目前在抓取udn新聞裡面完整的內容
是使用BeautifulSoup和scrapy來抓取
在抓取時遇到一個問題,就是目標tag中,有些tag底下是沒有內容的
舉例來說,新聞內容都放在<div> class="article"底下的<p>裡面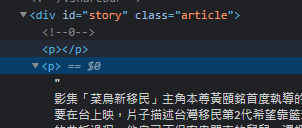
但是其中會出現像上圖中第一個tag,<p></p>這樣裡面是沒有內容的
或者是下像圖中<P>和</p>是在不同行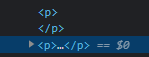
由於這樣會讓印出來的內容每個段落中間多空了2行
想請問有沒有方法可以將沒有內容的<p>去除?
執行結果:
同事整合後的執行結果:
PS: 有試過用if tag.get_text() != None:
None替換成""、"\n"、"\r"、"\r\n" ...@#$% 都不行...
用len(tag.get_text())判斷長度不等於0 也不行....replace() .strip()也沒辦法做到完全去除...
程式碼:
import scrapy
import json
from bs4 import BeautifulSoup
class UdnCrawler(scrapy.Spider):
name = 'udn'
start_urls = (['https://stars.udn.com/star/story/10091/5407836'])
def parse(self, response):
res = BeautifulSoup(response.body)
section = ""
for tag in res.select('div.article p'):
children = tag.findChild()
if children == None:
section += tag.get_text()
section += "\n"
article = {'content': section}
jsondata = json.dumps(article, ensure_ascii=False)
print(jsondata)
已邀請的邦友 {{ invite_list.length }}/5
import re
text1 = '<p> </p>';
text2 = '''<p>
</p>''';
print(text1)
print(re.sub(r'<p>\s*</p>', '', text1))
print(text2)
print(re.sub(r'<p>\s*</p>', '', text2))
用正則把空的p去掉
