目前在抓取泛新聞裡面完整的內容
是使用BeautifulSoup和requests來抓取
在排除標籤時遇到一個問題,就是將目標tag中,第一個或最後一個標籤排除時
會連帶影響到其他原本正常選取的標籤
舉例來說,新聞內容都放在<div> class="post-content-container"底下的<p>裡面
標題文字都放在<h2>底下的<strong>裡面

前面有特殊符號的文字都放在<ul>底下的<li>裡面
因為標題文字<strong>中最後一個標籤的內容 "延伸閱讀" 不是文章內容,所以要排除
使用 :not(:last-of-type) 或 :not(:nth-last-child) 排除最後一個標籤的語法section#firstSingle div.post-content-container h2 strong:not(:last-of-type)
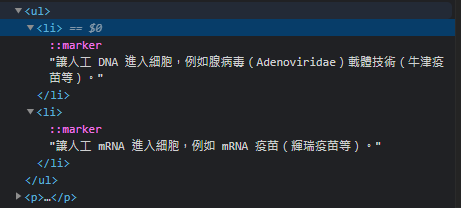
除了最後一個標籤的內容不見,中間原本抓出的標題也會不見
原:

使用後:

同理,使用 :not(:first-of-type) 或 :not(:nth-first-child) 排除第一個標籤的語法section#firstSingle div.post-content-container ul li:not(:first-of-type)
將前面含特殊符號文字<li>第一個標籤的內容 "蔣維倫 / 泛科學 PanSci 專欄作家..."
作者介紹給排除,中間會少抓一個tag的內容
原:
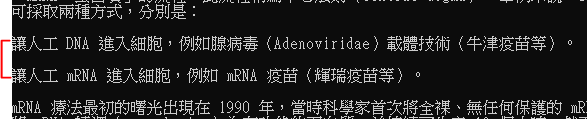
使用後:

有人知道是什麼原因嗎? 該怎麼解決?
程式碼:
import json
from bs4 import BeautifulSoup
import requests
class crawlerClass:
def __init__(self):
print("init")
def PansciCrawler(self, url):
response = requests.get(url, verify=False)
soup = BeautifulSoup(response.text, "html.parser")
section = ""
# p文章內容,h2 strong標題文字,ul li前面含特殊符號文字
for tag in soup.select('section#firstSingle div.post-content-container p:not(:nth-last-child(4)), section#firstSingle div.post-content-container h2 strong, section#firstSingle div.post-content-container ul li'):
children = tag.findChild()
if children == None:
if tag.get_text() != "":
section += tag.get_text()
section += "\n\n"
article = {'status': 0, 'content': section}
return json.dumps(article)
if __name__ == "__main__":
crawler = crawlerClass()
# ==== Pansci ====
url = "https://pansci.asia/archives/320488"
pansciJsonStr = crawler.PansciCrawler(url)
pansciContent = json.loads(pansciJsonStr, encoding="utf-8")
print("status:"+str(pansciContent['status']))
print(pansciContent['content'])
已邀請的邦友 {{ invite_list.length }}/5
section#firstSingle div.post-content-container h2 strong:not(:last-of-type)
應該為
section#firstSingle div.post-content-container h2:not(:last-of-type) strong
而
section#firstSingle div.post-content-container ul li:not(:first-of-type)
應該為
section#firstSingle div.post-content-container ul:not(:first-of-type) li
可以發現你的 pseudo class 都放錯地方,可以趁這個機會好好的了解一下 pseudo class。
