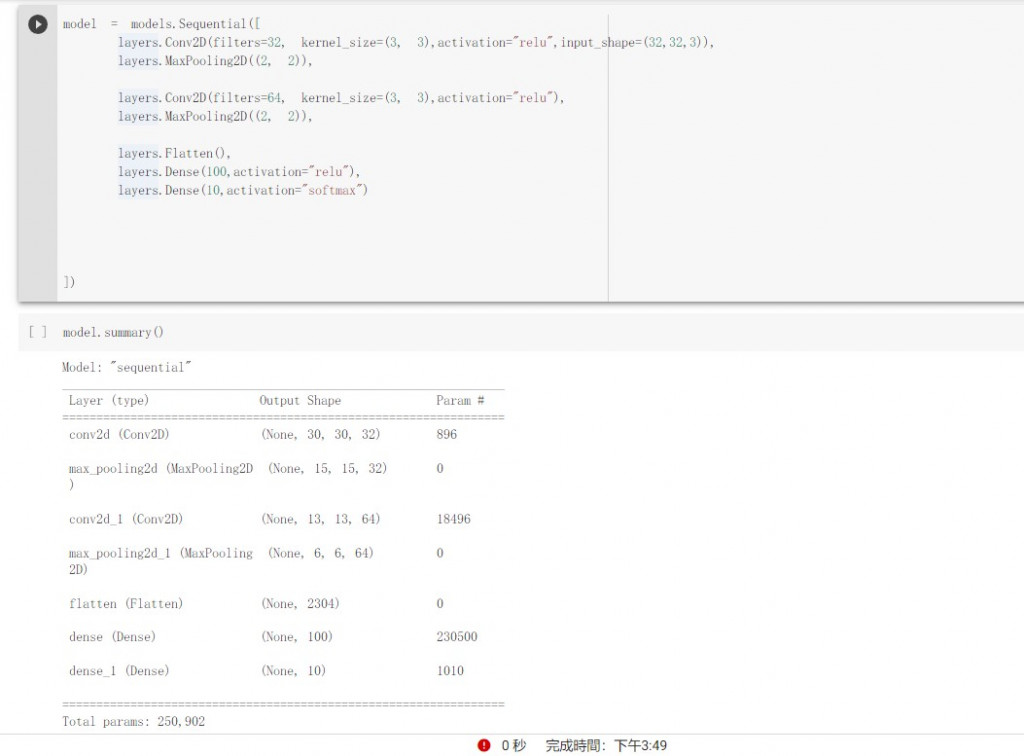
建立模型這裡開始並沒有錯
model = models.Sequential([
layers.Conv2D(filters=32, kernel_size=(3, 3),activation="relu",input_shape=(32,32,3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(filters=64, kernel_size=(3, 3),activation="relu"),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dense(100,activation="relu"),
layers.Dense(10,activation="softmax")
])
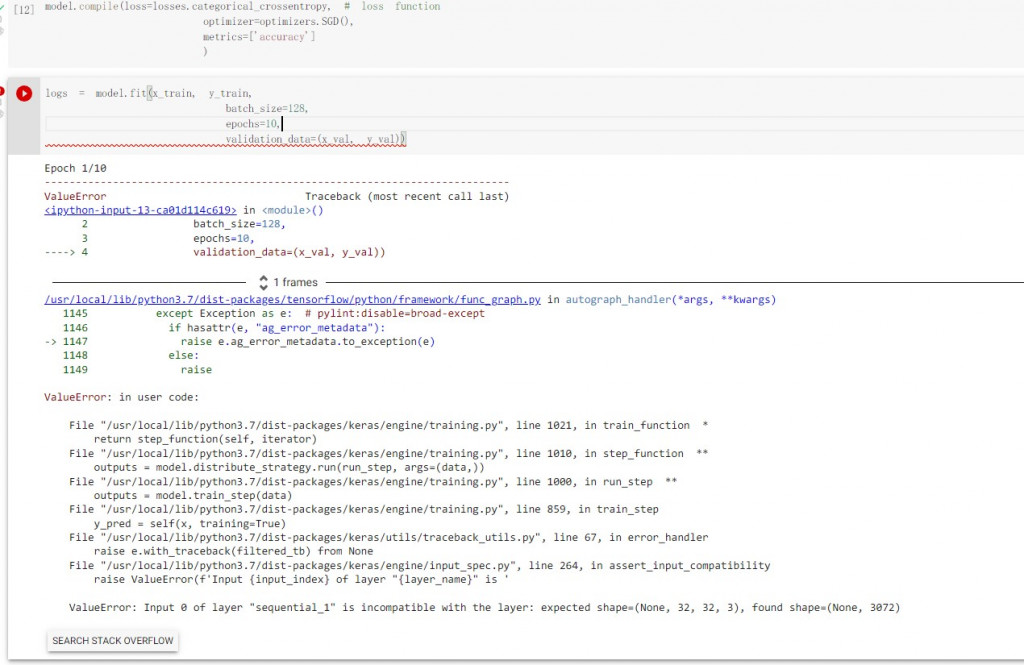
再來到Training的地方就錯了,請問該如何修改
model.compile(loss=losses.categorical_crossentropy,
optimizer=optimizers.SGD(),
metrics=['accuracy']
)
下面這步就錯了
logs = model.fit(x_train, y_train,
batch_size=128,
epochs=10,
validation_data=(x_val, y_val))
再來後面的也提供給大家不知道後面的還有沒有錯誤
history = logs.history
print(history)
plt.plot(history['accuracy'])
plt.plot(history['val_accuracy'])
plt.legend(['accuracy', 'val_accuracy'])
plt.title('accuracy')
max_acc = np.max(history['val_accuracy'])
print(max_acc)
plt.plot(history['loss'])
plt.plot(history['val_loss'])
plt.legend(['loss', 'val_loss'])
plt.title('loss')
min_loss = np.min(history['val_loss'])
print(min_loss)
df = pd.DataFrame()
df['Id'] = [str(i) for i in range(len(x_test))]
predictions = model.predict(x_test)
predictions = np.argmax(predictions, axis=-1)
df['Category'] = predictions
df.to_csv('result.csv', index=None)
df
麻煩大家可以幫忙看看要怎麼修改才能做到最後,並存成一個csv檔
已邀請的邦友 {{ invite_list.length }}/5

input 錯了喔
設定(32,32,3),結果進去的是(3072)
==
更新最後驗證狀況
x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size=0.2)
# 1. 加入 onehot 轉換
y_train = tf.keras.utils.to_categorical(y_train)
y_val = tf.keras.utils.to_categorical(y_val)
# ====
# 其他維持不動
model = models.Sequential([
layers.Conv2D(filters=32, kernel_size=(3, 3),activation="relu",input_shape=(32,32,3)),
# 中間依原本設計,說明原因故刪除
# 2. 最後是分類數,所以需為10
layers.Dense(10,activation="softmax")
])
這樣就可以訓練了

那請問需要哪裡做處理,建立模型前面的CODE要提供給你看看嗎?
你可以確認 x_train、x_val 單個資料的shape是不是(32,32,3)
我看好像沒有錯,還是我漏看了
import tensorflow as tf
from tensorflow.keras import datasets, models, layers, utils, activations, losses, optimizers, metrics
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
tf.__version__
num_classes = 10
img_size = 32
!gdown --id '1RaH2V6FdhBxjUbREJMY2SdLS-O_Qhkq7' --output cifar10.npz
with np.load('cifar10.npz', allow_pickle=True) as f:
x_train, y_train = f['x_train'], f['y_train']
x_test = f['x_test']
x_train.shape, y_train.shape, x_test.shape

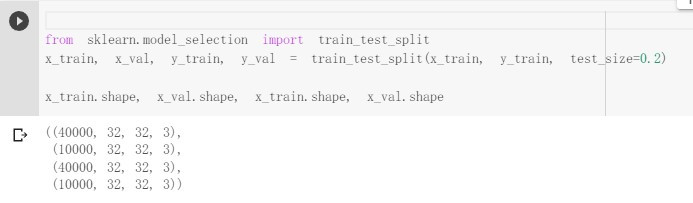
from sklearn.model_selection import train_test_split
x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size=0.2)
x_train.shape, x_val.shape, x_train.shape, x_val.shape
再來就是建立模型了
以你截出來的shape,看起來是沒什麼問題
就要看你中間是否有再處理到什麼數值,導致變成(3072)了
剛發現 3072 是 32x32x3 降到 1維
model = models.Sequential([
layers.Conv2D(filters=32, kernel_size=(3, 3),activation="relu",input_shape=(32,32,3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(filters=64, kernel_size=(3, 3),activation="relu"),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dense(100,activation="relu"),
layers.Dense(10,activation="softmax")
])
只有這裡的layers.Dense(100,activation="relu"), layers.Dense(10,activation="softmax")
100跟10有換過,我試過數值換成10跟20
出現
` ValueError: Shapes (None, 1) and (None, 20) are incompatible`
會是這關西嗎?
最後一層是你的分類數,以這個資料集是10類來說要設定10
看是否是 label 未轉換的問題,把 label 轉 onehot
y_train = tf.keras.utils.to_categorical(y_train)
y_val = tf.keras.utils.to_categorical(y_val)
還是說我提供全部的code,給您看看,因為留言這樣感覺有點亂掉了
import tensorflow as tf
from tensorflow.keras import datasets, models, layers, utils, activations, losses, optimizers, metrics
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
tf.__version__
num_classes = 10
img_size = 32
!gdown --id '1RaH2V6FdhBxjUbREJMY2SdLS-O_Qhkq7' --output cifar10.npz
with np.load('cifar10.npz', allow_pickle=True) as f:
x_train, y_train = f['x_train'], f['y_train']
x_test = f['x_test']
x_train.shape, y_train.shape, x_test.shape
from sklearn.model_selection import train_test_split
x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size=0.2)
x_train.shape, x_val.shape, x_train.shape, x_val.shape
model = models.Sequential([
layers.Conv2D(filters=32, kernel_size=(3, 3),activation="relu",input_shape=(32,32,3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(filters=64, kernel_size=(3, 3),activation="relu"),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dense(10,activation="relu"),
layers.Dense(20,activation="softmax")
])
model.compile(loss=losses.categorical_crossentropy,
optimizer=optimizers.SGD(),
metrics=['accuracy']
)
logs = model.fit(x_train, y_train,
batch_size=128,
epochs=10)
#validation_data=(x_val, y_val))
history = logs.history
print(history)
plt.plot(history['accuracy'])
plt.plot(history['val_accuracy'])
plt.legend(['accuracy', 'val_accuracy'])
plt.title('accuracy')
max_acc = np.max(history['val_accuracy'])
print(max_acc)
plt.plot(history['loss'])
plt.plot(history['val_loss'])
plt.legend(['loss', 'val_loss'])
plt.title('loss')
min_loss = np.min(history['val_loss'])
print(min_loss)
df = pd.DataFrame()
df['Id'] = [str(i) for i in range(len(x_test))]
predictions = model.predict(x_test)
predictions = np.argmax(predictions, axis=-1)
df['Category'] = predictions
df.to_csv('result.csv', index=None)
df
這是全部了,如有時間願意的話再請幫幫忙,感謝,我實在是找不出問題
x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size=0.2)
# 1. 加入 onehot 轉換
y_train = tf.keras.utils.to_categorical(y_train)
y_val = tf.keras.utils.to_categorical(y_val)
# ====
# 其他維持不動
model = models.Sequential([
layers.Conv2D(filters=32, kernel_size=(3, 3),activation="relu",input_shape=(32,32,3)),
# 中間依原本設計,說明原因故刪除
# 2. 最後是分類數,所以需為10
layers.Dense(10,activation="softmax")
])
這樣就可以跑了喔
後續的 plt 和 df 我沒確認
感謝
