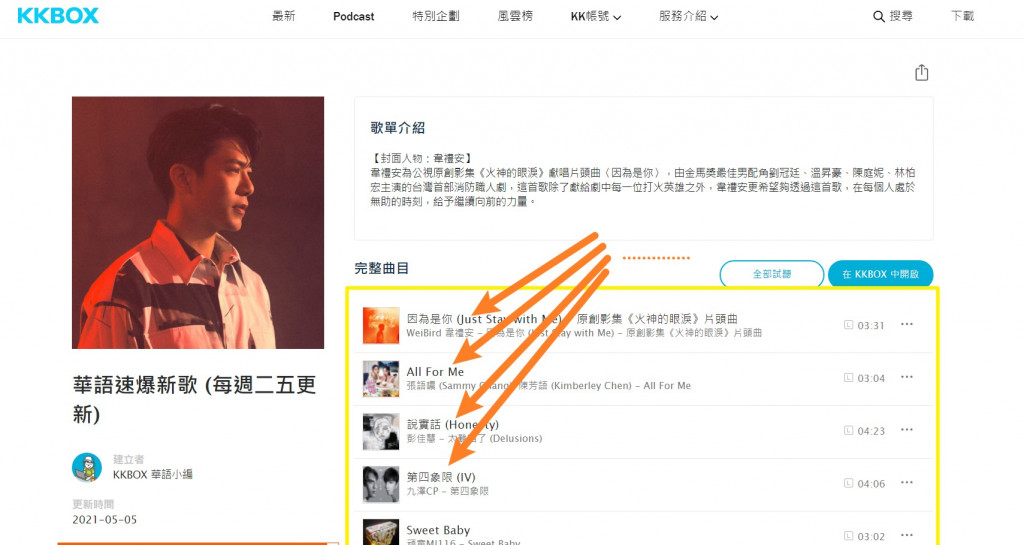
這是我用來抓KKBOX最新歌曲曲目的PYTHON,實在是懶的研究別人的原始碼(跟我的編寫喜好不同就懶),只用到requests、lxml、re,沒用到BeautifulSOAP跟selenium或更高階的套件...
被爬的網頁 https://www.kkbox.com/tw/tc/ KKBOX
僅供參考,不要用來做壞事嘿
import os
import sys
import requests
import re
import json
from lxml import html, etree
def getKKHitsLink():
# 把HTML DOM拆解抓我要的連結
SongRE = re.compile(r'\([^\)]*\)') #用regular express來摳資料
SongREB = re.compile(r'\[[^\]]*\]')
dicList = dict()
ret = list()
#抓網頁HTML
mainresp = requests.get('https://www.kkbox.com/tw/tc/')
xtree = html.fromstring(mainresp.text)
#從DOM XPATH抓,按華語、西洋、東洋、韓語
sectionHits = xtree.xpath('//div[@class="hit-card"]/div[1]/a[1]/@href')
# 如果有抓到資料,感覺有點脫褲子放屁對不對?因為有下下一行for,不好意思,這是我的習慣,怕for不到出錯誤
if len(sectionHits) > 0:
for secx in sectionHits:
DetailContent = requests.get(secx) #再去爬抓到的連結
if(len(DetailContent.text) > 500):
#怕抓到的網頁內容是401、500、或防爬
dtree = html.fromstring(DetailContent.text)
blist = list()
#下一行,用正則表達式把我要的歌名"摳"出來(放在four-more-meta的class的都是)
altext = SongRE.sub(
"", str(dtree.xpath('//div[@class="four-more-meta"][1]/img[1]/@alt'))).strip()
data = dtree.xpath('//div[@class="song-artist-album"][1]')
for d in data: #有找到
album = ""
for da in d.xpath('a/text()'):
album = album + " " + da.strip()
album = SongRE.sub("", album.strip())
album = SongREB.sub("", album)
if album not in blist: #不重覆
ret.append(album)
blist.append(album)
dicList[altext] = blist #沒忘了我有分種吧,所以這層用dict分開
return dicList
# 直接回傳dict
#如要回應json字串,則 return json.dumps(dicList, ensure_ascii=False)
剛剛的連結點進去,最下方.........就有四大新歌連結