目前在抓取Meet創業小聚裡面完整的內容
是使用BeautifulSoup和requests來抓取
在抓取時發現,爬蟲程式標籤正確,但抓取不到內容
F12檢視元素:
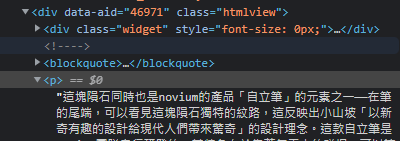
結果:
print(soup)後發現文章內容是放在別的標籤中(<script type="application/ld+json">),底下看起來是json格式某個Key的裡面("articleBody":)

請問要怎麼將文章內容從html中像是json格式的地方抓取出來,並轉成json格式輸出?
PS: 指定到該標籤,將內容印出發現不是json格式(多了第一和最後一行)
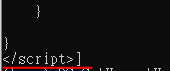
程式碼:
from bs4 import BeautifulSoup
import requests
url = 'https://meet.bnext.com.tw/articles/view/46971'
response = requests.get(url, verify=False)
soup = BeautifulSoup(response.text, "html.parser")
article = soup.select('script[type="application/ld+json"]')
article_str = str(article)
print(article_str)
已邀請的邦友 {{ invite_list.length }}/5
from bs4 import BeautifulSoup
import requests
import json;
url = 'https://meet.bnext.com.tw/articles/view/46971'
response = requests.get(url, verify=False)
soup = BeautifulSoup(response.text, "html.parser")
article = soup.select('html script[type="application/ld+json"]')[0].contents[0]
results = json.loads(article)
final = results['articleBody']
print(final)
抓出來是陣列因此添加 [0]
或是用 soup.select_one()
內容在 contents 內
加一點東西,重新把json規整後顯示
from bs4 import BeautifulSoup
import requests,re,json
url = 'https://meet.bnext.com.tw/articles/view/46971'
response = requests.get(url, verify=False)
response.encoding='utf-8' # 新加
soup = BeautifulSoup(response.text, "html.parser")
article = soup.select('script[type="application/ld+json"]')
article_str = re.sub(r"[\r\n\b]","",article[0].contents[0]) # 改
v = json.loads(article_str) # 新加
print(json.dumps(v,ensure_ascii=False)) # 新加

 iThome鐵人賽
iThome鐵人賽