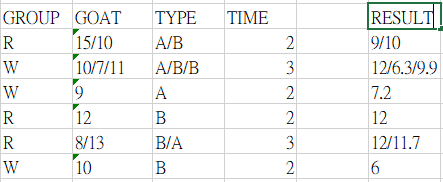
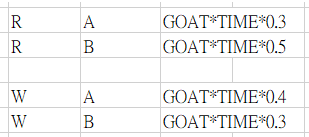
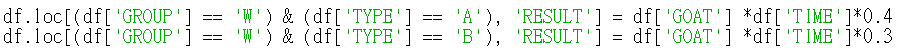我可能會有 2 種作法
不確定 pandas 是不是還有更好的方法,歡迎提供
g = "10/7/11"
t = "A/B/B"
time_val = 2
gs = g.split("/")
ts = t.split("/")
result = []
for (gi, ti) in zip(gs, ts):
if ti == "A":
ans = int(gi) * time_val * 0.3
elif ti == "B":
ans = int(gi) * time_val * 0.5
result.append(str(ans))
result_str = "/".join(result)
print(result_str)
# 6.0/7.0/11.0
import pandas as pd
df = pd.DataFrame({
"goat": ["15/10", "10/7/11"],
"type": ["A/B", "A/B/B"]
})
# 切開補空值
df[['g1', 'g2', 'g3']] = df.goat.str.split('/', expand=True)
df[['t1', 't2', 't3']] = df.type.str.split('/', expand=True)
df.fillna("", inplace=True)
# 各種合併
df['all1'] = df[['g1', 'g2', 'g3']].agg('/'.join, axis=1)
df['all2'] = df.t1.str.cat(df[['t2', 't3']], sep='/')
df['all3'] = df[['t1', 't2', 't3']].apply(lambda x: '/'.join(x), axis=1)
def addcheck(row):
st = ''
for i in range(len(row)):
if row[i] != '':
if st != '':
st += "/"
st += row[i]
return st
df['all4'] = df[['t1', 't2', 't3']].apply(addcheck, axis=1)
print(df)
goat type g1 g2 g3 t1 t2 t3 all1 all2 all3 all4
0 15/10 A/B 15 10 A B 15/10/ A/B/ A/B/ A/B
1 10/7/11 A/B/B 10 7 11 A B B 10/7/11 A/B/B A/B/B A/B/B
提供一個不是很 python 的寫法
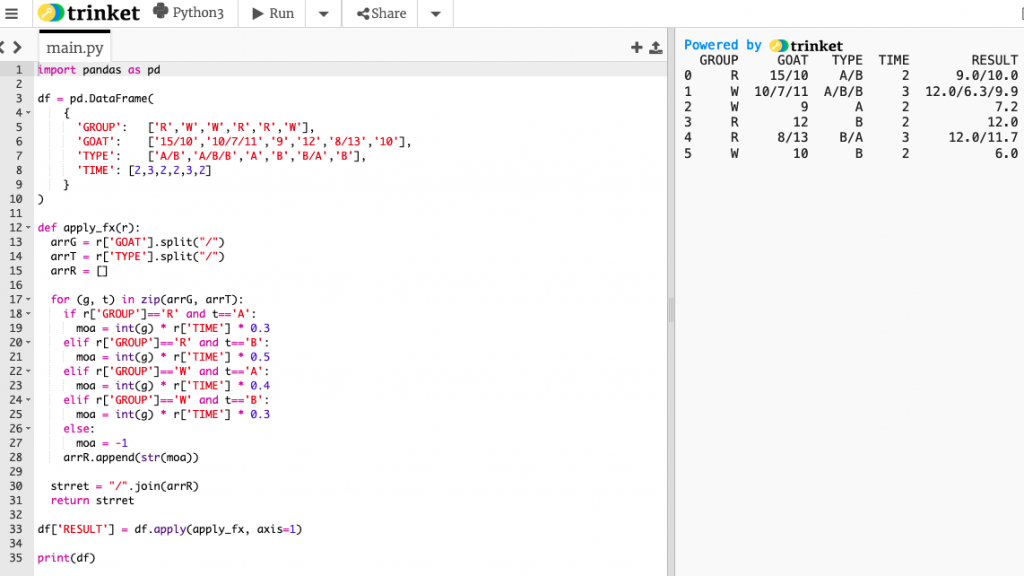
import pandas as pd
df = pd.DataFrame(
{
'GROUP': ['R','W','W','R','R','W'],
'GOAT': ['15/10','10/7/11','9','12','8/13','10'],
'TYPE': ['A/B','A/B/B','A','B','B/A','B'],
'TIME': [2,3,2,2,3,2]
}
)
def apply_fx(r):
arrG = r['GOAT'].split("/")
arrT = r['TYPE'].split("/")
arrR = []
for (g, t) in zip(arrG, arrT):
if r['GROUP']=='R' and t=='A':
moa = int(g) * r['TIME'] * 0.3
elif r['GROUP']=='R' and t=='B':
moa = int(g) * r['TIME'] * 0.5
elif r['GROUP']=='W' and t=='A':
moa = int(g) * r['TIME'] * 0.4
elif r['GROUP']=='W' and t=='B':
moa = int(g) * r['TIME'] * 0.3
else:
moa = -1
arrR.append(str(moa))
strret = "/".join(arrR)
return strret
df['RESULT'] = df.apply(apply_fx, axis=1)
print(df)
雖然有前輩早就提供解答了,
但還是想試著自己寫看看。
平常沒有很常寫程式,一些語法也不熟。
斷斷續續利用有閒的時間嘗試,總算也解出來了!!
import pandas as pd
import numpy as np
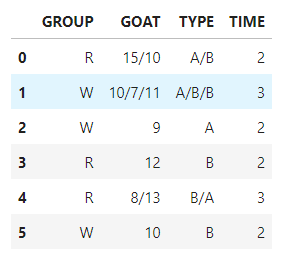
df = pd.DataFrame(
{
'GROUP': ['R','W','W','R','R','W'],
'GOAT': ['15/10','10/7/11','9','12','8/13','10'],
'TYPE': ['A/B','A/B/B','A','B','B/A','B'],
'TIME': [2,3,2,2,3,2]
}
)
df
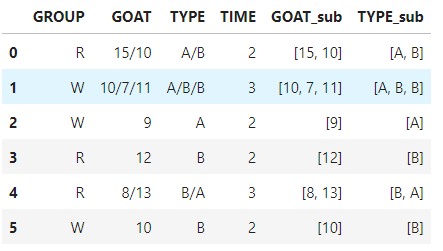
df_temp = df.copy()
df_temp['GOAT_sub'] = df_temp['GOAT'].str.split('/').tolist()
df_temp['TYPE_sub'] = df_temp['TYPE'].str.split('/').tolist()
df_temp
# 設定solution來存最後結果
solution = []
for i in range(len(df_temp)):
#設定temp_RESULT來存暫時的結果
temp_RESULT = []
for j in range(len(df_temp['TYPE_sub'][i])):
if ((df_temp['GROUP'][i] == 'R') & (df_temp['TYPE_sub'][i][j] == 'A')):
df_temp['temp'+str(j)] = int(df_temp['GOAT_sub'][i][j])*df_temp['TIME'][i]*0.3
elif ((df_temp['GROUP'][i] == 'R') & (df_temp['TYPE_sub'][i][j] == 'B')):
df_temp['temp'+str(j)] = int(df_temp['GOAT_sub'][i][j])*df_temp['TIME'][i]*0.5
elif ((df_temp['GROUP'][i] == 'W') & (df_temp['TYPE_sub'][i][j] == 'A')):
df_temp['temp'+str(j)] = int(df_temp['GOAT_sub'][i][j])*df_temp['TIME'][i]*0.4
elif ((df_temp['GROUP'][i] == 'W') & (df_temp['TYPE_sub'][i][j] == 'B')):
df_temp['temp'+str(j)] = int(df_temp['GOAT_sub'][i][j])*df_temp['TIME'][i]*0.3
L = str(df_temp['temp'+str(j)][0])
temp_RESULT.append(L)
temp_RESULT = '/'.join(temp_RESULT)
solution.append(temp_RESULT)
print(temp_RESULT)
solution

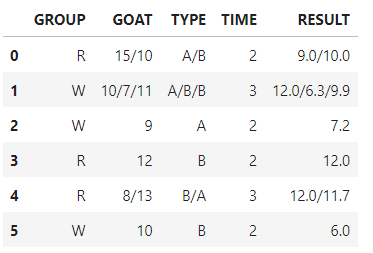
df['RESULT'] = solution
df
##另一種寫法:
import pandas as pd
import numpy as np
df = pd.DataFrame(
{
'GROUP': ['R','W','W','R','R','W'],
'GOAT': ['15/10','10/7/11','9','12','8/13','10'],
'TYPE': ['A/B','A/B/B','A','B','B/A','B'],
'TIME': [2,3,2,2,3,2]
}
)
go = df['GOAT'].str.split('/')
ty = df['TYPE'].str.split('/')
co = range(len(df))
result = []
for a, b, c in zip(go, ty, co):
re = []
for i in range(len(b)):
gr = df['GROUP'][c]
ti = df['TIME'][c]
if ((gr == 'R') & (b[i] == 'A')):
r = int(a[i])*int(ti)*0.3
elif ((gr == 'R') & (b[i] == 'B')):
r = int(a[i])*int(ti)*0.5
elif ((gr == 'W') & (b[i] == 'A')):
r = int(a[i])*int(ti)*0.4
elif ((gr == 'W') & (b[i] == 'B')):
r = int(a[i])*int(ti)*0.3
li = str(r)
re.append(li)
#print(a[i], b[i], gr, ti, r)
#print('/'.join(re))
result.append('/'.join(re))
df['RESULT'] = result
df