這是我們要做專題所需要用到的資料
資料部分是用kaggle
2022_boston_gov_opendata : https://data.boston.gov/dataset/food-establishment-inspections/resource/4582bec6-2b4f-4f9e-bc55-cbaa73117f4c
因為檔案有6G多所以這邊先將前100筆放進list裡
import json
path = "yelp_academic_dataset_review.json"
reviewList = []
i = 0
with open(path, 'r', encoding='utf-8') as f:
try:
while i<100:
line_data = f.readline()
if line_data:
data = json.loads(line_data)
reviewList.append(data)
i+=1
else:
break
except Exception as e:
print(e)
f.close()
reviewList[:3]
可以得到資料結構大概是
[{'review_id': 'lWC-xP3rd6obsecCYsGZRg',
'user_id': 'ak0TdVmGKo4pwqdJSTLwWw',
'business_id': 'buF9druCkbuXLX526sGELQ',
'stars': 4.0,
'useful': 3,
'funny': 1,
'cool': 1,
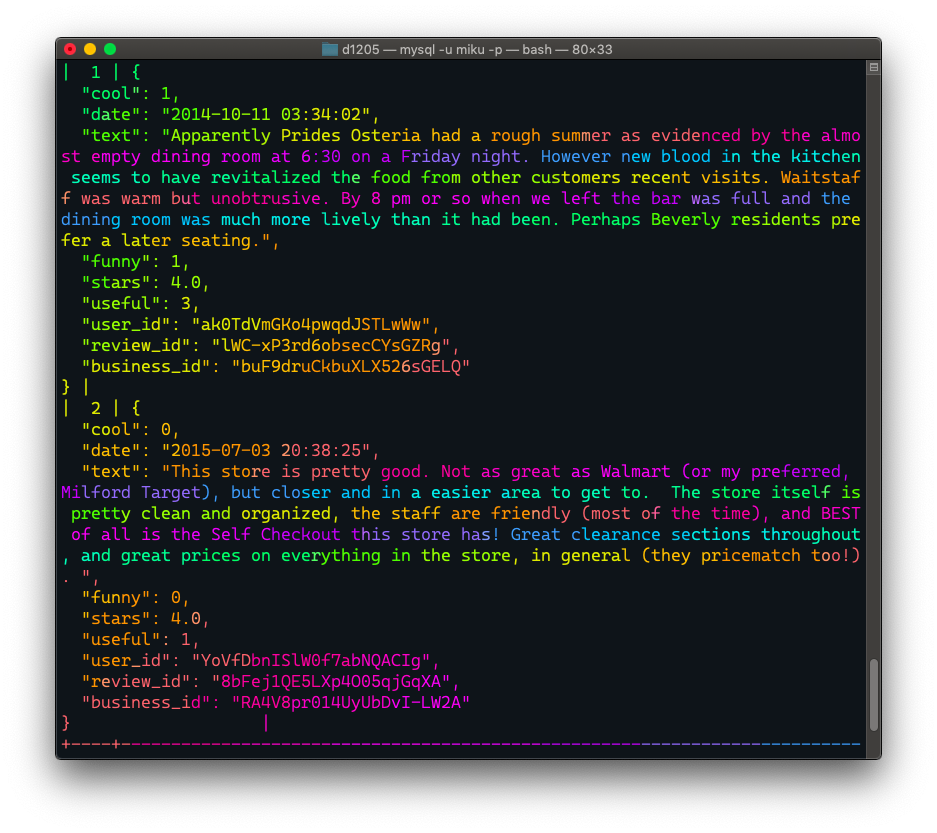
'text': "Apparently Prides Osteria had a rough summer as evidenced by the almost empty dining room at 6:30 on a Friday night. However new blood in the kitchen seems to have revitalized the food from other customers recent visits. Waitstaff was warm but unobtrusive. By 8 pm or so when we left the bar was full and the dining room was much more lively than it had been. Perhaps Beverly residents prefer a later seating.",
'date': '2014-10-11 03:34:02'},
{'review_id': '8bFej1QE5LXp4O05qjGqXA',
'user_id': 'YoVfDbnISlW0f7abNQACIg',
'business_id': 'RA4V8pr014UyUbDvI-LW2A',
'stars': 4.0,
'useful': 1,
'funny': 0,
'cool': 0,
'text': 'This store is pretty good. Not as great as Walmart (or my preferred, Milford Target), but closer and in a easier area to get to. \nThe store itself is pretty clean and organized, the staff are friendly (most of the time), and BEST of all is the Self Checkout this store has! \nGreat clearance sections throughout, and great prices on everything in the store, in general (they pricematch too!). ',
'date': '2015-07-03 20:38:25'}]
目前想用類似這樣的方式,做for迴圈
reviewList[55]['review_id']
單筆打印是成功的
'z-6ElnK3yXpn2oNKR7NYtw'
但是想把每列排進去就開始抱錯!
s="review_id,user_id,business_id,stars,useful,funny,cool,text,date\n"
for i in reviewList:
s=s+"{},{},{},{},{},{},{},{},{}\n".format(reviewList[i]['review_id'],reviewList[i]['user_id'],reviewList[i]['business_id'],reviewList[i]['stars'],reviewList[i]['useful'],reviewList[i]['funny'],reviewList[i]['cool'],reviewList[i]['text'],reviewList[i]['date'])
(這部分)出現下方錯誤
TypeError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_15668/4124199551.py in <module>
3 #list2=list(dict())
4 #print(list2)
----> 5 s=s+"{},{},{},{},{},{},{},{},{}\n".format(reviewList[i]['review_id'],reviewList[i]['user_id'],reviewList[i]['business_id'],reviewList[i]['stars'],reviewList[i]['useful'],reviewList[i]['funny'],reviewList[i]['cool'],reviewList[i]['text'],reviewList[i]['date'])
TypeError: list indices must be integers or slices, not dict
改成for i in range(len(reviewList)):以解決
最後存成csv
fw=open("review.csv","w", encoding='utf-8')
fw.write(s)
fw.close()
但發現檔案輸出結果不是我要的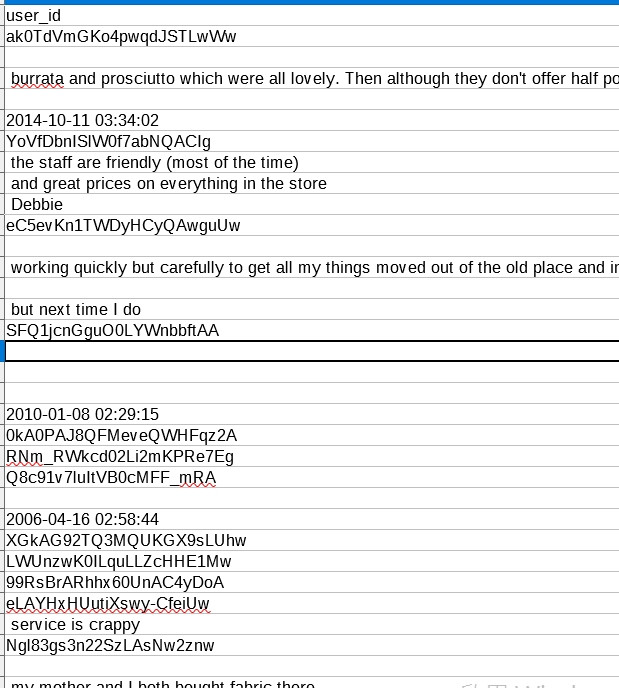
原因是text的欄位出現許多\n換行符號,
'text': 'This store is pretty good. Not as great as Walmart (or my preferred, Milford Target), but closer and in a easier area to get to. \nThe store itself is pretty clean and organized, the staff are friendly (most of the time), and BEST of all is the Self Checkout this store has! \nGreat clearance sections throughout, and great prices on everything in the store, in general (they pricematch too!). '
導致檔案欄位沒有對齊,想請問如何解決這個問題,先說謝謝,感謝
已邀請的邦友 {{ invite_list.length }}/5
關鍵的問題是:CSV 是要給「誰」用?
json 已經是用來交換資料的格式
能直接用是最好
如果硬要轉成 CSV
你的資料有兩個特殊字元要處理
1.換列(\n)
2.逗號
以下是我的處理方式
1.換列(\n):一律用空白字元取代
2.逗號:text 欄位前後加 double quote
如果這處理方式你能接受
以下是所有資料及程式
yelp_academic_dataset_review.json
{"review_id": "lWC-xP3rd6obsecCYsGZRg","user_id": "ak0TdVmGKo4pwqdJSTLwWw","business_id": "buF9druCkbuXLX526sGELQ","stars": 4.0,"useful": 3,"funny": 1,"cool": 1,"text": "Apparently Prides Osteria had a rough summer as evidenced by the almost empty dining room at 6:30 on a Friday night. However new blood in the kitchen seems to have revitalized the food from other customers recent visits. Waitstaff was warm but unobtrusive. By 8 pm or so when we left the bar was full and the dining room was much more lively than it had been. Perhaps Beverly residents prefer a later seating.","date": "2014-10-11 03:34:02"}
{"review_id": "8bFej1QE5LXp4O05qjGqXA","user_id": "YoVfDbnISlW0f7abNQACIg","business_id": "RA4V8pr014UyUbDvI-LW2A","stars": 4.0,"useful": 1,"funny": 0,"cool": 0,"text": "This store is pretty good. Not as great as Walmart (or my preferred, Milford Target), but closer and in a easier area to get to. \nThe store itself is pretty clean and organized, the staff are friendly (most of the time), and BEST of all is the Self Checkout this store has! \nGreat clearance sections throughout, and great prices on everything in the store, in general (they pricematch too!). ","date": "2015-07-03 20:38:25"}
python code
import csv
import json
path = "yelp_academic_dataset_review.json"
reviewList = []
i = 0
with open(path, "r", encoding="utf-8") as f:
try:
while i<100:
line_data = f.readline()
if line_data:
data = json.loads(line_data)
reviewList.append(data)
i+=1
else:
break
except Exception as e:
print(e)
f.close()
#print(reviewList)
s="review_id,user_id,business_id,stars,useful,funny,cool,text,date\n"
for i in range(len(reviewList)):
s=s+"{},{},{},{},{},{},{},\"{}\",{}\n".format(reviewList[i]['review_id'],reviewList[i]['user_id'],reviewList[i]['business_id'],reviewList[i]['stars'],reviewList[i]['useful'],reviewList[i]['funny'],reviewList[i]['cool'],reviewList[i]['text'].replace('\n',' '),reviewList[i]['date'])
fw=open("review.csv","w", encoding="utf-8")
fw.write(s)
fw.close()
with open('review.csv', newline='') as csvfile:
rows = csv.reader(csvfile)
for row in rows:
print(row)
review.csv
review_id,user_id,business_id,stars,useful,funny,cool,text,date
lWC-xP3rd6obsecCYsGZRg,ak0TdVmGKo4pwqdJSTLwWw,buF9druCkbuXLX526sGELQ,4.0,3,1,1,"Apparently Prides Osteria had a rough summer as evidenced by the almost empty dining room at 6:30 on a Friday night. However new blood in the kitchen seems to have revitalized the food from other customers recent visits. Waitstaff was warm but unobtrusive. By 8 pm or so when we left the bar was full and the dining room was much more lively than it had been. Perhaps Beverly residents prefer a later seating.",2014-10-11 03:34:02
8bFej1QE5LXp4O05qjGqXA,YoVfDbnISlW0f7abNQACIg,RA4V8pr014UyUbDvI-LW2A,4.0,1,0,0,"This store is pretty good. Not as great as Walmart (or my preferred, Milford Target), but closer and in a easier area to get to. The store itself is pretty clean and organized, the staff are friendly (most of the time), and BEST of all is the Self Checkout this store has! Great clearance sections throughout, and great prices on everything in the store, in general (they pricematch too!). ",2015-07-03 20:38:25
最後用 python 讀回 review.csv
['lWC-xP3rd6obsecCYsGZRg', 'ak0TdVmGKo4pwqdJSTLwWw', 'buF9druCkbuXLX526sGELQ', '4.0', '3', '1', '1', 'Apparently Prides Osteria had a rough summer as evidenced by the almost empty dining room at 6:30 on a Friday night. However new blood in the kitchen seems to have revitalized the food from other customers recent visits. Waitstaff was warm but unobtrusive. By 8 pm or so when we left the bar was full and the dining room was much more lively than it had been. Perhaps Beverly residents prefer a later seating.', '2014-10-11 03:34:02']
['8bFej1QE5LXp4O05qjGqXA', 'YoVfDbnISlW0f7abNQACIg', 'RA4V8pr014UyUbDvI-LW2A', '4.0', '1', '0', '0', 'This store is pretty good. Not as great as Walmart (or my preferred, Milford Target), but closer and in a easier area to get to. The store itself is pretty clean and organized, the staff are friendly (most of the time), and BEST of all is the Self Checkout this store has! Great clearance sections throughout, and great prices on everything in the store, in general (they pricematch too!). ', '2015-07-03 20:38:25']
借用海綿寶寶的json, 建立一個檔案,放到 /tmp 下.
這時候可以使用 sed, 或是 tr 將 \n \r 取代為 ' '.
或是先不做.再來是MySQL的例子.
create table it1205a (
id int unsigned auto_increment primary key
, info text
);
LOAD DATA INFILE '/tmp/dataset_review.json' INTO TABLE it1205a(info);
update it1205a
set info = REPLACE(REPLACE(info, '\r', ''), '\n', '');
-- 若在之前已經取代了\n \r , 其實是可以直接load 進 json
alter table it1205a
add column js json;
update it1205a
set js = cast(info as JSON);
select id
, json_pretty(js)
from it1205a;