不好意思下了這麼拗口的標題><
想請問各位大大python有甚麼方法可以把下圖紅框處的部分抓前五名的數字呢?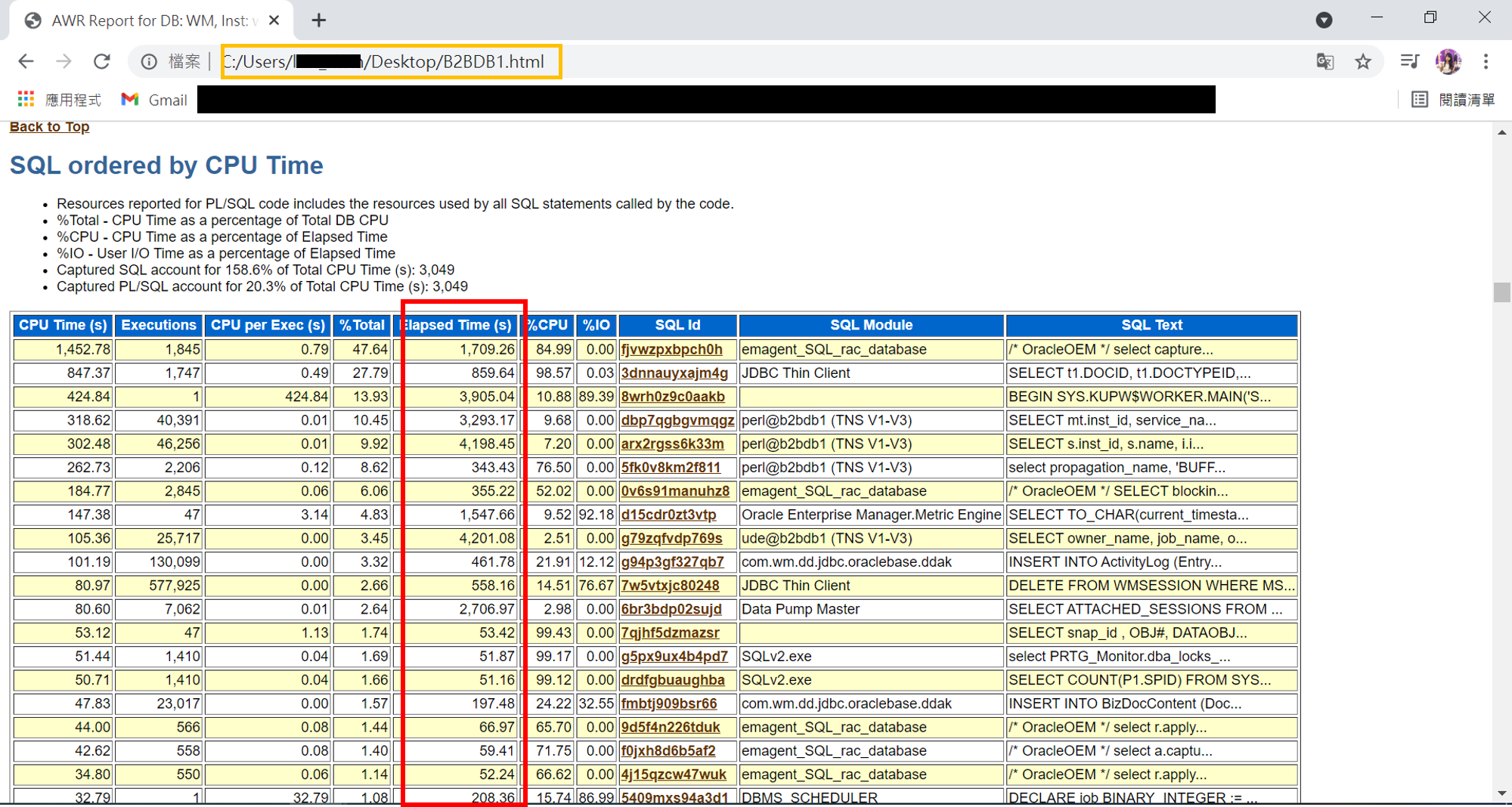
我一開始的想法是用BeautifulSoup套件將指定表格的內容爬出來
再將紅框數字部份存到陣列裡取前五名
結果不幸的事發生了
這份HTML檔案所有table的class name和格式都一樣
也完全沒有id
所以我完全沒辦法去指定我要抓的特定表格
每個table間唯一不一樣的地方只有下圖紅框處的"summary"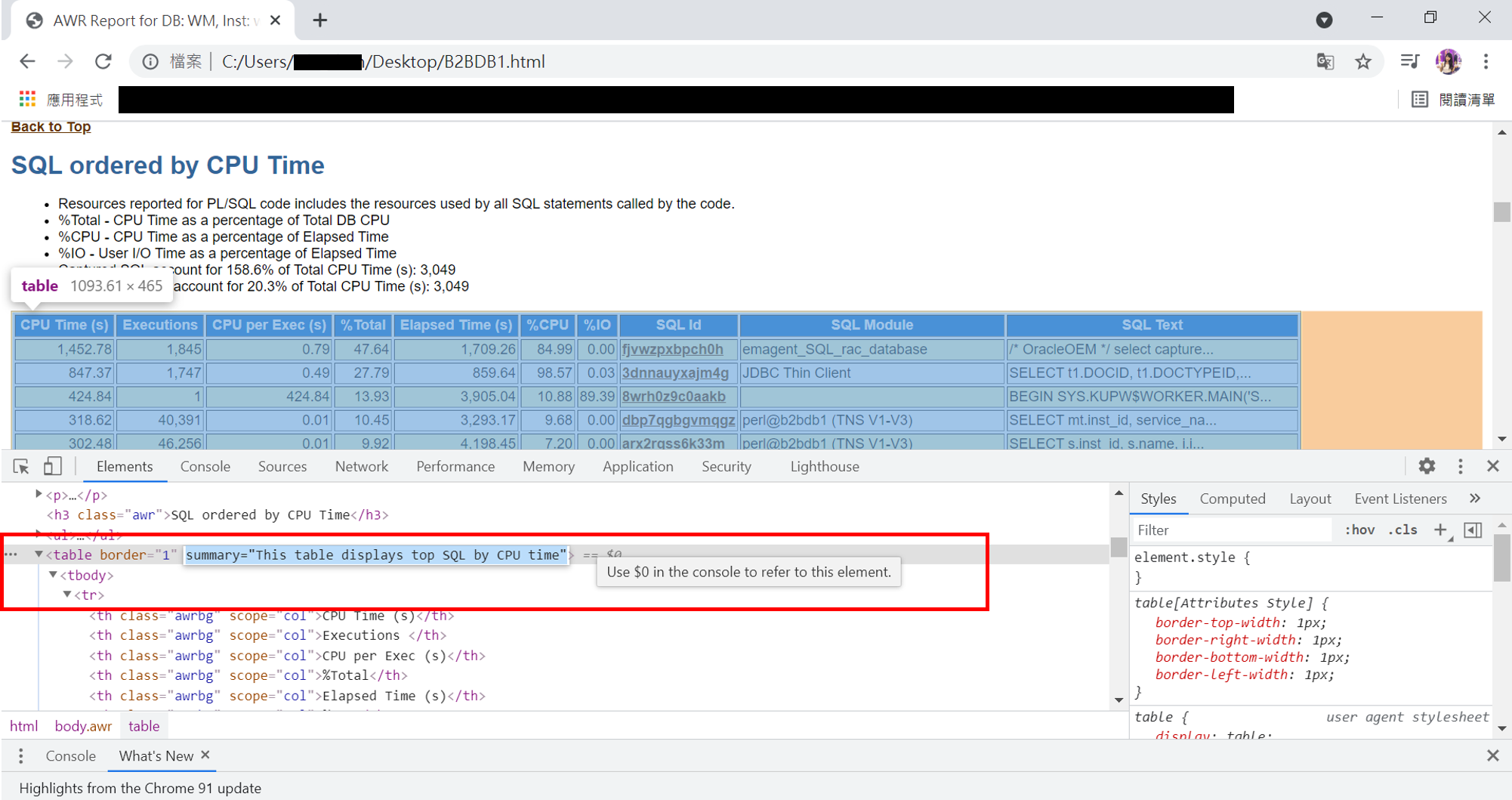
請問這種HTML是不是不能用BeautifulSoup去爬呢?
如果是的話要用甚麼方式完成比較好呢?
謝謝各位大師的幫忙!
下列連結為HTML檔案:
https://drive.google.com/file/d/1ul6c6fUaszUw3cwYHcN9rww6iOH0ptiD/view?usp=sharing
我自己目前寫的程式碼如下:
import bs4
path = './B2BDB1.html'
with open(path, 'r') as f:
soup = bs4.BeautifulSoup(f.read(), 'html.parser')
titles = soup.find_all("table")[29]
for title in titles:
print(titles)

已邀請的邦友 {{ invite_list.length }}/5
from pyquery import PyQuery as pq
import pandas as pd
html = None
with open("B2BDB1.html", "r") as f:
html = pq("".join(f.readlines()))
table = html.find('table[summary="This table displays top SQL by CPU time"]')
tabledf = pd.read_html(table.outer_html())[0]
print(tabledf.sort_values("Elapsed Time (s)", ascending=False)[:5])
這時候就是大喊pandas真好用就對了。
請參閱 : How to only get data of first table on a Wikipedia page using BeautifulSoup?
# find all table ,get the first
table = soup.find_all('table', class_="wikitable")[0] # Only use the first table
你這個報表是 AWR ordered by CPU time
建議可以改用 AWR ordered by Elapsed time
再去取前五名
就不用自己排序
參考這篇
